






Python爬虫爬取网易云音乐可视化展示
简介
通过 Python 爬取网易云音乐平台上的华语歌手信息,并将其存储到本地的数据库中。然后通过歌手 ID 获取该歌手热门50首音乐的信息和评论数,筛选得到该歌手最多评论数的歌曲,并进行可视化展示。
本项目使用 Python 3.6+ 版本以及以下第三方库:
- requests
- BeautifulSoup
- lxml
- pyecharts
- pymysql
- Crypto
可视化展示
鼠标悬浮获取歌曲名字,由于数据过多,这里仅展示部分歌手的数据

模块介绍
本项目一共分为五个模块
主要模块为:
- artists.py:
爬取所有华语歌手信息,并存储到本地数据库中。
- music_by_artist.py:
根据歌手 ID,爬取该歌手热门50首歌曲的信息和评论数,将结果存储到本地数据库中。
其他模块为:
- decrypt.py:
本模块主要实现了对网易云音乐 API 接口的请求解密算法。因为在访问网易云音乐 API 接口时,需要对请求参数进行加密处理,才能得到正确的响应。本模块对外提供了一个名为 get_comments_counts的函数,通过传入关键参数和自定义算法进行模拟加密,返回请求成功的评论数据。
- sql.py:
本模块封装了对数据库 db_music 中 artists 和 musics 表的操作,包括保存歌曲、歌手信息、获取歌手评论数最高的歌曲信息、获取所有歌手的 ID、获取所有音乐的 ID 等操作。在使用 SQL 语句进行操作时,通过 pymysql模块连接到本地的数据库文件,然后执行对应的 SQL 语句。在执行 SQL 语句之前,需要使用 with 语句创建一个上下文管理器来确保数据库连接的安全关闭。
- charts.py:
本模块主要通过 echarts 库将数据库中获取到的歌手热门歌曲中评论最多的歌曲可视化展现出来。该模块使用 pyecharts 库中的 Bar 类创建柱状图,并通过 Web 服务器在浏览器端展示可视化结果。
运行步骤
使用以下命令在终端中分别运行模块:
python artists.py
python music_by_artist.py
python charts.py
不过,在运行 music_by_artist.py 之前,需要确保 artists 数据表中已获取到需要爬取的歌手 ID
具体方法可以参考 music_by_artist.py 中的代码示例
数据库结构
本项目使用 Mysql 数据库来存储音乐信息。数据库文件名为 db_music。本数据库中有两张数据表:
- artists:存储所有华语歌手的基本信息。
- musics:存储所有华语歌手热门50首歌曲的相关信息。
下面是两张表的详细结构:
artists
| 字段名称 | 类型 | 说明 |
|---|---|---|
| ARTIST_ID | int | 歌手ID |
| ARTIST_NAME | varchar(50) | 歌手名字 |
musics
| 字段名称 | 类型 | 说明 |
|---|---|---|
| MUSIC_ID | int | 音乐ID |
| MUSIC_NAME | varchar(50) | 音乐名字 |
| ARTIST_ID | int | 歌手ID |
| ARTIST_NAME | varchar(50) | 歌手名字 |
| COMMENTSCOUNT | int | 评论数 |
网页分析
在本项目中,我们主要爬取了两种类型的网页:
- 歌手列表页面
- 歌曲信息页面
歌手列表分析
