







5.新的类功能
默认成员函数
原来C++类中,有6个默认成员函数:
构造函数
析构函数
拷贝构造函数
拷贝赋值重载
取地址重载
const 取地址重载
最后重要的是前4个,后两个用处不大。默认成员函数就是我们不写编译器会生成一个默认的。
C++11 新增了两个:移动构造函数和移动赋值运算符重载。
针对移动构造函数和移动赋值运算符重载有一些需要注意的点如下:
-
如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个默认成员函数。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
-
如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动赋值函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)
-
如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
演示
- String的类
#include<iostream>
#include<assert.h>
using namespace std;
namespace qwy
{
class string
{
public:
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
// 构造函数
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
//cout << "string(char* str)" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s1.swap(s2)
void swap(string& s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
// 拷贝构造
string(const string& s)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
// 赋值重载
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
// 移动构造
// 所谓的移动构造就是将s与将要构造的对象进行资源交换
string(string&& s)
{
cout << "string(const string& s) -- 移动拷贝" << endl;
swap(s);
}
// 移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string s) -- 移动赋值" << endl;
swap(s);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
private:
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0; // 不包含最后做标识的\0
};
// 将整数转化为字符串
string to_string(int value)
{
bool flag = true;
if (value < 0)
{
flag = false;
// 将value变为正数
value = 0 - value;
}
qwy::string str;
while (value > 0)
{
int x = value % 10; // 获取value的个位
value /= 10; // 获取value的十位及以上
str += ('0' + x); // 将x转化为对应的ascll值,并放入str
}
if (flag == false)
{
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}
}
class Person
{
public:
// 构造函数(缺省参数)(无参的构造函数)
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
// 按照我们上述所说,如果我们自己没有实现移动构造函数/移动赋值重载函数
// 并且我们同时不实现析构函数,拷贝构造函数,赋值重载函数,这三个默认成员函数,那么编译器就会自动生成一个默认移动构造函数/默认移动赋值函数
// 移动拷贝构造
Person(Person&& p)
:_name(std::forward<qwy::string>(p._name)) // 此处使用了完美转发,保持p._name的右值属性
, _age(p._age)
{}
// 拷贝构造函数
Person(const Person& p)
:_name(p._name) // 此处会调用String的拷贝构造函数
, _age(p._age)
{}
// 拷贝赋值重载函数
Person& operator=(const Person& p)
{
if(this != &p)
{
// 此处是String对象的赋值重载
_name = p._name;
_age = p._age;
}
return *this;
}
// 析构函数
~Person()
{}
private:
// _name是一个String对象
qwy::string _name;
int _age;
};
- 场景一(不会生成默认的移动构造或者移动赋值函数)
// 我们只要实现析构函数,拷贝构造函数,赋值重载函数的任意一个函数(或者同时实现都可以),
// 这样编译器就不会自动生成默认移动构造函数/默认移动赋值函数
// 对于场景一:同时实现了析构函数,拷贝构造函数,赋值重载函数
int main()
{
Person s1;
// s1是左值
// 左值会调用Person类的拷贝构造,其内部会调用String类的拷贝构造函数
Person s2 = s1;
// move(s1)是右值
// 对于场景一,编译器不会实现移动构造函数,此处会调用Person类的拷贝构造,其内部会调用String类的拷贝构造函数
Person s3 = std::move(s1);
Person s4;
// move(s2)是右值
// 因此Person对象S4已经存在了,所以此处会调用Person的赋值重载函数,其内部会调用String类的拷贝构造函数
