







欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景
声纹识别,又称说话人识别,是一种基于语音信号中的声纹特征来识别说话人身份的技术。随着人工智能和深度学习技术的飞速发展,声纹识别技术已广泛应用于身份认证、语音助手、智能家居等领域。然而,传统的声纹识别方法往往存在准确率低、鲁棒性差等问题。为了克服这些问题,本项目基于TensorFlow框架和卷积神经网络(CNN)技术,构建了一个高效、准确的声纹识别系统。
二、项目原理
本项目采用TensorFlow深度学习框架,结合卷积神经网络(CNN)模型,实现声纹识别功能。首先,对输入的语音信号进行预处理,包括降噪、分帧、特征提取等操作,提取出语音信号中的关键特征。然后,将提取的特征输入到CNN模型中进行训练。CNN模型通过多个卷积层和池化层的组合,学习语音信号中的深层次特征,进而实现对不同说话人的分类。最后,通过全连接层将学习到的特征映射到不同的说话人身份上,输出最终的声纹识别结果。
三、系统实现
数据准备:收集包含多个说话人语音的数据集,并进行标注。数据集应包括说话人的身份信息、语音内容等。同时,对语音数据进行必要的预处理操作,如降噪、分帧等。
模型构建:使用TensorFlow框架构建卷积神经网络(CNN)模型。模型应包含多个卷积层、池化层和全连接层,以提取语音信号中的深层次特征并进行分类。
模型训练:将预处理后的语音数据输入到CNN模型中进行训练。在训练过程中,可以使用适当的损失函数和优化算法,如交叉熵损失函数和Adam优化算法,对模型进行优化。同时,可以采用数据增强技术,如音频变速、变调等,提高模型的泛化能力。
模型评估与调优:使用独立的测试数据集对训练好的模型进行评估,计算模型的准确率、召回率等指标。根据评估结果对模型进行调优,如调整模型结构、参数等,以提高模型的性能。
系统集成与部署:将训练好的CNN模型集成到一个完整的声纹识别系统中,包括语音输入模块、模型推理模块和结果输出模块等。系统应支持实时语音输入和识别,并能够将识别结果以可视化或文本形式输出给用户。
四、系统特点
高效性:基于TensorFlow框架和CNN模型的声纹识别系统具有较高的识别准确率和较快的识别速度,能够满足实时性要求较高的应用场景。
鲁棒性:系统对噪声、口音、语速等变化具有较好的鲁棒性,能够在不同环境下保持较高的识别准确率。
可扩展性:系统采用模块化设计,易于扩展和集成其他功能模块,如语音识别、情感分析等。
用户友好性:系统提供直观的用户界面和友好的操作体验,用户只需简单操作即可完成声纹识别任务。
二、功能
深度学习之基于TensorFlow卷积神经网络声纹识别系统
三、系统


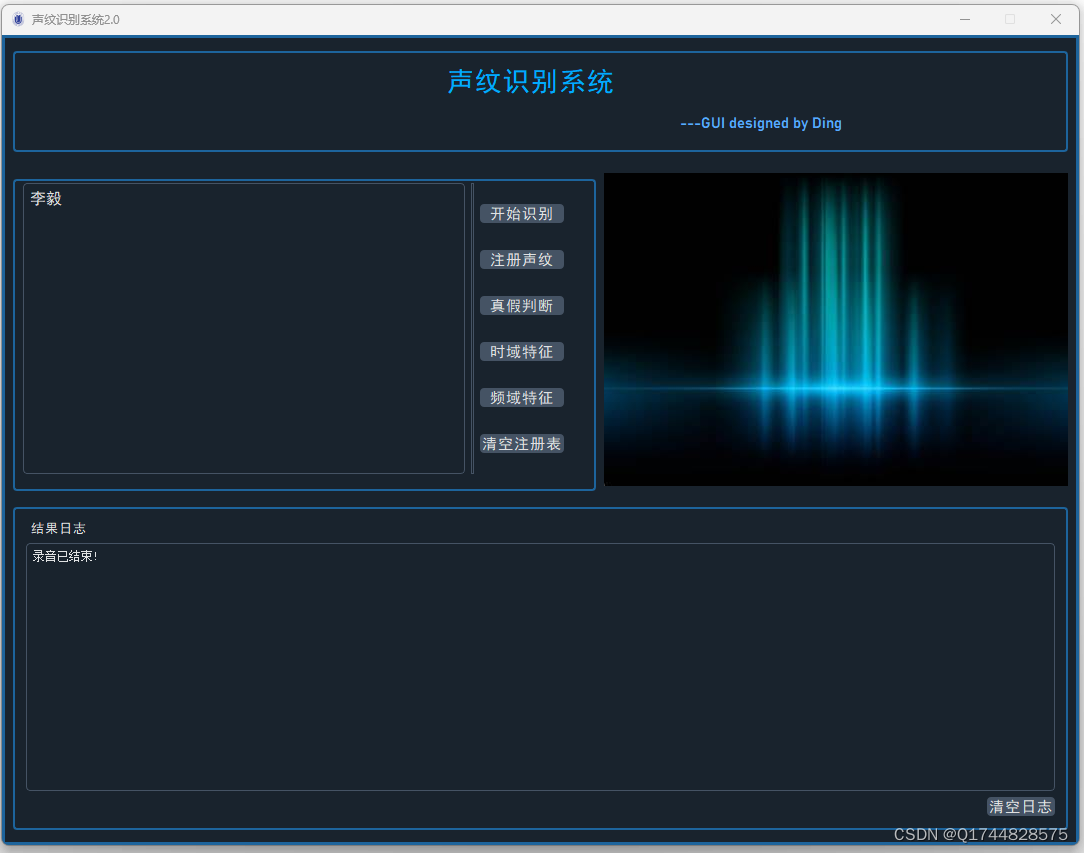
四. 总结
基于TensorFlow卷积神经网络的声纹识别系统具有广泛的应用前景。在身份认证领域,该系统可以替代传统的密码或指纹识别方式,为用户提供更加安全、便捷的身份认证方式。在语音助手、智能家居等领域,该系统可以用于识别用户身份,并根据用户身份提供个性化的服务。此外,该系统还可以应用于安全监控、司法取证等领域,为相关领域的发展提供有力支持。















 2459
2459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









