









大数据领域正在不断扩大:各类公司每年都在产生更多各种形式的数据。不断增长的数据量和多样性正在推动公司加大对大数据工具和技术的投资,以利用所有这些数据来改进运营、更好地了解客户、更快地交付产品,并通过分析应用程序获得其他业务优势。
以下是受欢迎的开源工具和技术,用于管理和分析大数据。

1. Airflow
Airflow是一个用于在大数据系统中调度和运行复杂数据管道的工作流管理平台。它使数据工程师和其他用户能够确保工作流中的每个任务按指定顺序执行,并具有访问所需系统资源的权限。工作流是用Python编程语言创建的,它可用于构建机器学习模型、传输数据和各种其他用途。
该平台起源于2014年底的Airbnb,并于2015年中正式宣布为开源技术;次年,它加入了Apache软件基金会的孵化器计划,并于2019年成为Apache的顶级项目。
Airflow还包括以下关键特性:
-
围绕有向无环图(DAGs)概念构建的模块化和可扩展的体系结构,用于展示工作流中不同任务之间的依赖关系。
-
网页应用程序界面,可用于可视化数据管道、监控其生产状态并解决问题。
-
与主要云平台和其他第三方服务的现成集成。

2. Delta Lake
Databricks Inc. 是一家由 Spark 处理引擎的创建者创立的软件供应商,开发了 Delta Lake,然后于 2019 年通过 Linux 基金会开源了基于 Spark 的技术。该公司将 Delta Lake 描述为“一个开放格式的存储层,可为数据湖上的流和批处理操作提供可靠性、安全性和性能”
Delta Lake并不取代数据湖;相反,它设计为位于数据湖之上,为结构化、半结构化和非结构化数据创建一个单一的存储位置,消除可能阻碍大数据应用的数据孤岛。此外,据Databricks称,使用Delta Lake可以帮助防止数据损坏,实现更快的查询,提高数据新鲜度,并支持合规努力。该技术还具有以下特性:
-
支持ACID事务,即具有原子性、一致性、隔离性和持久性的事务。
-
能够以开放的Apache Parquet格式存储数据。
-
一组与Spark兼容的API。
3. Drill
Apache Drill被描述为“一个用于大规模数据集的低延迟分布式查询引擎,包括结构化和半结构化/嵌套数据”。Drill能够跨数千个集群节点进行扩展,并通过使用SQL和标准连接API查询PB级的数据。
Drill 专为探索大数据集而设计,位于多个数据源之上,使用户能够查询不同格式的各种数据,从 Hadoop 序列文件和服务器日志到 NoSQL 数据库和云对象存储。它还可以执行以下操作:
-
通过插件访问大多数关系数据库。
-
使用常用的 BI 工具,例如 Tableau 和 Qlik。
-
可以在任何分布式集群环境中运行,尽管它需要 Apache 的 ZooKeeper 软件来维护有关集群的信息。
4. Druid
Druid是一个实时分析数据库,具有低查询延迟、高并发性、多租户能力和对流数据的即时可见性。
Druid是用Java编写的,于2011年创建,在2018年成为Apache技术。它通常被认为是传统数据仓库的高性能替代品,最适合事件驱动的数据。与数据仓库类似,它使用面向列的存储,并可以批量加载文件。但它还融合了搜索系统和时间序列数据库的特性,包括以下内容:
-
本地反向搜索索引,加速搜索和数据过滤。
-
基于时间的数据分区和查询。
-
具有对半结构化和嵌套数据的本机支持的灵活模式。
5. Flink
Flink是另一个Apache开源技术,是一个用于分布式、高性能和始终可用的应用程序的流处理框架。它支持有状态的计算,可以处理有界和无界数据流,并可用于批处理、图形处理和迭代处理。
Flink可以实时处理数百万个事件,实现低延迟和高吞吐量。Flink设计为在所有常见的集群环境中运行,还包括以下特性:
-
