







基于python的电影票房预测系统设计与实现
摘 要
近些年来,随着电影行业变得越来越热门,也为影院带来不小的票房收入。传统的影院都是依靠个人经验进行排片,但是由于影片的票房收入可能受多种因素的影响,排片多的电影最后的票房会远低于预期值,导致影院因安排失误而导致大量的票房损失。
基于此背景下,众多的影院希望有一个票房预测系统能够预测电影的票房,为影院的排片进行指导,所以本文在了解了国内外研究现状后,在python语言的基础上,通过爬虫技术爬取中国电影网的各历史票房数据,利用多项式曲线拟合算法作为票房预测算法,实现了可对电影票房进行预测的python系统。
通过应用本系统,能够为国内的影院提供点映过一段时间的电影的预测票房,为影院排片提供有一定影响的参考依据,减少因人为因素对电影排片而导致票房损失的事情发生。同时本系统能够进行票房数据预处理以及模型训练等功能,因为目前电影的票房是用户选择观看电影的重要指标,所以系统还能够及时的变更票房的实时数据和预测数据,具有非常好的应用前景和使用价值。
关键词:多项式曲线拟合;电影票房预测;爬虫;python
Abstract
In recent years, with the film industry becoming more and more popular, it also brings a lot of box office revenue for the cinema. Traditional cinemas rely on personal experience to arrange films, but the box office revenue of films may be affected by many factors, and the final box office of films with more films will be far lower than the expected value, resulting in a lot of box office losses due to the wrong arrangement.
Based on this background, many cinemas hope to have a box office prediction system to predict the box office of the movie and guide the movie arrangement. Therefore, We analyze the research at home and abroad the python language, this paper crawls the historical box office data of China film website through crawler technology, and uses polynomial curve fitting algorithm as the box office prediction algorithm to realize the box office prediction A python system that can predict the box office of a movie.
Through the application of this system, it can provide domestic cinemas with the predicted box office of movies that have been shown for a period of time, provide reference basis for cinema film arrangement, and reduce the box office loss caused by human factors. At the same time, the system can carry out box office data preprocessing and model training, provide users with the trend of the box office, and effectively provide users with the prediction data of the box office, which has a very good application prospect and use value.
