






 本文通过实际的电商数据集,探讨如何利用数据分析确定最可能转化的用户群体(如25-34岁的女性),并找出发送推广短信的最佳时间,如10月下旬至11月中旬的晚上8点至10点。
本文通过实际的电商数据集,探讨如何利用数据分析确定最可能转化的用户群体(如25-34岁的女性),并找出发送推广短信的最佳时间,如10月下旬至11月中旬的晚上8点至10点。
在互联网行业中,电子商务领域绝对是数据分析用途最多的地方,各大电商平台都依赖数据分析帮助其挖掘用户订单增长机会。比如某宝的随手买一件,核心思路也就是根据用户的日常浏览内容及停留时间,以及订单的关联度来进行推荐的。
本篇文章,我们来通过一个真实的电商数据集进行分析,在复习前面内容的基础上,也可以感受一下电商数据分析的分析流程。
1、需求说明
最近某个电商网站需要策划一场推广活动,通过发短信的方式,向客户发送广告和优惠信息,吸引他们来购物。但由于预算及短信限制,无法对全量客户发送,需要找出最有可能转化的人群,定向发送推广信息,同时,下单的行为往往也跟时间呈现一定的关联关系,推送时间也需要考虑。
基于以上的需求说明,作为数据分析师,我们就需要根据需求,制定自己的分析计划。那么我们的任务就是:
- 通过数据分析,找到最有可能转化的人群特征(比如年龄、性别、地域等)。
- 通过数据分析,给出最适合发送推广短信的时间。
任务明确之后,就需要考虑我们要完成以上任务,需要哪些数据支撑,开始找数据部门提供相应的数据支持。
通过一顿友(唇)好(枪)协(舌)商(战),最终从数据部门要到如下数据:
- 用户行为表:最近6个月的用户行为数据。也就是下单数据
- VIP数据:用户VIP会员开通数据。
- 用户数据:用户个人信息相关数据。
拿到数据之后,我们就可以大展拳脚了。
2、数据集获取及分析
为了方便我们学习,需要自己模拟一些相关数据,不想模拟的话,可以在公众号联系获取。
拿到数据后,解压后可以看到如下几个文件:
- user_behavior_time_resampled.csv (用户行为数据)
- vip_users.csv (VIP用户数据)
- user_info.csv(用户数据)
我们先来看一下各个表的字段说明:
user_behavior_time_resampled.csv  vip_users.csv
vip_users.csv
 user_info.csv
user_info.csv

3、加载数据
从这里开始,我们就开始使用我们前面了解的一些包和库来读取数据了,这里首先是使用pandas来加载数据。
import pandas as pd
df_user_log = pd.read_csv("EComm/user_behavior_time_resampled.csv")
df_vip_user = pd.read_csv("EComm/vip_user.csv")
df_user_info = pd.read_csv("EComm/user_info.csv")
df_user_log
df_vip_user
df_user_info
加载完后,输出如下:



❝
这里,df_user_log表中有一个 time_stamp 和 timestamp 字段,我们需要了解一下这两个字段的意思。
先看一下这两个字段的边界值
time_stamp_max = str(df_user_log['time_stamp'].max())
time_stamp_min = str(df_user_log['time_stamp'].min())
print("time_stamp max: " + time_stamp_max, "time_stamp min: " + time_stamp_min)
timestamp_max = str(df_user_log['timestamp'].max())
timestamp_min = str(df_user_log['timestamp'].min())
print("timestamp max: " + timestamp_max, "timestamp min: " + timestamp_min)
输出如下:
time_stamp max: 1112, time_stamp min: 511
timestamp max: 86399.99327792758, timestamp min: 0.10787397733480476
可以看到,time_stamp 的最大值为 1112,最小值为 511,而 timestamp 的最大值为 86399.99 最小值为 0.1。
从数据集的描述中,用户行为表是用户 6 个月的行为,那 time_stamp 最大 1112,最小 511 看起来就特别像日期。代表最小日期是 5 月 11 日,最大日期是 11 月 12 日。