具有在需要时访问磁盘存储的内存计算。
-
用于创建不同类型应用程序的三个API层。
-
一组用于复杂事件处理、机器学习和其他常见大数据用例的库。
6. Hadoop
Hadoop是一个分布式框架,用于在廉价硬件集群上存储数据和运行应用程序。它是一项开创性的大数据技术,旨在处理不断增长的结构化、非结构化和半结构化数据量。首次发布于2006年,起初几乎与大数据同义;尽管后来被其他技术部分取代,但仍然被广泛使用。
Hadoop有四个主要组件:
-
Hadoop分布式文件系统(HDFS)将数据分割成块以存储在集群中的节点上,使用复制方法防止数据丢失,并管理对数据的访问。
-
YARN(Yet Another Resource Negotiator),用于调度作业在集群节点上运行并分配系统资源。
-
Hadoop MapReduce,一个内置的批处理处理引擎,将大型计算拆分并在不同节点上运行以提高速度和负载平衡。
-
Hadoop Common,一组共享的实用程序和库。
最初,Hadoop仅能运行MapReduce批处理应用程序。2013年引入的YARN使其对其他处理引擎和用例开放,但该框架仍然与MapReduce密切相关。更广泛的Apache Hadoop生态系统还包括各种大数据工具和额外的框架,用于处理、管理和分析大数据。
`黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
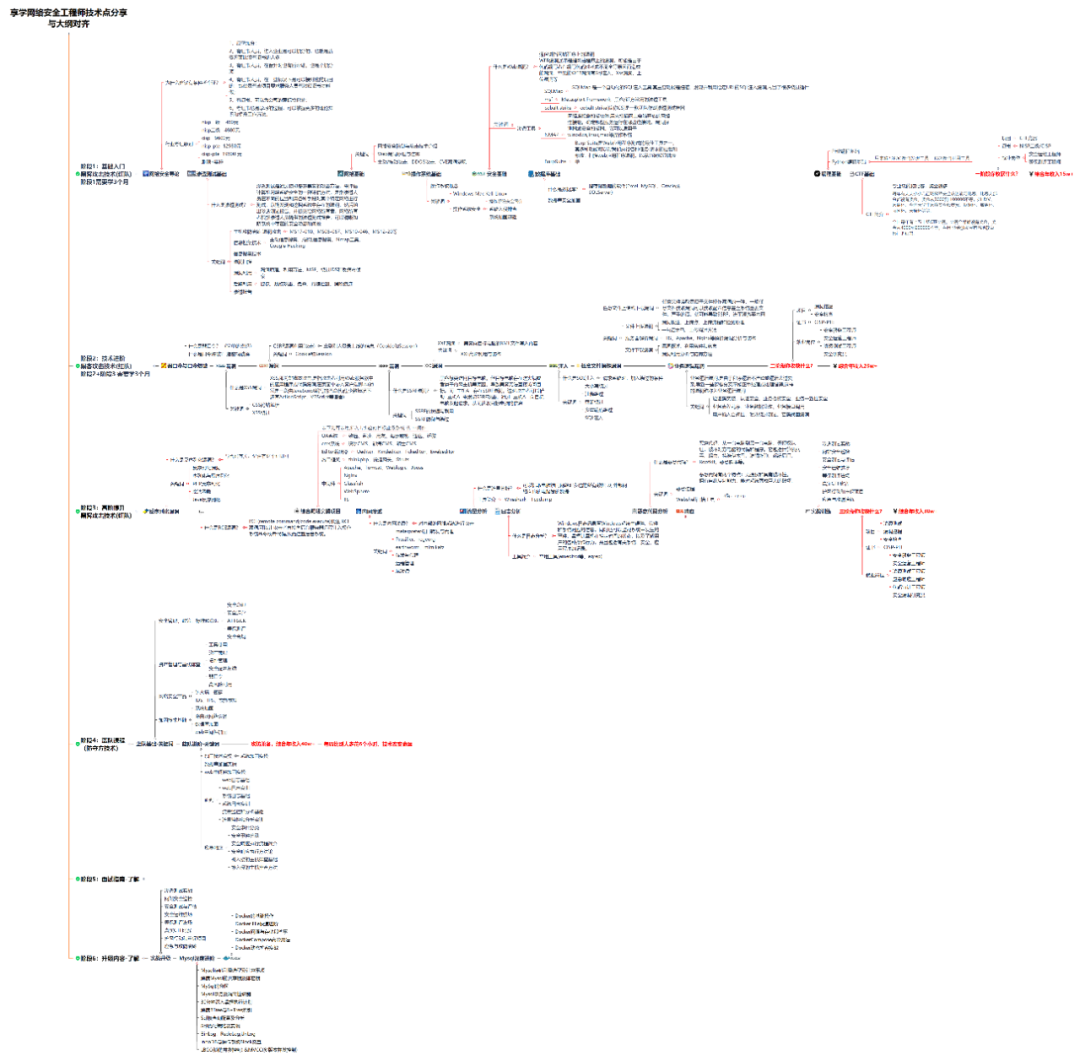
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
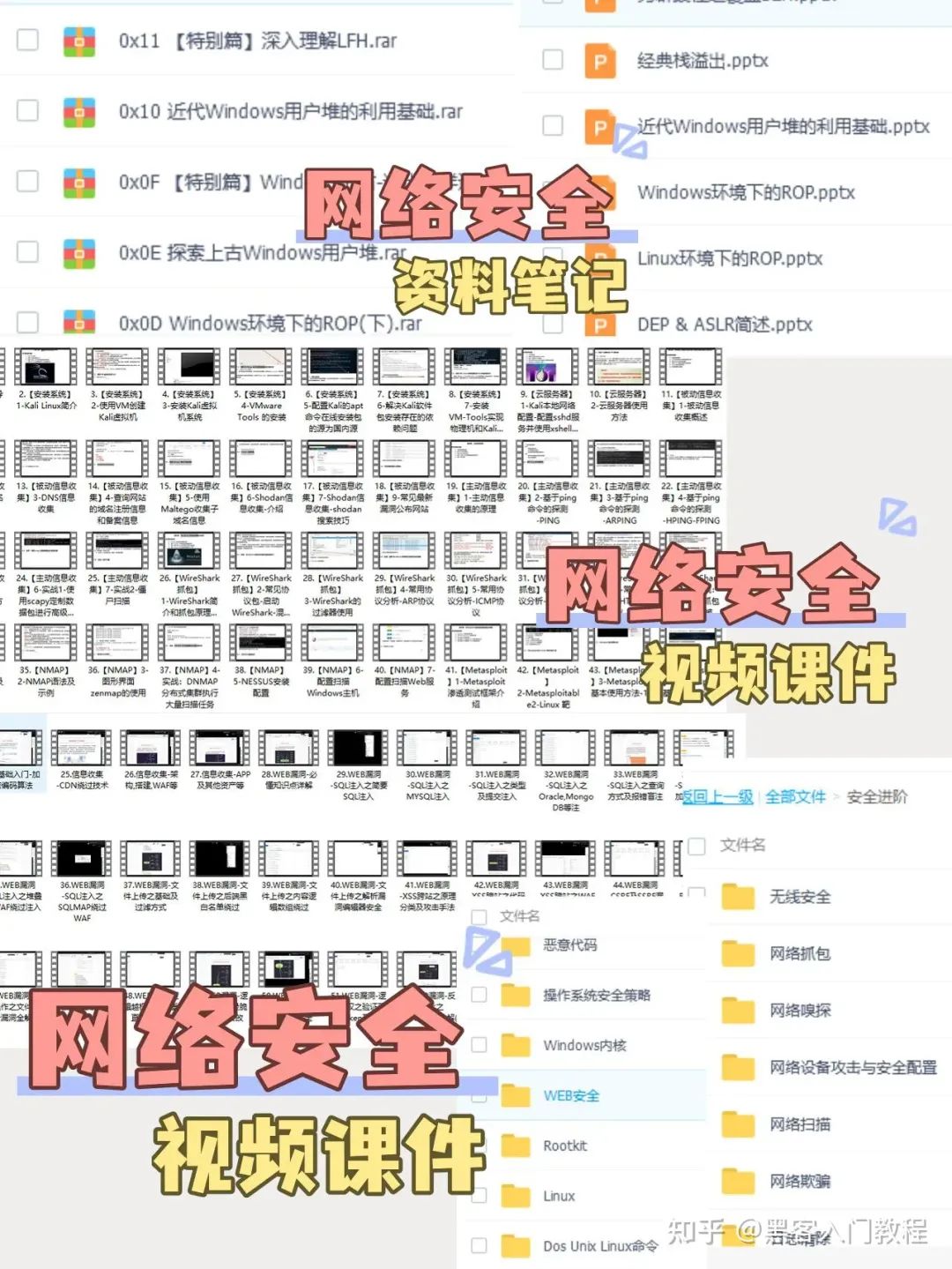
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