Keywords: polynomial curve fitting; movie box office prediction; crawler; python
目 录
一、绪论 1
(一)研究背景 1
(二)国内外研究现状 1
二、相关技术 1
(一)电影票房预测的相关方法 2
1.基于人口统计学的研究方法 2
2.基于MAAP评级的电影票房预测模型 2
(二)网络爬虫介绍 3
1.网络爬虫概述 3
2.页面爬取 3
3.页面存储 4
三、基于python的电影票房预测算法设计 4
(一)数据来源 4
(二)票房预测算法——多项式曲线拟合 4
四、电影票房预测系统需求分析 6
(一)电影票房预测系统总体概述 6
(二)电影票房预测系统功能性需求 6
1.网络爬虫子模块 6
(三)电影票房预测系统非功能性需求 7
五、电影票房预测系统设计 7
(一) 电影票房预测系统整体架构 7
(二) 数据的爬取与清洗子模块 8
(三)数据存储子模块 9
(三) 票房预测子模块 9
六、电影票房预测系统实现 9
(一)系统整体架构实现 9
(二)网络爬虫子模块 10
(三)数据存储子模块 12
七、电影票房预测系统测试 12
(一)硬件环境配置 12
(二)软件环境配置 12
(三)Numpy库与Scipy库 12
(四)预测结果展示 13
1. 电影历史票房结果展示 13
2.电影票房多项式曲线拟合结果展示 13
3.电影预测票房结果展示 14
参考文献 15
一、绪论
(一)研究背景
近年来,随着生活水平的提高,人民在解决温饱问题后,对生活中的娱乐项目越来越重视,这意味着恩格尔系数降低而娱乐消费增加。电影在娱乐消费中的占比是非常高的,一部好的电影在世界各地广为流传,电影通过短短的几个小时向人民传递了太多信息,这些信息不仅是时事热点还有更多精神方面的启示。制作一部电影通常需要花费很多物力和财力,大家现在默认的把票房作为一部电影是否成功的标准,因为票房是投资者决定是否投资该电影的重要指标。那么怎么对票房进行一个精准的预测呢?精准的预测能够更好地说服投资者进行投资。我国文化娱乐产业的发展必然是随着经济实力的提升而升温的,在对国家新闻出版广电总局电影局的票房数据进行分析后得到以下信息:
1.2007年全国总票房为21亿,十年之后2017年票房翻了20倍以上为457.12亿。
2.2016年全国总票房为440.8亿,一年之后2017年票房仅增加3.7%。
3.2018年全国总票房为559亿,比2017年票房增加13.45%。
以上数据都说明了票房的增加的前提是迎合观众对电影类型的偏好,2017年前后我们能发现票房数据有了质的飞跃,这得益于在2015年电影票房预测的流行。这篇文章将结合传统的电影票房预测方法和使用python等大数据分析,从而提高电影票房预测的精准度。
(二)国内外研究现状
经过研究大量的与电影票房有关的各种文献,我们很容易发现西方在该方面的理论体系更为完整,因为西方在工业革命后经济飞速发展,而我国还处于闭关锁国的状态,但是因为改革开放后我国经济有了极大的提升,所以我国也开对电影票房的研究投入了更多的精力。
电影票房预测从美国开始,最初的研究是通过对观众发放调查问卷,大家把这种研究称为“观众研究”,目的是通过对观众的电影类型票好进行简单的收集以此促进电影票房的增加。里奥德尔是电影研究局的工作人员,他和观众调查局的乔治盖洛普是“观众研究”的著名研究人员,但是他们用来采集和分析观众偏好的方法并不相同,但目的都是为了对票房产生影响和预估。他们为什么在众多研究者中脱颖日出呢?这是因为他们发现了影响票房的因素是非常多的,例如对电影的宣传程度、演员的知名度、观众的口碑以及电影所讲述的故事等,这些因素在后来的研究中被分析的更加透彻。不久之后,巴瑞李特曼第一次提出运用线性回归建立一个电影收入预测模型,该模型的自变量和因变量分别是对票房产生影响的因素和电影票房收入。从二十一世纪初开始,互联网将全球连接起来,人与人之间的交流范围更加广阔的同时也意味着原来的电影票房的预测已经不在适用于当下。于是研究人员不在使用之前的研究方案,改变为在网络上对关于电影的评论进行一个汇总,构建一个更加精准的票房预测模型,于是微博、谷歌、推特等预测模型随之而来。
二、相关技术