歌手列表页面的 URL 格式如下:
https://music.163.com/#/discover/artist/cat?id=1001&initial=-1
{ id=1001 } 代表左侧各个列表对应的ID,例如华语男歌手为1001,华语女歌手为1002,欧美男歌手为2001(本项目以华语男歌手为例)
{ initial=-1} 代表中部首写字母的选项,例如热门为-1,其他为0,A-Z为65-90
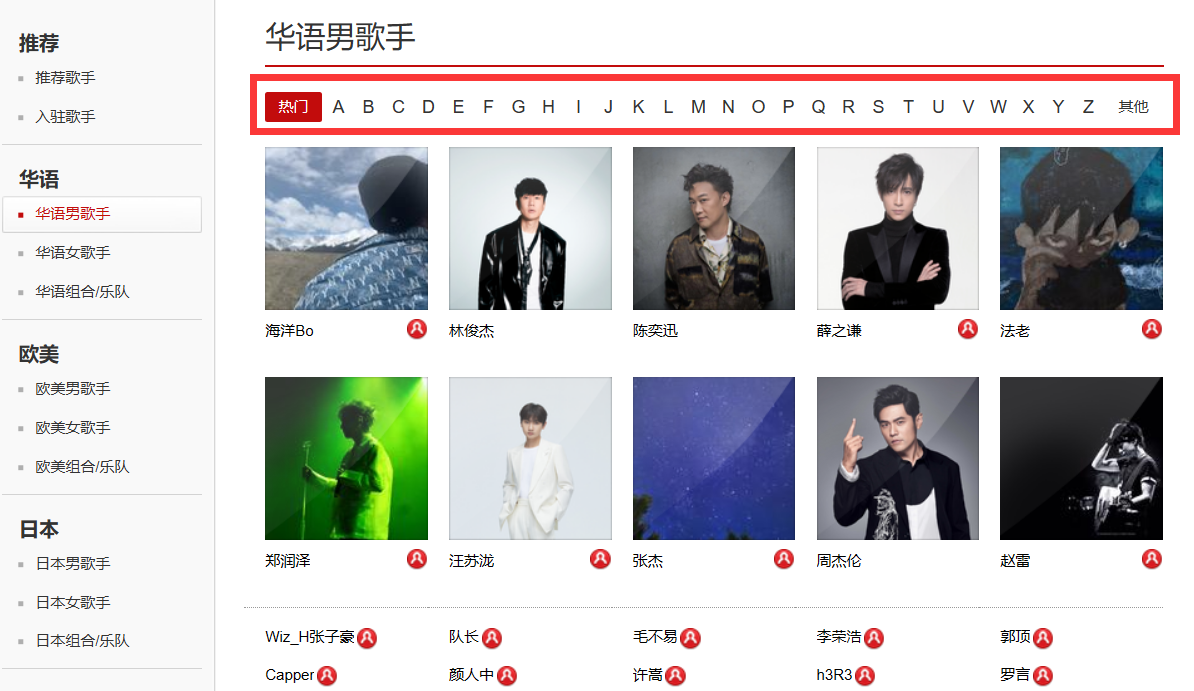
歌手列表页面包含了部分歌手头像和歌手姓名。我们目前仅爬取歌手的姓名。
我们可以使用 requests 库和 BeautifulSoup 库来进行爬取和解析。具体步骤如下:
- 使用 requests 库发送 HTTP GET 请求,获取歌手页面的 HTML 内容。
- 使用 BeautifulSoup 库解析 HTML 内容,找出歌手的姓名信息。
- 将找到的信息存储到本地数据库中。
主要的代码如下:
params = {'id': group_id, 'initial': initial}
# 发送GET请求到网易云音乐的歌手分类页面
r = requests.get('http://music.163.com/discover/artist/cat', params=params, headers=headers)
# 网页解析
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
# 找到包含歌手信息的HTML标签,并遍历标签中的所有歌手
artists = list(body.find_all('a', attrs={'class': 'nm nm-icn f-thide s-fc0'}))
