










无论你是刚踏入数据分析大门的新手,还是希望深化技能的老手,这篇文章都将是你旅程中的良师益友。我们将一起探索十个实用的Python数据分析技巧,让你的数据处理能力飞速提升。
1. 导入数据:Pandas是你的好朋友
-
技巧说明:Pandas库是数据分析的基础,它让数据导入变得轻松。
-
实践示例:
import pandas as pd
data = pd.read_csv('data.csv') # 用read_csv导入CSV文件
print(data.head()) # 查看数据前五行
- 解释:通过
pd.read_csv()函数,Python可以读取CSV文件,head()则帮助我们快速预览数据,确保一切顺利。
2. 数据清洗:缺失值处理
-
技巧说明:识别并处理缺失数据是数据分析的关键步骤。
-
实践示例:
data.dropna(inplace=True) # 删除含有缺失值的行
data['column_name'].fillna(value, inplace=True) # 用特定值填充某列的缺失值
- 注意:选择合适的方法处理缺失值,不要无脑删除,以免丢失重要信息。
3. 数据类型转换
-
技巧说明:确保数据类型正确对于分析至关重要。
-
实践示例:
data['column'] = data['column'].astype(float) # 将某一列转换为浮点型
- 解释:这有助于执行数学运算或确保数据的一致性。
4. 筛选与过滤数据
-
技巧说明:根据条件选择数据行。
-
实践示例:
filtered_data = data[data['age'] > 18] # 筛选出年龄大于18的记录
- 小贴士:利用布尔索引进行高效筛选。
5. 数据聚合与分组操作
-
技巧说明:使用
groupby()进行数据分组,然后聚合计算。 -
实践示例:
grouped_data = data.groupby('category').mean() # 按类别求均值
- 理解:这对于理解数据的结构和模式至关重要。
6. 数据可视化:Matplotlib与Seaborn
-
技巧说明:视觉化使数据更容易理解。
-
实践示例(使用Matplotlib):
import matplotlib.pyplot as plt
data['value'].hist() # 绘制直方图
plt.show()
- 扩展:Seaborn提供了更高级的图表,如箱线图和热力图。
7. 时间序列分析
-
技巧说明:处理按时间顺序排列的数据。
-
实践示例:
data['date'] = pd.to_datetime(data['date']) # 将字符串转换为日期
data.set_index('date', inplace=True) # 以日期作为索引
- 深入:使用
resample()进行时间序列的重采样。
8. 数据预处理:标准化与归一化
-
技巧说明:准备数据以供模型训练。
-
实践示例(使用Scikit-learn):
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data[['feature1', 'feature2']])
- 为什么重要:这有助于算法更好地学习,尤其是当特征尺度不同时。
9. 异常检测:识别数据中的离群点
-
技巧说明:使用统计方法或机器学习识别异常值。
-
实践提示:
-
利用Z-score或IQR(四分位距)进行基本的异常检测。
-
进阶:使用DBSCAN算法。
10. 数据合并与连接
-
技巧说明:将多个数据集结合成一个。
-
实践示例:
merged_data = pd.merge(data1, data2, on='common_column') # 基于共同列合并