本章主要介绍基于python的电影票房预测系统在从思路变为实际成果的有关方法和核心技术,它的包含范围极广,从胶片时代开始直到现在,我们对票房预测所使用过的各种方法直到互联网覆盖而通过网络爬虫获取的相关信息。
(一)电影票房预测的相关方法
1915电影还处于胶片时代,票房预测开始萌芽,直到1960年研究者对于预测方法都处于探索阶段,从1980年开始,因为全球经济的进步,票房预测也进入了发展阶段。不管是在萌芽阶段和探索阶段研究者都用了大量的预测方式。
1.基于人口统计学的研究方法
美国是第一个对电影票房进行研究的国家。美国在二十年代末经济属于虚假繁荣,在经济快速发展的假象下美国对电影发展投入了大量资本,可见美国电影进入了黄金时期,到了四十年代,科技进行了新一步革新,为了迎合观众喜好,对电影票房的研究也随之产生。对电影票房研究进行促进原因有:
1、科技使人们的娱乐方式变得更加广泛,人们能够在家里通过看电视获得更多的信息,于是对电影的需求降低,电影的销售到达了一个低谷。电影的投资成本极高,如果电影不能获得收益,那么投资者不会对电影进行注资,因此电影制片方开始对票房进行关注,而最能说服投资方的就是电影票房,电影票房预测变成了一个重要指标。
2、美国是一个民主国家,极其重视民意。电影主要面向的是观众,所以观众的偏好决定了票房的走向,同时民意测验受到多个企业的推崇,因此电影业也随着潮流开始研究观众的偏好和寻找影响票房的因素。
3、电影刚刚出现时,极少有人重视它的发展,为了电影这一娱乐方式在群众中流行起来,好莱坞通过与电影研究者们进行合作进而改变现状,研究者们得到了制作公司提供的大量的数据和资料,与此同时他们开始进行了观众调查,希望结合数据和调查能够发现影响票房的因素,进而完善因素达到对电影票房提高的目的。但是一项重大的发现并不是能够轻易获取的,研究者们仅仅关注到了它们产生的独立影响,并没有发现它们的内在联系,所以不能构建模型。虽然在这个时期对预测模型的构建并没有成功,但是也出现了预测模型研究的里程碑——人口统计学的截面调查法,它是由乔治盖洛普所提出的,他也是观众研究中的著名研究者。
截面调查法主要是截面取样,也可以称为定额取样,调查人员的定额是通过总体的结构特征进行分配的,目的是得到与总体的结构特征差不多的样本。例如反映总体的信息主要是通过人口的年幼程度、男女性别来给调查人员规定了年龄不同、性别也不同的被调查人数,在使用这种抽样方法时应该注意要准确的认识总体元素存在的结构特征,这是为了使定额的选择更为准确从而使样本具有代表性。研究者盖洛普也是观众研究中的一员,在使用民意调查法时为了使数据更加的真实、可靠,他会对数据进行筛选保证样本的代表性,他主要是在采样时考虑了更多的因素,这些因素的分类也更为细致。因此盖洛普的研究中,电影票房影响因素包有电影的片名、演员知名度、电影试映的效果、电影内容以及电影宣传。
2.基于MAAP评级的电影票房预测模型
在二十世纪八十年代,电影票房的研究也进入到了第二阶段,第二阶段的研究在第一阶段的前提下转变为发现更多的影响电影票房的因素。代表第二阶段研究的开始有很多,斯格特.苏凯提出的预测模型是真正的能够代表研究开始的标志。此预测模型基于第一阶段票房预测,增加了两个因素分别是是否获得奥斯卡奖项和MAAP评级,而建模方法上也有改变,主要是用回归分析的这一模型来构造电影票房的影响因子与收入之间的联系。
乔治盖洛普的模型被斯格特苏凯进行了改进,但是票房数据的获取并不是一件容易的事,所以苏凯找到了代替电影票房数据的方法——电影租金变量,苏凯的模型预测的范围更广,例如电影租金、电影的持续放映时间也称为放映周数。苏凯在选取电影票房影响因子上设置了22个影响因子,把市场集中度列入了影响因子之一是最重要的改变。我们一般把不同放映时期的市场竞争度称为市场集中度,它的计算公式是:市场集中度=上映时期排名前四或排名前十电影的一周票房/本周所有电影总票房,当最后得到的数值越大时,市场集中度相应的越高也就意味着本周内上映的电影市场竞争力越大。回归方程对观测值的拟合程度我们称为拟合优度,其中判定系数R2是度量拟合优度的统计量的依据,它是回归平方和与总偏差平方和之间的比值,当判定系数越大时,则离平方和中能够由回归平方和解释的比例就越大,对模型的预测相应的就越精确,回归效果就更好。从数值方面当R2大于0小于等于1时,回归拟合的效果就越好,模型的拟合优度R2大于0.8时属于拟合度较好。
(二)网络爬虫介绍
大数据在现今使用的范围越来越广,网络爬虫是其中的重要组成。它是指一种按照固定的移动规则,自主的抓取万维网中信息的运行的程序或者是程序的脚本。
