







-
1.简述
-
2.字体反爬处理
-
2.1.获取字体文件链接
-
2.2.创建三类字体与实际字符映射关系
-
-
3.单页店铺信息解析
-
4.全部页数据获取
-
4.1.获取数据页数
-
4.2.采集全部数据
-
-
5.总结
-
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤
QQ群:232030553
冬天是一个适合滑雪的季节,但是滑雪需谨慎,比如初学者就不要上高级道,能不能滑心里要有点哔数。
那么今天,咱们就以滑雪为关键字,演示一下如何用Python爬虫采集大众点评的商铺信息吧。
在搜索结果以 翻页 的形式通过 request.get() 即可获取页面数据,然后再对网页数据进行相关解析即可获得我们需要的商铺信息。
不过在爬虫过程中,我们会发现比如商铺评价数、人均消费以及商铺的地址等信息在网页上显示为 □ ,在get的数据中是类似  ,咋一看不知道是什么。这里其实是一种字体反爬,接下来我们就将其个个击破吧。
以下是我们需要采集的数据字段:
| 字段 | 说明 | 获取方式 | 字体 |
|---|---|---|---|
| shop_id | 商铺ID | 直接获取 | |
| shop_name | 商铺名称 | 直接获取 | |
| shop_star | 商铺星级 | 直接获取 | |
| shop_address | 商铺地址 | 直接获取 | |
| shop_review | 商铺评价数 | 字体反爬 | shopNum |
| shop_price | 商铺人均消费 | 字体反爬 | shopNum |
| shop_tag_site | 商铺所在区域 | 字体反爬 | tagName |
| shop_tag_type | 商铺分类 | 字体反爬 | tagName |
2.字体反爬处理
打开大众点评,搜索 滑雪,我们在搜索结果页面 按F12进入到开发者模式,选到评价数可以看到其 class 为 shopNum且内容为□ ,在 右侧styles中可见其字体font-family为PingFangSC-Regular-shopNum 。其实,点击右侧.css链接可以找到其字体文件链接。考虑到其他涉及到字体反爬的字段信息对应的字体文件链接可能有差异,我们采集另外一种方式进行一次性获取(具体请看下一段)。

字体反爬(评价数)
2.1.获取字体文件链接
我们在 网页的head 部分,可以找到 图文混排css ,其对应的css地址就包含了后续会用到的全部字体文件链接 ,直接用requess.get()请求改地址即可返回全部字体名称及其字体文件下载链接。
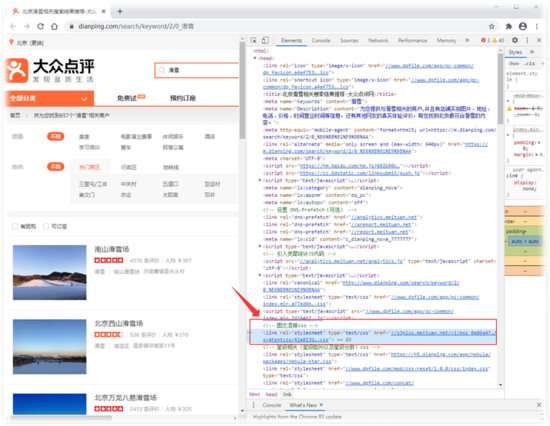
字体反爬(字体链接)
- 定义获取网页数据的函数方法get_html()
# 获取网页数据
def get_html(url, headers):
try:
rep = requests.get(url ,headers=headers)
except Exception as e :
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1680
1680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