那既然 time_stamp 是日期,那 timestamp 会不会是具体的时间呢?timestamp 的最大值为 86399 ,而一天最大的秒数为 24*3600 = 86400。两个数字非常接近,那基本可以认定 timestamp 代表的是一天中的第几秒发生了这个行为。
破解了两个时间字段的问题,为了避免后面有歧义,我们将 time_stamp 列重命名为 date。
df_user_log.rename(columns={'time_stamp':'date'}, inplace = True)
df_user_log
完成数据读取,了解了各个字段的含义之后,我们就可以开始进行数据清洗了。
4、数据清洗
针对数据分析中使用的数据集,我们需要尽可能去了解数据的完整性,与我们数据分析无关的字段,不清洗也没关系。但是,重点的分析维度,如果出现缺失,我们就要考虑是否进行补全或者是直接去除。
我们先来看下缺失值情况:
(1)user_log表
df_user_log.isnull().sum()
输出如下:
user_id 0
item_id 0
cat_id 0
seller_id 0
brand_id 18132
date 0
action_type 0
timestamp 0
dtype: int64
从上面的结果来看,log表有18000多数据缺少品牌数据,缺失率比较低0.16%(1.8w/1098w),一般这个数量级不会影响到数据分析的整体严谨性,我们暂不做处理。
(2)user_info表
df_user_info.isnull().sum()
输出如下:
user_id 0
age_range 2217
gender 6436
dtype: int64
从结果中可以看出,info表中有2217条数据缺失年龄数据,6436条数据缺失性别字段。但是我们是有对用户的年龄和性别做分析的,而且补全的话也是完全没规律补全的,所以这里我们就直接删除。
df_user_info = df_user_info.dropna()
df_user_info
3、vip_user表
df_vip_user.isnull().sum()
输出:
user_id 0
merchant_id 0
label 0
dtype: int64
从结果来看,vip表无缺失,不需要处理。
5、数据分析
做完以上的准备工作,就要开始进入我们最核心的数据分析工作了。
还记得我们的分析任务吗? 第一是要定位需要推广的人群,第二是确定推广信息发送的时间。那么针对我们的两个任务,来进行接下来的工作。
(1)用户年龄分析
我们先通过DataFrame的value_counts函数来看一下年龄的分布情况:
df_user_info.age_range.value_counts()
输出:
3.0 110952
0.0 90638
4.0 79649
2.0 52420
5.0 40601
6.0 35257
7.0 6924
8.0 1243
1.0 24
Name: age_range, dtype: int64
除开未知的数据我们不看,可以发现,取值为3和4的是占比最大的。3和4又分别代表25-30岁和30-34岁。我们再用代码计算出25-34岁的用户比例。
user_ages = df_user_info.loc[df_user_info["age_range"] != 0, "age_range"]
user_ages.loc[(user_ages == 3) | (user_ages == 4) ].shape[0] / user_ages.shape[0]
输出:
0.5827529275078729
可以看出,25-34岁区间的用户比例在58%。
##(2)用户性别分析 接下来,我们再用value_counts函数来分析性别。
df_user_info.gender.value_counts()
输出:
0.0 285634
1.0 121655
2.0 10419
Name: gender, dtype: int64
从字段含义来看,0代表女性,1代表男性,2代表未知。由此可以得出,平台的核心用户群体是女性,数量是男性的2.35倍。
截止到这里,我们通过用户群体的分析,已经可以得出:平台的核心用户是25-34岁的女性,但这样情况是否符合实际呢?毕竟我们只是分析了注册用户信息,并没有与订单数据结合来分析。说不定只是女性注册的多,但下单的少。所以下一步,我们将用户信息和订单数据来结合起来验证一下猜想是否合理。
(3)将用户信息和订单信息结合
上面聊到了,我们需要将用户信息和订单信息结合起来分析是否是女性的购买力更强。但是用户数据和订单数据属于在不用的表中,那我们该怎么处理呢? 可以看一下数据情况,发现用户表和订单表都有一个叫user_id的字段,这样,我们就有办法把两张表关联起来了。
通过user_id将两个表关联起来:
df_user_log = df_user_log.join(df_user_info.set_index('user_id'), on = 'user_id')