1.网络爬虫概述
网络爬虫技术在功能上分为了数据采集、数据处理以及数据存储。我们一般把从一个以及一个以上初始网页的URL称为传统的抓取工具,URL的获取是在最开始的网页上,我们在对网页进行抓取网页时,而新的URL是在对网页进行抓取时不断的被提取,只有满足系统停止条件是才会暂停抓取。爬虫工作是十分繁琐的,它需要的基础条件非常多,需要通过Web分析算法筛选掉很多无关的信息,而有用的链接就进入等待爬虫的URL队列中。接下来,它会在等待序列中搜寻到需要进行爬取的网页的URL,它会一直反复循环该爬取过程目的是找到符合系统的条件。除此之外,系统将会对爬虫爬取到的所有网页进行分析、存储、索引和过滤,这大大的方便了数据查询和变更。
2.页面爬取
我们在访问大多数网站时都需要登录,登录后我们才能对网站信息进行爬取。我们在登录时通常使用cookie,对它进行解释就是互联网所产生的页面,http协议运行的,然而http协议虽然是它运行的基础,但是它是一个无状态、无法维持会话以及无法保存的状态。它主要表现在登录网站后,对该网站进行多方面的访问时,登录状态会发生改变甚至直接掉线,可是它的重新登录时非常麻烦的,因为网页会不断更新,而重新更新的页面我们都需要登录,因此保存登录信息cookie和session是十分重要的。cookie可以对所有的会话信息在客户端进行保存,这个时候访问同一个网站的其他网页时,就直接从cookie中提取到之前保存的相关会话信息;我们使用session时,它可以直接把相应的会话信息都保存在服务端,而存在客户端的cookie信息中还存在处于服务端的session、id等信息,用户打开同一个网站的其他网页时,我们在cookie中读取到相关信息时便是通过session、id搜寻到服务器中对应的完整的session信息进行会话控制。综上,cookie是访问任意网站的基础。综上所述我们在使用爬虫进行信息获取时,通常用python中的urllib方法保存已经登录的cookie,该种方法可以自己进行页面信息的爬取,自主选择re、bs4、lxml中的一种解析方法读取保存的源代码并进行解析,最后成功找到目标数据所在的特定标签,进行网页结构的解析。
3.页面存储
当得到解析的数据后,定义函数把获取的目标数据保存到csv文件中,最后使用框架式流程结构,通过参数传递实现整个数据的爬取。
三、基于python的电影票房预测算法设计
(一)数据来源
本文主要使用了电影基本和电影票房两个数据,数据均来源于中国票房网,主要包括电影基本信息,电影发行时间以及历史票房数据,从表3-1中可以直观看到具体数据所示:
表3-1 初始数据表
电影数据类别 基本信息 发行时间 历史票房数据
数量 10 2015年-2018年 1587
(二)票房预测算法——多项式曲线拟合
通过对斯格特苏凯的基于MAAP评级的电影票房预测模型学习,本文提出算法:对历史票房数据进行多项式曲线拟合,建立一个票房走势的“模型”,再把现有的票房套进模型里做计算。
多项式函数拟合是把给定数据是由M次多项式函数生成的作为一个假设,M次多项式函数并不是都会产生给定数据,这需要我们进行选择,应当选择的是一个不管是对已知数据还是未知数据都有较好预测能力的函数。
最小二乘法是在数学上命名为曲线拟合,它寻找数据的最佳函数匹配是运用最小化误差的平方和,最小二乘法的优点是对于求出未知数据更加的方便,而且这些求得的数据与实际数据之间误差的平方和是最小的。最小二乘法对于曲线拟合的具体原理如下:
假设训练数据集是:
是属于输入x的观测值,而则是相应的输出y的观测值,其中i=1,2,⋯,N
设M次的多项式是
其中,x是单变量的输入,是M+1个参数。
当损失函数(即最小二乘法)是平方函数时,系数的意义是为了使计算更加简便,把模型与训练数据代入可以得到:
对wj求偏导并令其为0
以上公式最后一步存在一处错误:等式左边x指数为(j+k)
必须对多项式系数进行拟合,解线性方程组,得到下面的求和符号上下限都是i=1到N,为了直观所以直接省略书写步骤。
通过计算,得出:
把上面的值带入线性方程组求解即可得出答案。
将数据代入上述研究方程即为:将某一对比电影历史票房和预测票房电影的前期票房作为输入,通过图像显示处理,利用多项式曲线拟合与预测票房电影训练模型,最后预测出票房。具体代码如下:
#多项式拟合
def draw_fit(data):
x = np.array(range(len(data)))
z = np.poly1d(np.polyfit(x, data, 10))
