







欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景与意义
在数字化和自动化的今天,文档扫描与识别技术变得尤为重要。然而,在实际应用中,由于文档的放置方式或拍摄角度等问题,扫描得到的文档图像往往存在倾斜现象,这会对后续的OCR(光学字符识别)过程造成很大的困扰,导致识别准确率的降低。因此,本项目的目标在于开发一个基于Python和OpenCV的倾斜文档扫描校正与OCR识别系统,以提高文档数字化的效率和准确性。
二、技术原理与实现
倾斜文档扫描校正
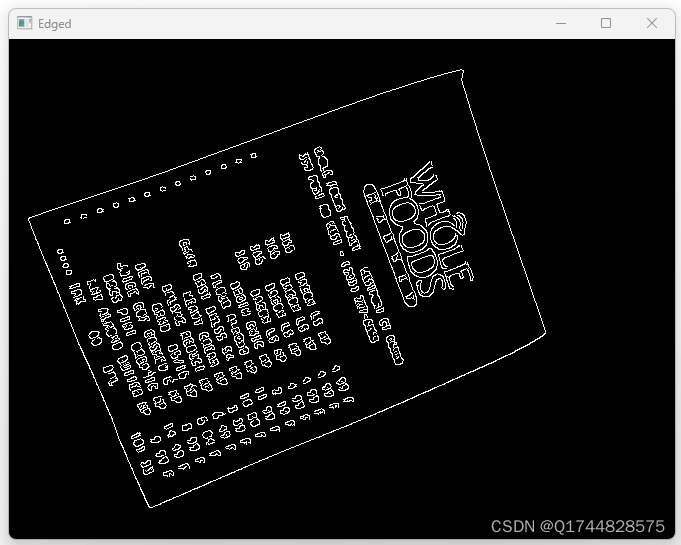
利用OpenCV的图像处理功能,首先对扫描得到的文档图像进行预处理,包括灰度化、滤波去噪、二值化等操作,以改善图像质量。
接着,通过霍夫变换(Hough Transform)等边缘检测方法提取出文档的边缘轮廓,确定文档的边界和四个顶点。
根据文档四个顶点的坐标信息,计算出文档的倾斜角度,并通过仿射变换(Affine Transformation)对图像进行旋转校正,使文档恢复水平状态。
OCR识别
在文档校正后,利用OCR识别技术(如Tesseract-OCR、Google Cloud Vision等)对文档中的文字进行识别。
OCR识别过程包括文本区域检测、字符分割、特征提取和分类识别等步骤。
根据识别结果,可以将文档中的文字转换为可编辑的文本格式(如TXT、Word等),便于后续的处理和分析。
三、项目特点与优势
自动化程度高:整个文档扫描校正与OCR识别过程无需人工干预,实现了自动化处理。
识别准确率高:通过倾斜校正和OCR识别技术的结合,有效提高了文档的识别准确率。
灵活性强:系统支持多种OCR识别引擎,可根据实际需求选择合适的引擎进行识别。
可扩展性好:项目采用模块化设计,便于后续的功能扩展和优化。
二、功能
基于Python+OpenCV倾斜文档扫描与OCR识别
三、系统


四. 总结
基于Python+OpenCV的倾斜文档扫描与OCR识别系统具有广泛的应用前景。它不仅可以应用于传统的文档数字化和存档工作,还可以用于电子表格识别、证件识别、发票识别等领域,提高数字化处理效率和质量。随着人工智能和计算机视觉技术的不断发展,该系统的性能和应用范围将得到进一步提升和拓展。















 5212
5212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