for artist in artists:
artist_id = artist['href'].replace('/artist?id=', '').strip()
artist_name = artist['title'].replace('的音乐', '')
# 获取歌手id和歌手名字
print(artist_id, artist_name)
try:
# 将获取的歌手id和歌手名字存储到数据库中
sql.insert_artist(artist_id, artist_name)
except Exception as e:
# 如果出现异常则打印异常信息
print(e)
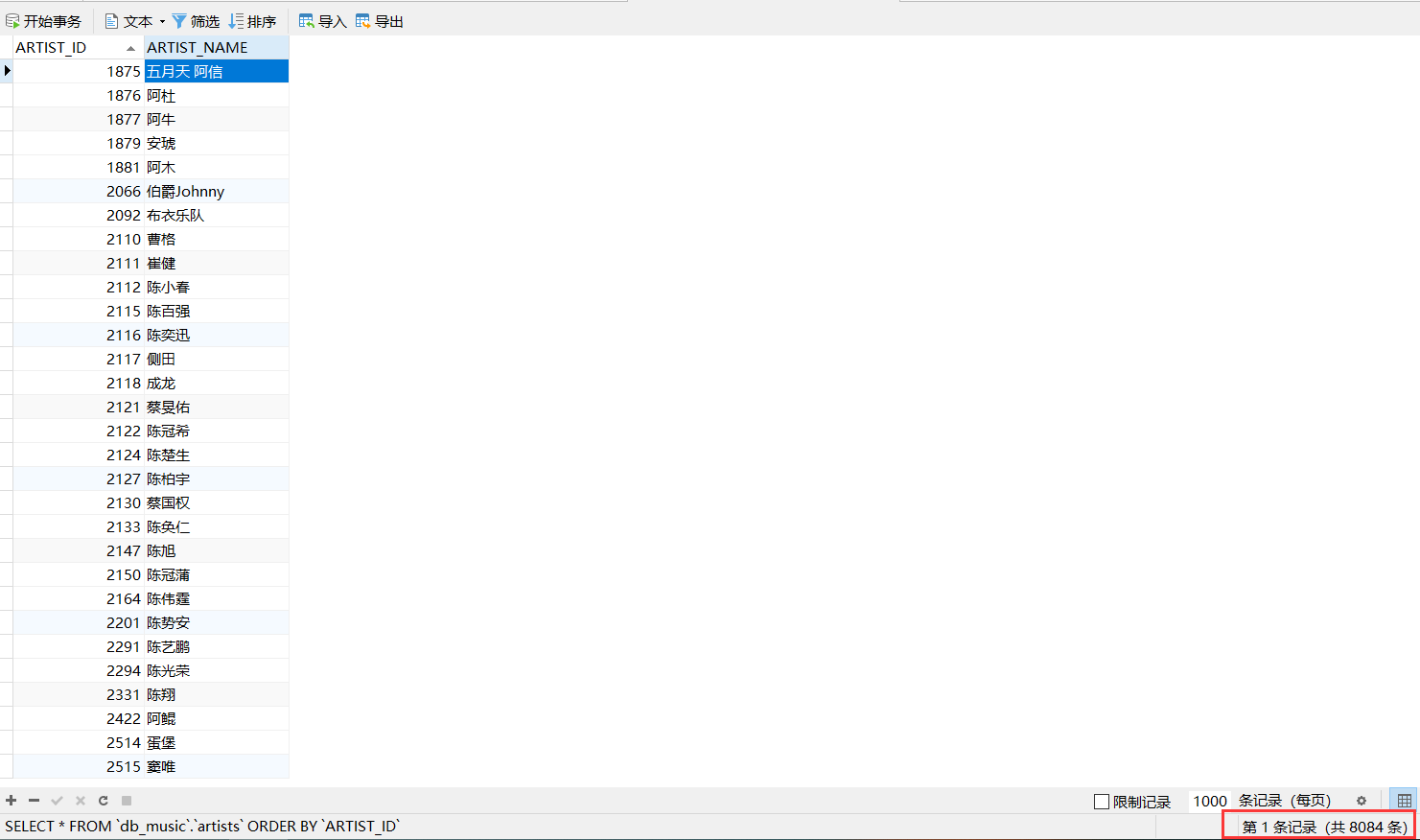
我们以爬取华语男歌手、华语女歌手、华语组合/乐队为例(group_id为1001、1002、1003)
总计爬取到8084条记录,存入数据库如图所示:
歌手页面分析
歌手页面的 URL 格式如下:
https://music.163.com/#/artist?id=3684
{ id=3684 } 代表歌手的ID,例如林俊杰为3684,周杰伦为6452
该页面包含了大量歌手信息,歌曲信息,而我们本项目只需要获取50首热门歌曲的名字和ID即可
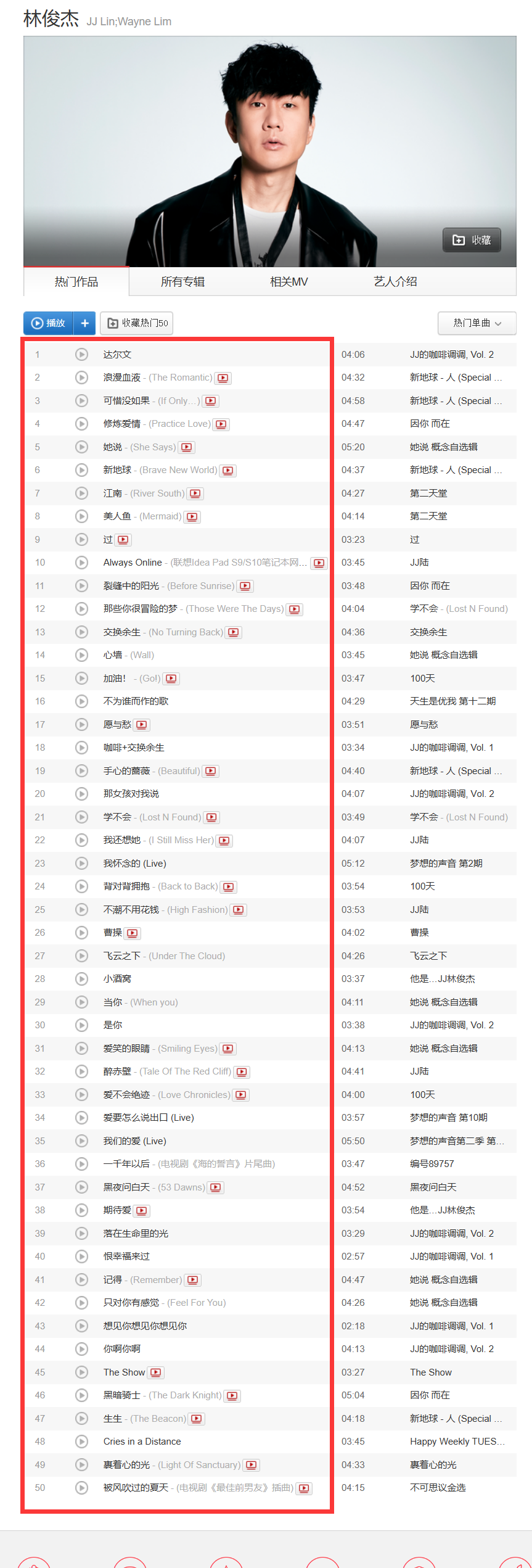
这里我们使用lxml的Xpath进行解析获取,主要代码如下
r = requests.get('https://music.163.com/artist', headers=self.headers, params=params)
r.encoding = "utf8"
# 网页解析
tree = etree.HTML(r.text)