plt.plot(x, z(x), ‘r-’)
return z
plt.figure(figsize=(22, 12))
func_fits = []
for i in range(9):
plt.subplot(3, 3, i+1)
y = data[title[i]].dropna().tolist()
x = [i for i in range(len(y))]
plt.title(title[i], fontproperties=font) #图标题
plt.plot(x, y) #绘图
z = draw_fit(y) #绘制拟合曲线
func_fits.append(z)
plt.show()
四、电影票房预测系统需求分析
本章第一步主要是对电影票房预测系统的功能做了一个全面的讲解,接下来对系统的功能需求和非功能需求进行了逐步的介绍。
(一)电影票房预测系统总体概述
电影票房预测系统主要是为了对我国所有上映的电影票房进行一个有效的预测,这样更能使投资者或者是观众对电影的选择更为便利。电影票房预测系统进行预测的结构框架是:第一步从中国电影网上爬取电影的基本信息和票房,并对爬取的数据进行分析,经过一系列操作后存储为csv文件。下一步为预测模块,该板块是运用预测算法来训练票房预测模型的同时对票房进行更为精准的预测,最终得到最后的票房结果。
电影票房预测系统分别为网络爬虫子模块、数据存储子模块和电影票房预测子模块。网络爬虫子模块主要完成对中国票房网的真实数据的爬取和预处理,数据存储模块将爬取的数据转换为可输入模型的数据,电影票房预测子模块是本文的核心模块,也是本文的研究重心,主要采用的是基于多项式函数拟合算法的框架模型,以最小二乘法的结果为输入,最终由预先训练好的模型输出票房预测值。
(二)电影票房预测系统功能性需求
电影票房预测系统由三个不同的模块组成的,这三个模块负责不同的分工,在三个模块得出数据后,进行总结得到了预测结果。现在先对第一个模块网络爬虫子模块的功能性需求进行分析。
1.网络爬虫子模块
为了能更准确的进行票房预测,需要大量的统计票房数据,中国电影票房的数据主要来源于中国票房网,由于人为的统计极其的繁琐和容易出错,所以网络爬虫子模块也因此而来,它的功能性需求主要是对在数据进行爬取的同时完成预处理。网络爬虫子模块中数据大多都是结构化的文本数据(包括的是中国电影网的影片名,影片发行时间,影片历史票房),并不是所有获取的信息都是有用信息,数据预处理主要是对信息进行筛选,筛选的主要的内容是;
(1)去掉重复数据:确保影片信息的单一性,防止影片的数据有重复,导致结果出现误差。
(2)特殊符号处理:特殊符号包括表情符号以及外部URL链接等。
(3)检验有效性:有些影片信息在经过数据去重和符号处理后,当剩下的文本内容有效时就存入字典并输出到下一模块的输入接口,当无效时就视为检验无效。
(三)电影票房预测系统非功能性需求
性能需求以及可维护性需求都属于非功能性需求的范畴。
性功能需求是为了给使用者一个运行快速的同时数据也更加准确的体验,相应的对系统性能是否优劣的判断中通常以运行速度为主,所以对算法进行了精简以及对需求数进行了一定降低。
在系统中的开发各种原理必须要符合标准化编码原则,这里引出可维护性需求这一概念,它存在的意义就是让开发的系统能够更好的遵从原则,也可以理解为对开发系统的可维护性性。一个系统的完成必然需要多个人员进行合作,因此在开发的过程中为了提高效率对代码的规范以及接口的设计做了要求,这样便于当系统出现差错时能够快速发现问题所处位置,使问题能在最短时间内解决。开发的系统具有广泛性,也就是并不是单一的针对一个简单预测,为了提高系统的灵敏性,在对算法进行编制后可以通过最简单的改动后实现精确预测。
五、电影票房预测系统设计
第四章本文对电影票房预测系统的需求分析进行了阐述,本章则是在进行需求分析后对系统的总体设计和实现方案进行一个确定,主要是指电影票房预测系统的数据爬取子模块和清洗子模块、数据存储子模块以及票房预测子模块。
(一)电影票房预测系统整体架构
如图5-1所示:

图5-1 电影票房预测系统整体框架图
电影票房预测系统首先从中国电影网上对按照时间戳对电影的基本信息和票房进行爬取,通过数据清洗得到相关数据,然后将所收集到的电影相关信息保存为csv文件,然后将文件数据进行多项式曲线拟合,建立一个票房走势的模型,最终进入预测模块,把现有的票房套进模型里做计算并进行票房预测,最终输出票房结果。其中的数据爬取与清洗子模块、数据存取子模块和票房预测子模块将在下面进行详细讲解。
