







对于一些简单的爬虫,python(基于python3)有更好的第三方库来实现它,且容易上手。
Python标准库–logging模块
logging模块能够代替print函数的功能,将标准输出到日志文件保存起来,利用loggin模块可以部分替代debug
re模块
正则表达式
sys模块
系统相关模块
sys.argv(返回一个列表,包含所有的命令行)
sys.exit(退出程序)
Python标准库–urllib模块
urllib.requset.urlioen可以打开HTTP(主要)、HTTPS、FTP、协议的URL
ca 身份验证
data 以post方式提交URL时使用
url 提交网络地址(全程 前端需协议名 后端需端口 http:/192.168.1.1:80)
timeout 超时时间设置
函数返回对象有三个额外的方法
geturl() 返回response的url信息 常用与url重定向
info()返回response的基本信息
getcode()返回response的状态代码
1,request
urllib.request最常见的用法是直接使用urllib.request.urlopen()来发起请求,但通常这样是不规范的
一个完整的请求还应该包括headers这样的信息传递,可以这样实
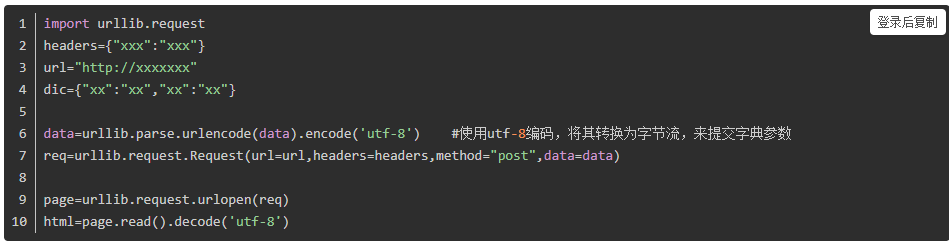
通常防止爬虫被检测,我们需要规定headers,伪造爬虫头部信息,但此方法一般用途不大。
2,BeautifulSoup
beautifulsoup的功能很强大,利用它我们可以实现网页的轻松解析,省掉写很多正则表达式的麻烦。
它拥有几个强大的解析库,包括 内置的html解析器,lxml,html5lib。
一般默认的是html解析器 html.parser
最好的大概是lxml了
用法:

展现beautifulsoup强大的标签选择功能
获取某个html标签的属性:
print(soup.p['name'])
获取某个标签的内容:
print(soup.p.string)
获取某个标签内的所有内容,存入列表中
plist=soup.p.contents
获取某个标签内的所有内容,存入列表中
plist=soup.p.contents
find_all()标签选择器
例如我们要找到id=content 的div标签的内容
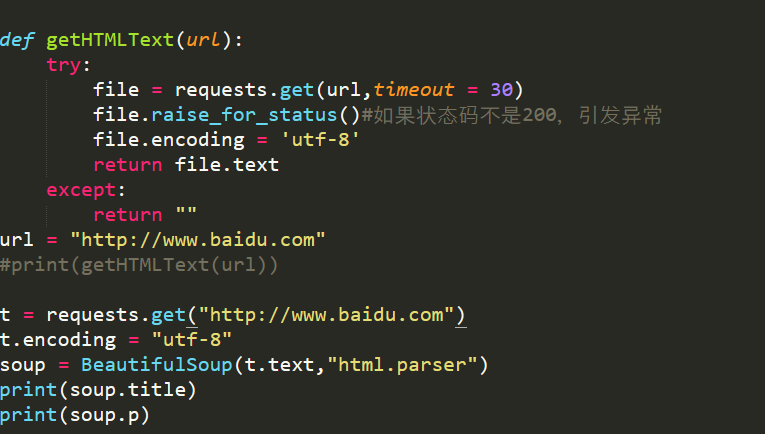
成功爬取:
最后,如果你对Python感兴趣,想要学习python,希望可以帮到你,一起加油!以上是给大家分享的Python全套学习资料,都是我自己学习时整理的:
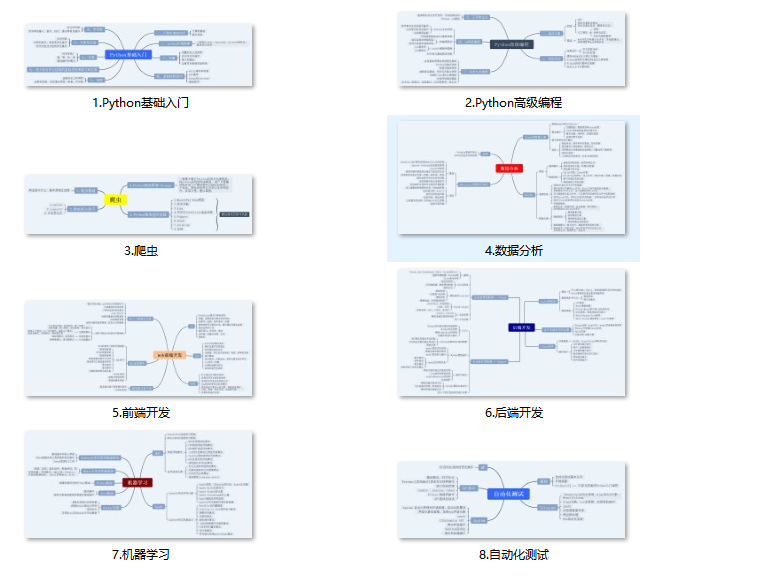
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
**学习资源已打包,需要的小伙伴可以戳这里:【学习资料】















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