df_user_log
输出:
 由上面的输出可以看到,用户表的年龄和性别就被合并到订单表了。接下来我们就可以根据下单用户来分析用户的性别和年龄了。
由上面的输出可以看到,用户表的年龄和性别就被合并到订单表了。接下来我们就可以根据下单用户来分析用户的性别和年龄了。
(4)各年龄段的用户下单情况分析
df_user_log.loc[df_user_log["action_type"] == "order", ["age_range"]].age_range.value_counts()
输出:
3.0 172525
4.0 153795
0.0 114908
5.0 79298
6.0 61534
2.0 59072
7.0 10785
8.0 1924
1.0 21
Name: age_range, dtype: int64
通过上述结果,可以看出,下单的年龄段和用户信息的分析基本一致,25-34岁的人占比59.9%。
(5)各性别用户的下单情况分析
df_user_log.loc[df_user_log["action_type"] == "order", ["gender"]].gender.value_counts()
输出:
0.0 467381
1.0 161999
2.0 24482
Name: gender, dtype: int64
通过上述结果可以看出,依然是女性的下单量更大。到这里,我们基本可以下结论:我们发送推广短信的群体为25-34岁的女性用户。
到这里,我们的任务基本完成了一半了,已经确定好了发送短信的群体。但是另外一个任务是确定发送时间。我们接着往下分析。
(6)各日期的下单情况分析
这里我们通过对各个日期分组,查看哪个时间段下单的人群最多。因为数据是近6个月的数据,那我们就把数据分为6个组,来看一下:
df_user_log.loc[df_user_log["action_type"] == "order", ["date"]].date.value_counts(bins = 6)
输出:
(1011.0, 1111.0] 333721
(811.0, 911.0] 70699
(911.0, 1011.0] 69427
(510.399, 611.0] 68776
(611.0, 711.0] 62901
(711.0, 811.0] 54053
Name: date, dtype: int64
可以看出,在10月11日到11月11日下单的数量最多。分析完日期,我们再来看一下哪个时间段下单的比较多。
(7)各时间段下单情况分析
timestamp 字段存储了每条记录下单的时间,从当天零点开始累积的秒数。并不是很直观,我们更希望可以基于小时级的数据去分析。所以我们考虑基于 timestamp 这一列,新创建一列时间,来表示小时。
df_user_log.loc["time_hours_view"] = df_user_log["timestamp"]/3600
df_user_log
输出:
 我们直接用 value_count 来统计新增的 time_hours_view 字段,就可以实现对一天中的小时级分布进行分布统计。我们以两个小时为尺度,来查看分布,所以分为 12 组。
我们直接用 value_count 来统计新增的 time_hours_view 字段,就可以实现对一天中的小时级分布进行分布统计。我们以两个小时为尺度,来查看分布,所以分为 12 组。
df_user_log.loc[df_user_log["action_type"] == "order", ["time_hours_view"]].time_hours_view.value_counts(bins = 12)
输出:
(20.0, 22.0] 94209
(22.0, 24.0] 91529
(18.0, 20.0] 91330
(16.0, 18.0] 85681
(14.0, 16.0] 75372
(12.0, 14.0] 63580
(10.0, 12.0] 50909
(8.0, 10.0] 38938
(6.0, 8.0] 27962
(4.0, 6.0] 19428
(2.0, 4.0] 12639
(-0.025, 2.0] 8000
Name: time_hours_view, dtype: int64
从上述结果可以看出,晚上八点到十点是下单最多的。
到这里,我们根据需求进行数据分析的任务就已经全部完成了。已经基本确定,推广短信发送群体为:25-34岁的女性用户,发送短信的最佳时间周期是10月下旬到11月中旬的晚上八点到十点。
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
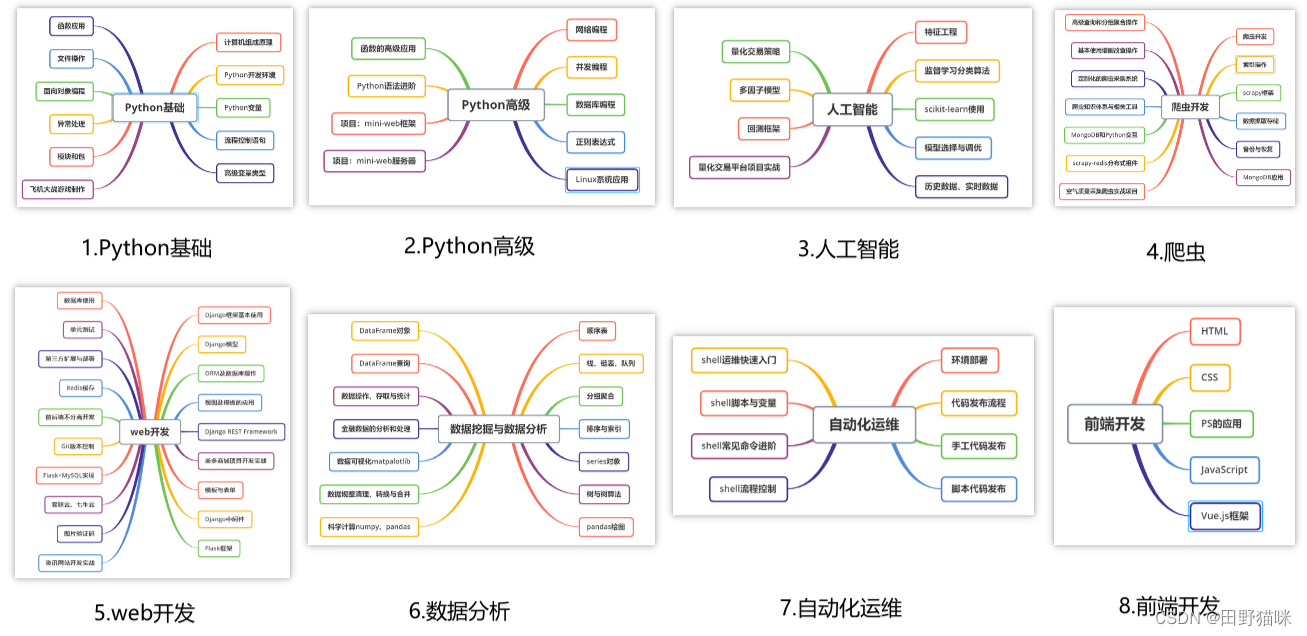
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