# 获取歌曲ID以及歌名
hrefs = tree.xpath("//*[@id='hotsong-list']//a/@href")
names = tree.xpath("//*[@id='hotsong-list']//a/text()")
歌曲信息分析
歌曲信息页面的 URL 格式如下:
https://music.163.com/#/song?id=2019573476
{ id=2019573476} 代表歌曲的ID,例如林俊杰的达尔文为2019573476,修炼爱情为25727803
我们通过分析该页面可以看到,该歌曲的评论数就显示在下方,理论上我们可以同上使用BeautifulSoup 或者Xpath进行获取,但是实际上由于该数据是页面动态请求后返回的,所以我们不能直接获取,需要再次进行模拟请求。
通过使用开发者工具观察网络,发现请求地址如下
https://music.163.com/weapi/comment/resource/comments/get?csrf_token=
同时他还携带了两个参数:
params: Xl4hXCB41qv+XmMf2on7QDmUQ8lxSwOu6zN8J6JXP8pAFX5f7jJSwvLOk+AIhDS8/0BLQKzY2NIbXx+bj+9iLTZamxTxZs0D9krjrA85ZBB2TsEjSjPO3I8uZGCV4Vdfkmcv+svizQ3BfeJUxVHBJ7+a08l+buPPOKm+GEXT6cC6hQLZ4pDzx0xEPY/XSlM0tMaYAmYkKCfxFg9r3u6YtEC1x9rVlZMSMYmBVnI1E23zw5dEvjfS24RnRTzpE98alY6eTZ4kHmXRbgpLVxbAD1jaJRNnTTwFKkxTskJi+Ck=