s4 = std::move(s2);
return 0;
}
// 由于没有实现移动构造,所以都会拷贝构造函数
// 打印结果为:
//string(const string& s) --深拷贝
//string(const string& s) --深拷贝
//string& operator=(string s) --深拷贝
//string(const string& s) --深拷贝
- 场景二:
// 我们同时不实现析构函数,拷贝构造函数,赋值重载函数,这样编译器就会自动生成默认移动构造函数/默认移动赋值函数
// 默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用其移动构造,没有实现就调用其拷贝构造。
int main()
{
Person s1;
// s1为左值,调用Person的拷贝构造函数
Person s2 = s1;
// move(s1) 为右值,调用Person移动构造函数(默认移动构造函数或自己写的移动构造函数)
Person s3 = std::move(s1);
Person s4;
// move(s2) 为右值,调用移动赋值重载(默认移动赋值重载函数或自己写的移动赋值重载函数)
s4 = std::move(s2);
return 0;
}
// 打印结果为:
// string(const string& s) --深拷贝
// string(const string& s) --移动拷贝
// string& operator=(string s) --移动赋值
强制生成默认函数的关键字default:
C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成默认的移动构造函数了,那么我们可以使用default关键字显示指定默认移动构造函数生成。
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
// 在实现拷贝构造函数、赋值重载函数、析构函数的同时
// 强制编译器生成默认的移动构造函数
Person(Person&& p) = default;
// 拷贝构造
Person(const Person& p)
:_name(p._name)
, _age(p._age)
{}
// 拷贝赋值重载
Person& operator=(const Person& p)
{
if(this != &p)
{
_name = p._name;
_age = p._age;
}
return *this;
}
// 析构函数
~Person()
{}
private:
qwy::string _name;
int _age;
};
int main()
{
Person s1;
// s1为左值,调用拷贝构造函数
Person s2 = s1;
// std::move(s1) 为右值,调用移动构造函数,其内部会调用String的移动构造函数
Person s3 = std::move(s1);
Person s4;
// 由于我们没有强制编译器生成移动赋值重载函数
// 因此虽然std::move(s2)为右值,还是调用的Person的赋值重载函数,其内部会调用String的赋值重载函数
// String的赋值重载函数会调用String的拷贝构造函数
s4 = std::move(s2);
return 0;
}
// 打印结果为:
//string(const string& s) --深拷贝
//string(const string& s) --移动拷贝
//string& operator=(string s) --深拷贝
//string(const string& s) --深拷贝
禁止生成默认函数的关键字delete:
- 如下场景:不想让A类对象被拷贝
class A
{
public:
void func()
{
// A tmp(*this);
}
// 构造函数
A()
{}
// 析构函数
~A()
{
delete[] p;
}
// C++11 的用法:使用关键字delete修饰函数,将函数标识为已删除函数
// 这样编译器就无法调用了
// 拷贝构造函数,被delete修饰,编译器无法调用
// A(const A& aa) = delete;
// private:
// C++98的用法:只声明不实现,声明为私有,
// 这样在main函数中,是无法调用类的私有成员函数的
// 在类的内部,虽然可以调用私有成员,但是C++98的用法只是声明了函数
// 并没有实现函数,因此调用这个函数时,并不能找到这个函数实现之后的地址
// 因为拷贝构造函数已经声明了,所以系统不会自动生成默认的拷贝构造函数
// A(const A& aa);
private:
int* p = new int[10];
};
int main()
{
A aa1;
aa1.func();
return 0;
}
6. lambda表达式
6.1 C++98中的一个例子
- 场景一:
#include<iostream>
#include <algorithm>
#include <functional>
using namespace std;
int main()
{
int array[] = { 4,1,8,5,3,7,0,9,2,6 };
// 默认按照小于比较,排出来结果是升序
std::sort(array, array + sizeof(array) / sizeof(array[0]));
for (auto e : array)
{
cout << e <<" ";
}
cout << endl;
// 如果需要降序,需要改变元素的比较规则,传入反函数greater<int>()
std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());
for (auto e : array)
{
cout << e << " ";
}
return 0;
}
- 场景二:
#include<iostream>
#include <algorithm>
#include <functional>
#include<vector>
using namespace std;
// 关于货物的结构
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
// ...
