
我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后迎刃而解了。这个程序非常的简单,程序的大概就是先获取网页的源代码,然后在网页的源代码中提取每个章节的url,获取之后,在通过每个url去获取文章的内容,在进行提取内容,然后就是保存到本地,一TXT的文件类型保存。
大概是这样
1:获取网页源代码
2:获取每章的url
3:获取每章的内容
4:下载保存文件中
1、首先就是先安装第三方库requests,这个库,打开cmd,输入pip install requests回车就可以了,等待安装。然后测试
2、然后就可以编写程序了,首先获取网页源代码,也可以在浏览器查看和这个进行对比。
| 1 2 3 4 | s = requests.Session()
url = 'https://www.xxbiquge.com/2_2634/'
html = s.get(url)
html.encoding = 'utf-8'
|
运行后显示网页源代码

按F12查看
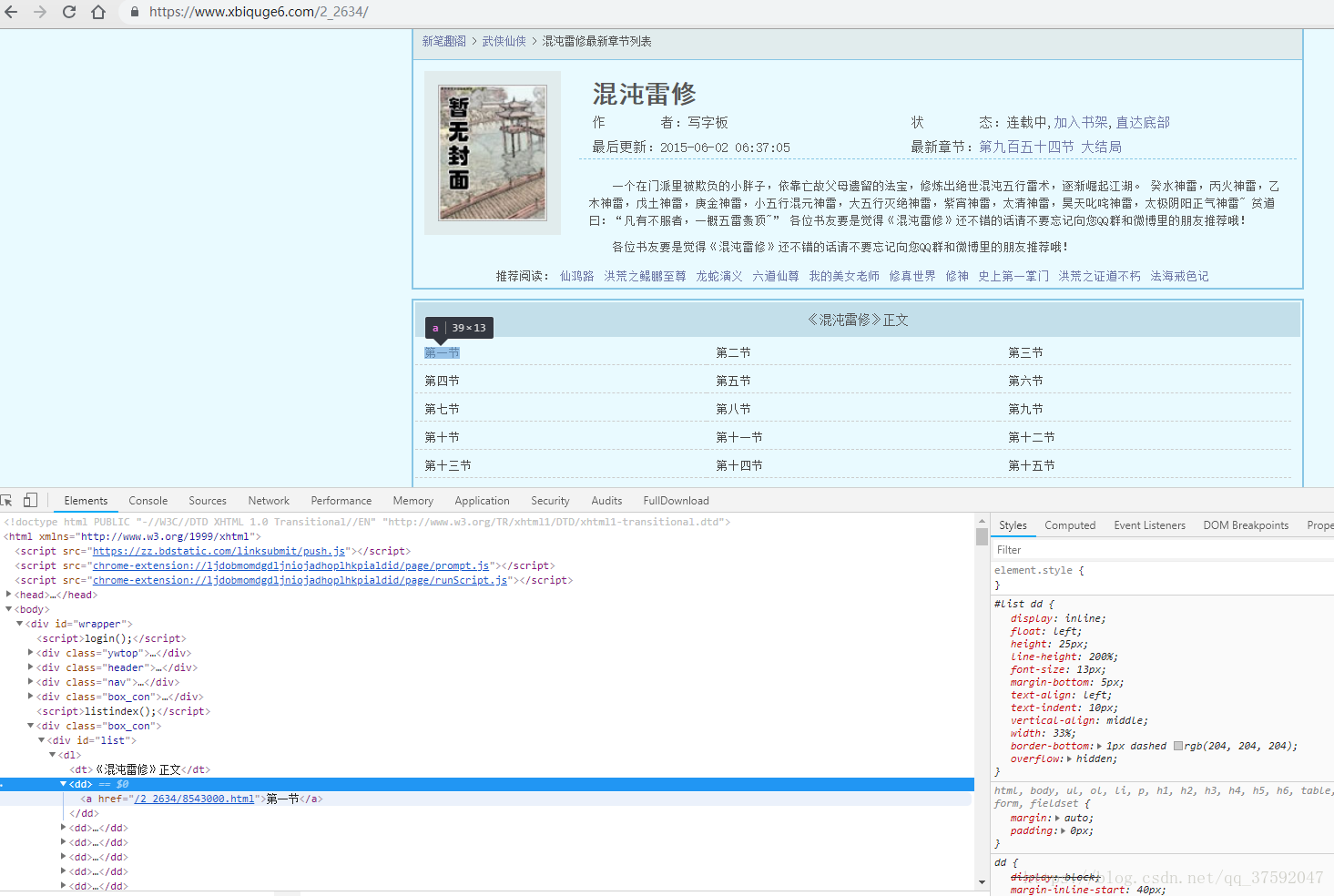
说明这是对的,
3、然后进行获取网页源代码中的每章url,进行提取
| 1 2 | caption_title_1 = re.findall(r'<a href="(/2_2634/.*?\.html)">.*?</a>',html.text)
print(caption_title_1)
|

由于过多,就剪切了这些,看到这些URL,你可能想问为什么不是完整的,这是因为网页中的本来就不完整,需要进行拼凑得到完整的url

这样就完成了,就可以得到完整的了
4、下面就是获取章节名,和章节内容
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #获取章节名
name = re.findall(r'<meta name="keywords" content="(.*?)" />',r1.text)[0] # 提取章节名
print(name)
file_name.write(name)
file_name.write('\n')
# 获取章节内容
chapters = re.findall(r'<div id="content">(.*?)</div>',r1.text,re.S)[0] #提取章节内容
chapters = chapters.replace(' ', '') # 后面的是进行数据清洗
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
|
5、转换字符串和保存文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | # 转换字符串
s = str(chapters)
s_replace = s.replace('<br/>',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)
fiction = pattern.sub(' ',s_replace)
file_name.write(fiction)
file_name.write('\n')
|
6、完整的代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | import requests
import re
s = requests.Session()
url = 'https://www.xxbiquge.com/2_2634/'
html = s.get(url)
html.encoding = 'utf-8'
# 获取章节
caption_title_1 = re.findall(r'<a href="(/2_2634/.*?\.html)">.*?</a>',html.text)
# 写文件
path = r'C:\Users\Administrator\PycharmProjects\untitled\title.txt' # 这是我存放的位置,你可以进行更改
file_name = open(path,'a',encoding='utf-8')
# 循环下载每一张
for i in caption_title_1:
caption_title_1 = 'https://www.xxbiquge.com'+i
# 网页源代码
s1 = requests.Session()
r1 = s1.get(caption_title_1)
r1.encoding = 'utf-8'
# 获取章节名
name = re.findall(r'<meta name="keywords" content="(.*?)" />',r1.text)[0]
print(name)
file_name.write(name)
file_name.write('\n')
# 获取章节内容
chapters = re.findall(r'<div id="content">(.*?)</div>',r1.text,re.S)[0]
chapters = chapters.replace(' ', '')
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
# 转换字符串
s = str(chapters)
s_replace = s.replace('<br/>',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)
fiction = pattern.sub(' ',s_replace)
file_name.write(fiction)
file_name.write('\n')
file_name.close()
|
7、修改你想要爬取小说url后再进行运行,如果出现错误,可能是存放位置出错,可以再保存文件地址修改为你要存放的地址,然后就结束了

最后:如果你对Python感兴趣,想要学习Python,希望可以帮到你,一起加油!以上是给大家分享的Python全套学习资料,都是我自己学习时整理的:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
**学习资源已打包,需要的小伙伴可以戳这里:【学习资料】






















 1111
1111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