(二)数据的爬取与清洗子模块
如图5-2所示:
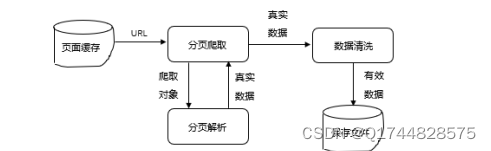
图5-2数据爬取与清洗子模块流程图
第一步是通过URL对缓存的页面分页爬取,然后通过对缓存页面的爬取对象科学分析后得到真实数据,同时在对真实数据进行清洗后,就得到了有效数据,最后保存文件就完成了数据的存储。
(三)数据存储子模块
按照时间戳爬取到电影相关信息及数据,清洗后得到有效数据,通过Python中Pandas库中的DataFrame函数设置列名columns与行名index,分别用于存储电影名与历年票房,然后转置并存储为csv文件作为预测模型的输入。
(三)票房预测子模块
如图5-3所示:
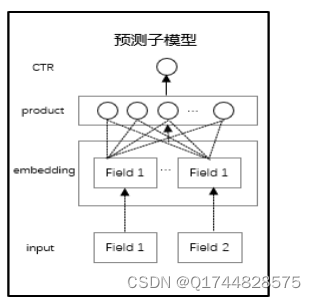
图5-3票房预测子模块流程图
将经过处理的csv文件数据输入模型,然后进入embedding层,对某个电影的票房做多项式曲线拟合操作建立模型,然后将预测电影的前期票房信息与诸模型两两交叉进入product层,最终输出票房结果。
六、电影票房预测系统实现
本章是对电影票房预测系统中的整体架构以及其部分关键模块的详细实现进行一个介绍,主要分为三个模块,网络爬虫子模块、数据存储子模块和电影票房预测子模块。该流程中特别注意的是,电影票房预测的最终功能模块是以多项式曲线拟合算法为基础实现。
 图6-1电影票房预测系统整体流程图
图6-1电影票房预测系统整体流程图
上图6-1展示了电影票房预测系统的整体流程图,上图给出的预测系统中有网络爬虫子模块、数据存储模块以及电影票房预测子模块。其中网络爬虫子模块主要完成对中国票房网爬取和预处理,由于数据可能重复或没有任何作用,为了使系统预测更加准确,于是必须要对数据预处理;数据存储子模块的作用是清理后的数据进行特殊处理,使数据可以成为预测模型的合理输入,存储的文件为csv文件;电影票房预测子模块是本文阐述以及研究的重要部分,该模块是运用多项式曲线拟合算法的基本框架,把数据存储子模块的输出作为输入,最后通过预先训练好的模型来输出票房的预测值。因为前面已经对票房预测模块进行了解释,因此下面只对网络爬虫和数据存储这两个功能模块的实现进行详细的介绍。
(二)网络爬虫子模块
如图6-1:

图6-2网络爬虫子模块流程图
由6-2可以得到流程如下:
(1)当系统初始化爬虫代理后可以操作浏览器令其模拟人类行为,得到目标网址的root,进入到本文的数据主要来源的中国电影网。其中虫代理设置包括浏览器支持的MIME类型(ACCEPT)、用户代理(USER_AGENT)两个部分,具体设置如下:
def getMovieURL(url):
headers = {
’ Chrome/67.0.3396.62 Safari/537.36’
try:
r = requests.get(url, headers=headers)
except requests.RequestException as e:
print('error', e)
def main():
uinfo = []
for i in range(11):
urls = {"http://58921.com/daily/wangpiao?page= " + str(i)}
for url in urls:
html = getHTMLText(url)
fillUnivList(uinfo, html)
printHtml_csv(uinfo)
(2)在ROOT_URL页面中循环的按页根据展示位置来获取所有的movieURL存入到MovieUrlList栈中,接下来使用GetMovieUrl函数令桟顶元素取出,判断它的有效性,当无效时栈为空,爬取结束,跳转到第4步…;当有效时,直接进入某电影的页面,如下获取特定电影展示页面中影片名与历史票房的信息,存储在数据结构ulist.append([tds[1].string,tds[6].string])中,从而定位到需要爬取的数据。
def MovieUrlList (ulist,
printHtml_csv(ulist):
with open(‘data.csv’, ‘w’, encoding=‘utf-8-sig’, newline=‘’) as csvfile:
fieldnames = [‘电影名称’,‘票房’]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for i in ulist:
writer.writerow(
{‘电影名称’: i[0], ‘票房’: re.findall(‘/^\d*(.)?\d+$/’, i[1])})
(三)数据存储子模块
通过Python中Pandas库中的DataFrame函数设置列名columns与行名index,分别用于存储电影名与历年票房,然后转置并存储为csv文件作为预测模型的输入。
数据储存
edf = pd.DataFrame.from_dict(mo, orient=‘index’)
edf = edf.T # 转置
edf.to_csv(os.path.abspath(‘.’) + r’/boxoffice.csv’, sep=‘,’, encoding=‘utf_8_sig’, index=False) # 保存到 csv
七、电影票房预测系统测试
(一)硬件环境配置
处理器 英特尔Core I5 CPU双核
客户端PC 负责用户界面交互
硬盘大小 1T
内存大小 8G
(二)软件环境配置
测试机客户端操作系统 Windows 10旗舰版
服务器使用操作系统 Cent OS 6.0
主要编程语言 Python 3.7
(三)Numpy库与Scipy库
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,该库在能够对数组运算提供大量的数学函数库的同时还可以计算大量的矩阵与维度数组。
Scipy是在Python的NumPy扩展上构建的数学算法和方便函数的集合。它通过为用户提供高级命令和类来操作和可视化数据,为交互式Python会话添加了强大的功能。有了SciPy,交互式Python会话就变成了一个数据处理和系统原型环境,可以与MATLAB、IDL、Octave、R-Lab和SciLab等系统相匹敌。
本文利用numpy库中的polyfit方法和Scipy库中optimize模块的leastsq函数进行多项式曲线拟合,建立票房预测模型,并最终预测票房。
(四)预测结果展示
本次预测的电影为哪吒之魔童降世,建立的模型采用大圣归来等9部电影,并最终选取大圣归来作为预测结果拟合值。
1.电影历史票房结果展示
测试过程中,通过爬虫技术获得电影数据票房信息并经过数据清洗后,保存为csv文件,并且如图7-1所示通过matplotlib库的plt函数对csv文件中的九部电影票房数据进行可视化展示,其中横轴表示时间,纵轴为票房,图表中绿色的曲线表示的就是票房数据的变化趋势。

2.电影票房多项式曲线拟合结果展示
获得票房数据后,通过numpy库中的polyfit方法对数据进行多项式曲线拟合,如图7-2所示7-2所示,蓝线为电影历史票房趋势图,红线为多项式曲线拟合后的模型变化趋势。

3.电影预测票房结果展示
如图7-3和7-4所示,蓝线表示前10天哪吒之魔童降世电影票房的数据展示趋势,红线为西游记之大圣归来的多项式曲线拟合趋势图,并得到该趋势的拟合参数为0.5931,将哪吒之魔童降世的数据代入此模型计算,最终预测出总票房为275949万元。


参考文献
[1]席一锴.基于机器学习算法进行电影票房预测[J].电子制作,2021(04):51-52+55.
[2]李振兴. 机器学习在电影票房预测中的应用研究[D].西安石油大学,2020.
[3]刘宁. 基于网络数据的电影票房预测模型研究[D].天津商业大学,2019.
[4]富泽萌. 基于社交网络分析的电影票房预测系统的设计与实现[D].北京邮电大学,2019.
[5]蒙晓庆. 中国电影票房影响因素分析及预测[D].天津财经大学,2018.
[6]周杰,梁佳雯,何加豪.居民对国产科幻电影的消费舆情分析及票房预测——以《流浪地球》为例[J].中国集体经济,2020(34):142-144.
[7]高钟瑞. 国产电影票房预测的实证分析[D].暨南大学,2020.
[8]宋维才.颠覆、混搭与彻底的娱乐精神——《哪吒之魔童降世》票房奇迹成因探析[J].中国电影市场,2019(11):21-23.
[9]韩忠明,原碧鸿,陈炎,赵宁,段大高.一个有效的基于GBRT的早期电影票房预测模型[J].计算机应用研究,2018,35(02):410-416.















 1469
1469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









