






前言
前段时间抢茅台脚本非常火,它是 Python 脚本,加上刚好最近在学习 Python,我们准备通过这个脚本,来加深学习 Python。
抢茅台的脚本其实属于爬虫脚本的一类,它实现了模拟登陆,模拟访问并抓取数据。于是我们从爬虫开始来学习 Python 做项目。从这篇开始记录下爬虫相关的笔记和知识点。
正文
什么是爬虫
到底什么是爬虫?你可以理解为爬虫是互联网上的一只蜘蛛,如果遇到一些网络数据或资源,这只“蜘蛛”可以把这些数据和资源爬取下来。
官方地讲,爬虫是请求网站并提取数据的自动化程序。
使用茅台脚本来举例,脚本程序实现模拟登陆京东账号,保存登陆信息,也实现访问商品-茅台,并且帮你抢购商品,成功下订单等等。这类似于你打开京东网站登陆账号密码,浏览商品并下单的操作,脚本将这些操作都实现,形成一个自动化的程序。

爬虫分类
通用爬虫
通用网络爬虫是捜索引擎抓取系统(Baidu、Google、Yahoo 等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
比如你发布的网站,需要给搜索引擎(百度)爬取过,才能在对应的搜索引擎(baidu)上搜索到。
聚焦爬虫
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
抢购脚本就是这种“面向特定主题需求”的爬虫程序。而我们主要学习的也是这样的爬虫程序。
爬虫程序的工作模式
说实话,写爬虫程序最难的不是码代码,最难的要熟悉被爬网站的业务逻辑,了解网络请求的链接,需要的参数,反爬的处理等等。
对被爬网站的抓包分析我们后面再说,这里主要讲一般的爬虫程序的工作逻辑。
基本流程
发起请求:爬虫程序首先都会向目标链接发起请求,获取想要的数据。
比如抢购脚本,请求茅台链接的处理:
logger.info('访问商品的抢购连接...')
headers = {
'User-Agent': self.user_agent,
'Host': 'marathon.jd.com',
'Referer': 'https://item.jd.com/{}.html'.format(self.sku_id),
}
self.session.get(
url=self.seckill_url.get(
self.sku_id),
headers=headers,
allow_redirects=False)
发起请求前,需要组装好访问的 headers,目的是模拟浏览器访问。访问目标链接,还要带上必须的参数,比如商品 ID。
常用的请求方法是 GET 和 POST
- GET: 参数一般放在链接上,我们在浏览器上输入链接访问,就是 GET 方法。
- POST: 参数一般放在请求方法上,不会暴露,而且 POST 方法能携带的数据量比较大,比 GET方法安全。常用在登陆,下订单等敏感操作上。
获取相应内容:发起请求后,服务器那边会根据请求的参数,返回对应商品的数据。
比如我们打开茅台商品的页面,会有一个状态码
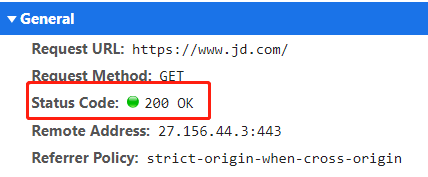
我们可以根据这个状态码来判断,是成功的还是失败的。
常见的状态码有以下几种:
200 成功响应
3xx:跳转使用
404:找不到资源
500以上:服务器错误
解析内容:我们拿到服务器返回的商品数据,可以提取响应的数据,但是需要怎么提取呢?
一般网站返回的数据有几种:
- json 格式的机构化数据
```
{"code":0,"whwswswws":"jM92rBfD0JFPpdmhM5FyRAw==","openall":1,"openalltouch":1,"processtype":1}
```
- HTML 数据
```
<a target="blank" class="catemenu_lk" href="//channel.jd.com/home.html">家居</a>
<span class="catemenuline">/</span>
<a target="blank" class="catemenu_lk" href="//channel.jd.com/furniture.html">家具</a>
<span class="catemenuline">/</span>
<a target="blank" class="catemenu_lk" href="//jzjc.jd.com/">家装</a>
<span class="catemenuline">/</span>
<a target="blank" class="catemenu_lk" href="//channel.jd.com/kitchenware.html">厨具</a>
</li>
<li class="catemenuitem" data-index="5" clstag="h|keycount|head|category_05a">
```
- 图片,视频等二进制数据
我们需要根据不同的数据,做不一样的解析,这里最方便的是 json 数据,它是结构化的,容易解析。
不过网站一般都是返回 HTML 数据,我们就需要通过一些 Python 库来解析了。
一般解析的方法有几种:
1.直接处理,保存文本
2.json解析字符串,结构化处理
3.正则表达式,解析规则字符串,使用re库
4.beautifulsoup解析库,解析HTML数据的库
5.pyquery
6.xpath
爬虫的应用和价值
爬虫程序的应用和价值显而易见,可以自动抢购茅台。当然,你也可以写抢购各种优惠券,秒杀,高铁抢票等,女同学可以爬取你喜欢的文章,微博保存下来,男同学可以爬取各种妹子图保存下来。
有的人还会爬股票的数据,分析涨跌关系,制定模型,实现自动化炒股等。
对我们来说,能学会爬虫,相当于也熟悉了 python,可以自己写一写自动化的程序,减少很多重复的劳动,提高我们的工作效率,有更多时间做自己想做的事情。
最后
学习 Python,学习爬虫,可以帮助我们实现很多功能,大家有空可以一起学习,一起进步。
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你,干货内容包括:
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python入门学习视频👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉Python学习礼包👈
包括:Python开发工具、Python热门电子书、Python100道练习题、Python爬虫&数据分析&人工智能&办公自动化等学习资料
👉Python实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
点击免费领取《CSDN大礼包》:Python入门到进阶资料 & 实战源码 & 兼职接单方法 安全链接免费领取
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