encSecKey: 915d930066f14ec6048c1a4feaf1fc499b2bbd054e1178ceecd0272b981ba72acfb094dec17dd1e7e0ea748fa71e84cd2ce069fe3287971518e91b5fb5747408ecea5418bf0aba320bf7acaf042c7f8ff7aa78cbbc0e20a81a88b9a898c619cec900bd778c607a8a90ab4a81ac12eb4fee6acfe7eb196ad3f92da8839f4ecfa6
这两个参数是经过加密实时变化的,所以我们还要进行模拟加密的步骤,通过对JS逆向我们可以得到加密函数
这里为了减少工作量,不再赘述加密,解密的过程。具体步骤请参照:
爬虫抓取网易云热评——python实现 - 哔哩哔哩 (bilibili.com)
最后得到返回的数据为JSON格式,我们只需要其中的评论总数
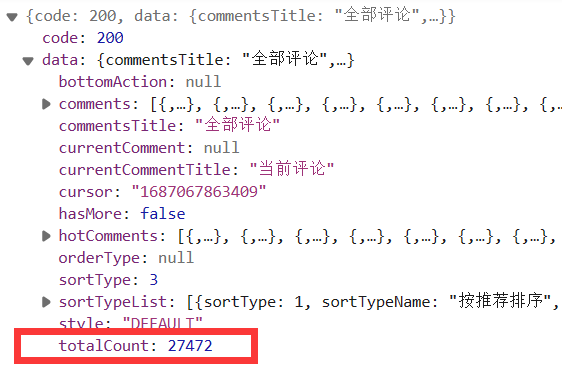
至此我们已得到全部想要的数据,将数据存入数据库,由于爬取全部数据量过大,我这只爬取部分歌手的歌曲
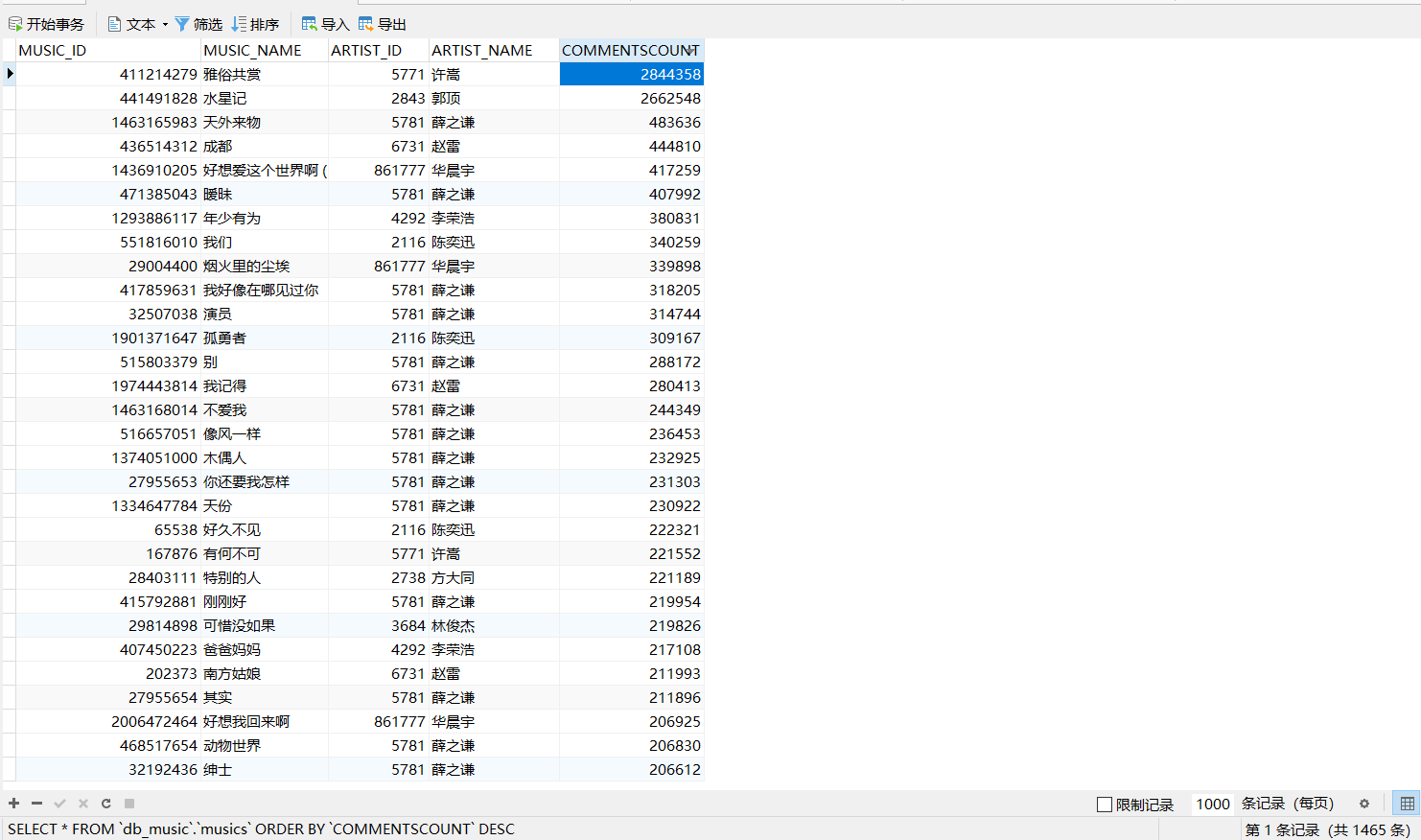
可视化
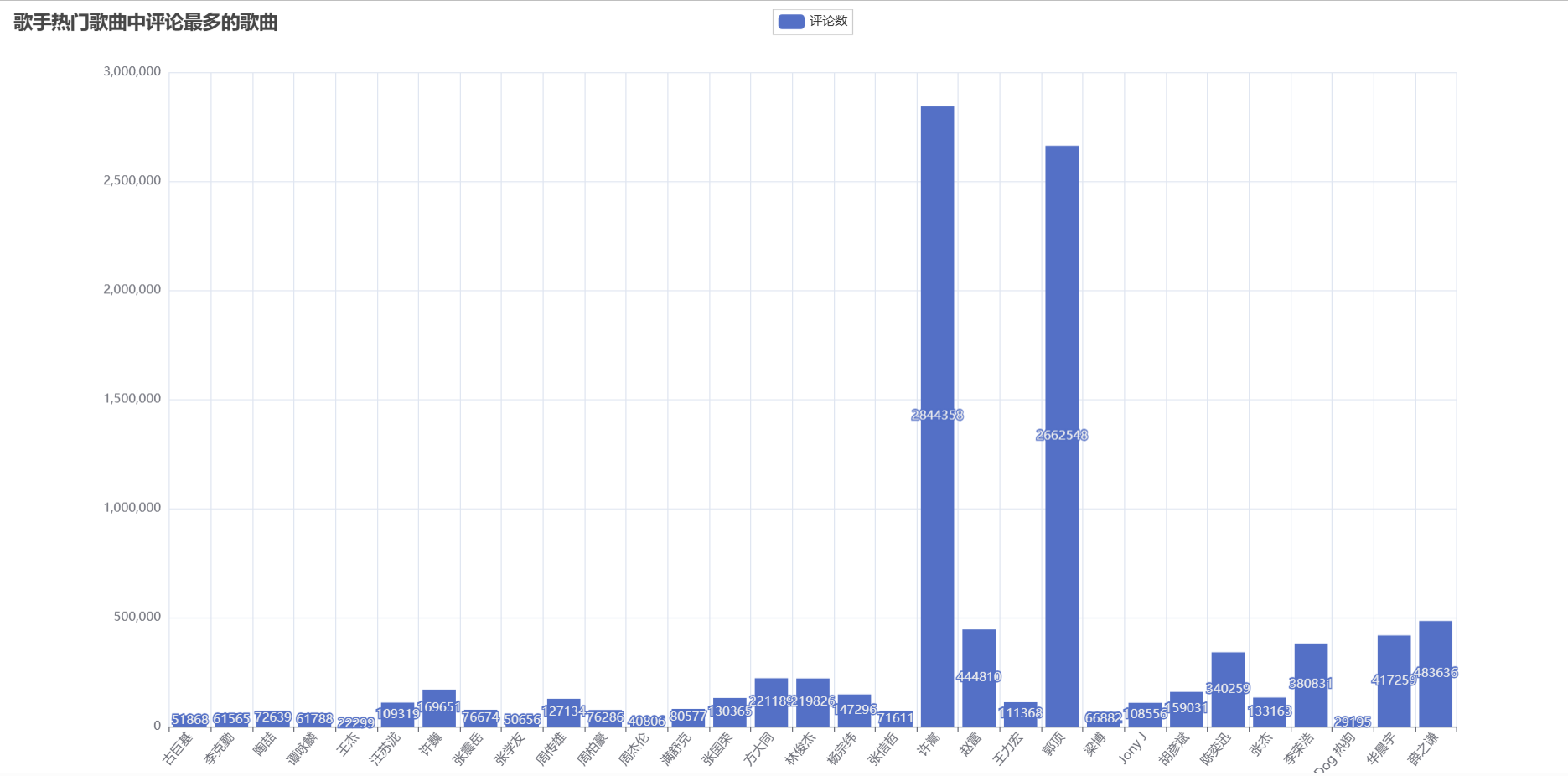
最后本项目使用 pyecharts 库将数据库中获取到的歌手热门歌曲中评论最多的歌曲可视化展现出来。
该可视化结果通过 Bar 类创建柱状图,通过 Web 服务器在浏览器端展示。
















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