- 应用场景:合并用户行为数据与产品信息,进行综合分析。
进阶技巧与实战策略
在掌握了上述基础技巧后,让我们进一步探索几个进阶的Python数据分析策略,以及如何将它们应用于解决复杂问题。
11. 使用Pandas Profiling进行快速数据探索
-
技巧说明:快速生成数据报告,了解数据概貌。
-
实践示例:
!pip install pandas_profiling # 安装
import pandas_profiling
report = pandas_profiling.ProfileReport(data)
report.to_html("data_report.html") # 生成HTML报告
- 价值:无需编写大量代码即可深入了解数据特性。
12. 时间序列预测:ARIMA模型
-
技巧说明:时间序列分析的高级工具,用于预测未来趋势。
-
实践路径:
-
首先,确保数据是时间序列格式。
-
使用
statsmodels库构建ARIMA模型。
from statsmodels.tsa.arima.model import ARIMA
model = ARIMA(data['value'], order=(5,1,0)) # 示例参数
results = model.fit()
forecast = results.forecast(steps=10) # 预测未来10个时间点
- 注意:选择合适的ARIMA参数需要基于ACF和PACF图的分析。
13. 数据清洗中的正则表达式
-
技巧说明:强大的文本处理工具。
-
实践示例:
import re
data['column'] = data['column'].str.replace(r'\D+', '', regex=True) # 移除非数字字符
- 技巧:正则表达式(
re)模块能高效处理文本数据清洗。
14. 利用NumPy优化计算
-
技巧说明:对于大规模数值计算,NumPy是不可或缺的。
-
实践应用:
import numpy as np
mean_value = np.mean(data['column']) # 快速计算平均值
- 优势:NumPy数组操作通常比同等的Pandas操作更快。
15. 数据可视化进阶:交互式图表
-
技巧说明:使用Plotly或Bokeh创建交互式图表。
-
实践示例(Plotly):
import plotly.express as px
fig = px.scatter(data, x='feature1', y='feature2', color='category')
fig.show()
- 体验提升:交互式图表能够提供更深入的数据洞察。
实战案例分析与技巧总结
-
练习技巧:选取一个实际数据集,从数据导入开始,逐步应用上述技巧,先做简单的数据清洗和描述性分析,然后尝试预测模型或可视化复杂关系。
-
使用技巧:在处理大数据时,考虑使用Dask或Vaex代替Pandas,以提高效率。
-
注意事项:数据隐私和安全永远是首位的,确保在合法合规的范围内处理数据。
通过这些实战策略和技巧的运用,你的数据分析能力将得到显著提升。
`黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
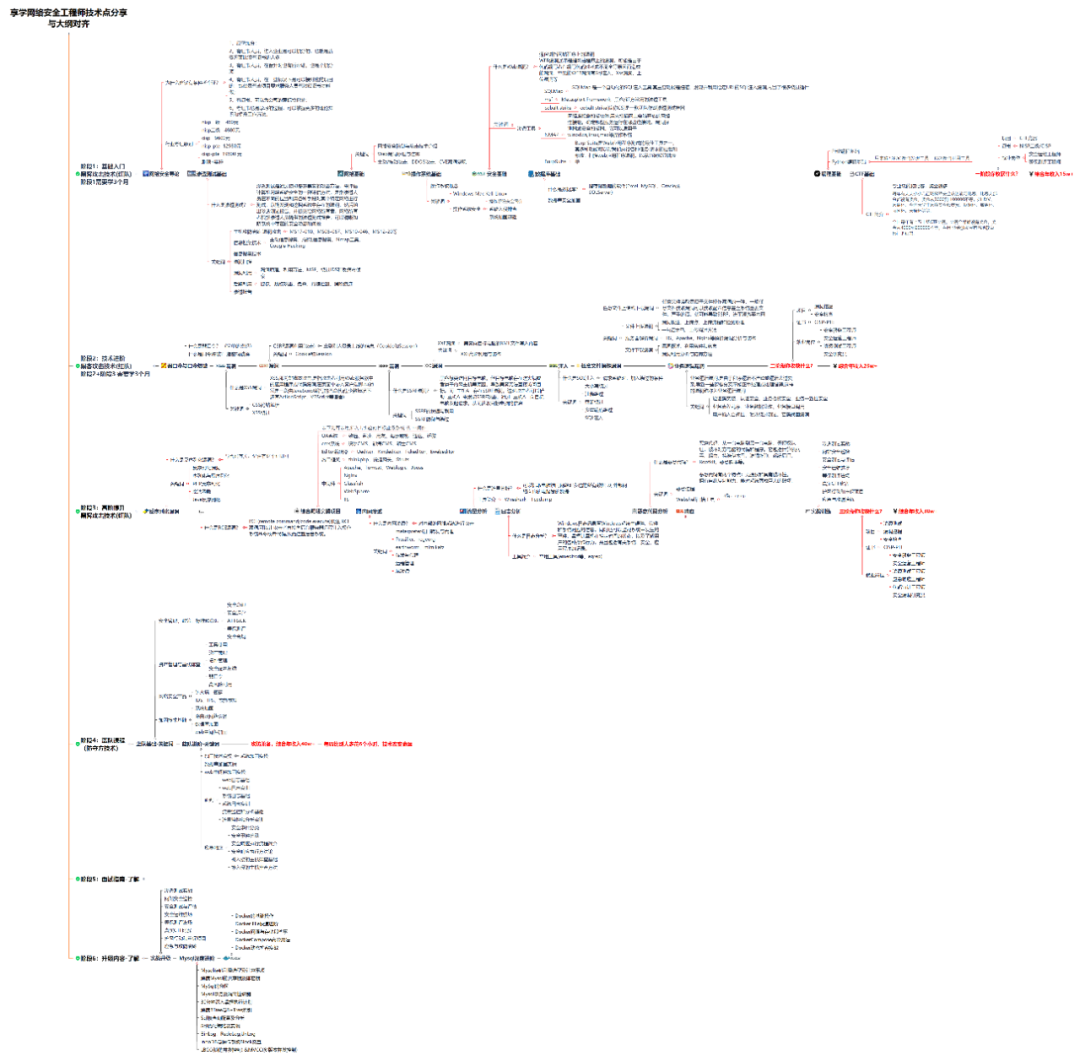
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。

(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 1452
1452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









