






包含编程籽料、学习路线图、爬虫代码、安装包等!【点击领取】

在本文中,我们将使用Python编写一个简单的爬虫程序,从天气网站爬取天气数据,并解析出我们需要的信息。我们将以中国天气网(www.weather.com.cn)为例,爬取指定城市的天气数据。
1. 准备工作
在开始之前,请确保你已经安装了以下Python库:
requests:用于发送HTTP请求。
BeautifulSoup:用于解析HTML文档。
你可以通过以下命令安装这些库:

2. 分析目标网站
打开中国天气网(www.weather.com.cn),搜索你想要获取天气数据的城市。例如,我们选择“北京”。
在浏览器中按F12打开开发者工具,查看网页的HTML结构。我们需要找到天气数据所在的标签和类名。
3. 编写爬虫代码
以下是完整的Python代码,用于爬取并解析天气数据:
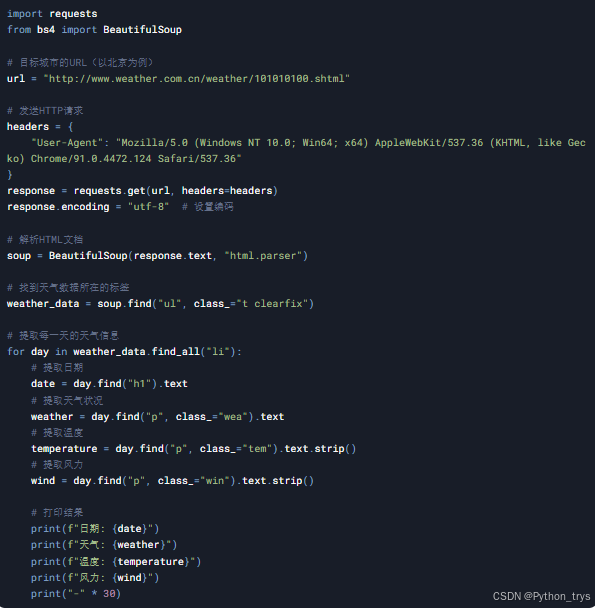
4. 代码解析
4.1 发送HTTP请求
我们使用requests.get()方法向目标URL发送HTTP请求,并设置User-Agent头部以模拟浏览器访问。
4.2 解析HTML文档
使用BeautifulSoup解析返回的HTML文档,html.parser是Python内置的解析器。
4.3 提取天气数据
通过分析网页的HTML结构,我们发现天气数据位于
- 标签下的
- 标签中。我们使用find_all()方法提取每一天的天气信息。
4.4 打印结果
将提取到的日期、天气状况、温度和风力信息打印出来。
5. 运行结果
运行上述代码后,你将看到类似以下的输出:

6. 注意事项
反爬虫机制:一些网站可能会检测到爬虫行为并封禁IP。可以通过设置代理或降低请求频率来规避。
合法性:在爬取数据时,请遵守目标网站的robots.txt文件和相关法律法规。
数据更新:天气数据是动态变化的,建议定时运行爬虫以获取最新数据。
7. 总结
本文介绍了如何使用Python爬取天气数据,并通过BeautifulSoup解析HTML文档。你可以根据需要扩展此代码,例如将数据保存到数据库或导出为Excel文件。希望这篇文章对你有所帮助!
如果你有任何问题或建议,欢迎在评论区留言!
最后:
希望你编程学习上不急不躁,按照计划有条不紊推进,把任何一件事做到极致,都是不容易的,加油,努力!相信自己!
文末福利
最后这里免费分享给大家一份Python全套学习资料,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以和我一起来学习交流呀。
包含编程资料、学习路线图、源代码、软件安装包等!【点击这里领取!】
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习


















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