// 构造函数
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
// 升序要传递这个仿函数
struct ComparePriceLess
{
// 仿函数
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price; // 小于为真
}
};
// 降序要传递这个仿函数
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price; // 大于为真
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
//传统写法
//按照价格进行升序排列货物
sort(v.begin(), v.end(), ComparePriceLess());
for (auto e : v)
{
cout << e._price << " ";
}
cout << endl;
// 按照价格进行降序排列货物
sort(v.begin(), v.end(), ComparePriceGreater());
for (auto e : v)
{
cout << e._price << " ";
}
cout << endl;
return 0;
}
// 打印结果为:
// 1.5 2.1 2.2 3
// 3 2.2 2.1 1.5
随着C++语法的发展,人们开始觉得上面的写法太复杂了,每次为了实现一个algorithm(算法),都要重新去写一个类,如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,这些都给编程者带来了极大的不便。因此,在C++11语法中出现了Lambda表达式。
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
// 使用lamda表达式
// 按照价格进行升序排列货物
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._price < g2._price;});
for (auto e : v)
{
cout << e._price << " ";
}
cout << endl;
// 按照价格进行降序排列货物
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._price > g2._price; });
for (auto e : v)
{
cout << e._price << " ";
}
cout << endl;
return 0;
}
// 打印结果为:
// 1.5 2.1 2.2 3
// 3 2.2 2.1 1.5
6.2 lambda表达式语法
1.lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
[capture-list]: 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[ ]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同( )一起省略.mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。return-type:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。 注意:
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为空。因此C++11中最简单的
lambda函数为:[ ]{ };该lambda函数不能做任何事情。
演示1:
int main()
{
// 进行int对象比较的lambda表达式
// lambda-->lambda是一个可调用对象
// [](int x, int y)->bool{return x + y; };
// compare的类型,我们不知道,但是编译器是知道的,因此使用auto来自动推导
auto compare = [](int x, int y){return x > y; };
cout << compare(1, 2) << endl;
return 0;
}
// 打印结果为:0
2.捕获列表说明
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。
1.[var]:表示值传递方式捕捉变量var
2.[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
3.[&var]:表示引用传递捕捉变量var
4.[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
5.[this]:表示传值传递方式捕捉当前的this指针
注意:
a. 父作用域指包含lambda函数的语句块(这个语句块可以是while的语句块,也可以是if的语句块等等)
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,传值传递方式捕捉其他所有变量
[&,a, this]:传值传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
d. 在块作用域以外的lambda函数捕捉列表必须为空。
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
f.lambda表达式之间不能相互赋值,即使看起来类型相同
演示2:
int main()
{
int a = 0, b = 1;
auto add1 = [](int x, int y) {return x + y; };
cout << add1(a, b) << endl;
// 打印结果为1
auto add2 = [b](int x) {return x + b; };
cout << add2(a) << endl;
// 打印结果为1
// a和b都是传值传递的捕捉,因此,改变捕捉的a和b并不能改变a和b的原生变量
// 且我们可以理解为传值传递之后的变量a和b都是被const修饰的,因此a和b是不可以被修改的
// mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。
// 使用该修饰符mutable时,参数列表不可省略(即使参数为空)。
auto swap1 = [a, b]()mutable
{
int tmp = a;
a = b;
b = tmp;
};
swap1();
cout << a << ":" << b << endl;
// 打印结果为: 0:1
// 以引用的方式捕捉,也就是将a,b引用传参到捕捉列表
// 这样我们改变lamda中的a和b,就可以使a和b的原生变量发生改变
auto swap2 = [&a, &b]()
{
int tmp = a;
a = b;
b = tmp;
};
swap2();
cout << a << ":" << b << endl;
// 打印结果为: 1:0
// 混合捕捉
int x = 0, y = 1;
// 将x进行传值捕捉,将y进行传引用捕捉
auto func1 = [x,&y]()
{};
func1();
// 将y进行传引用捕捉,将其他变量进行传值传递捕捉
auto func2 = [=, &y]()
{
cout << x << endl;
// 打印结果为:0
};
func2();
return 0;
}
6.3函数对象与lambda表达式
// lambda的底层也就是一个仿函数
class Rate
{
public:
// 构造函数
Rate(double rate)
: _rate(rate)
{}
// ()重载函数,也就是仿函数
double operator()(double money, int year)
{
return money * _rate * year;
}
private:
double _rate;
};
int main()
{
// 函数对象
double rate = 0.49;
// 调用构造函数
Rate r1(rate);
// 重载operator()
r1(10000, 2);
// lambda
auto r2 = [=](double monty, int year)->double {return monty * rate * year; };
r2(10000, 2);
auto r3 = [=](double monty, int year)->double {return monty * rate * year; };
r3(10000, 2);
return 0;
}
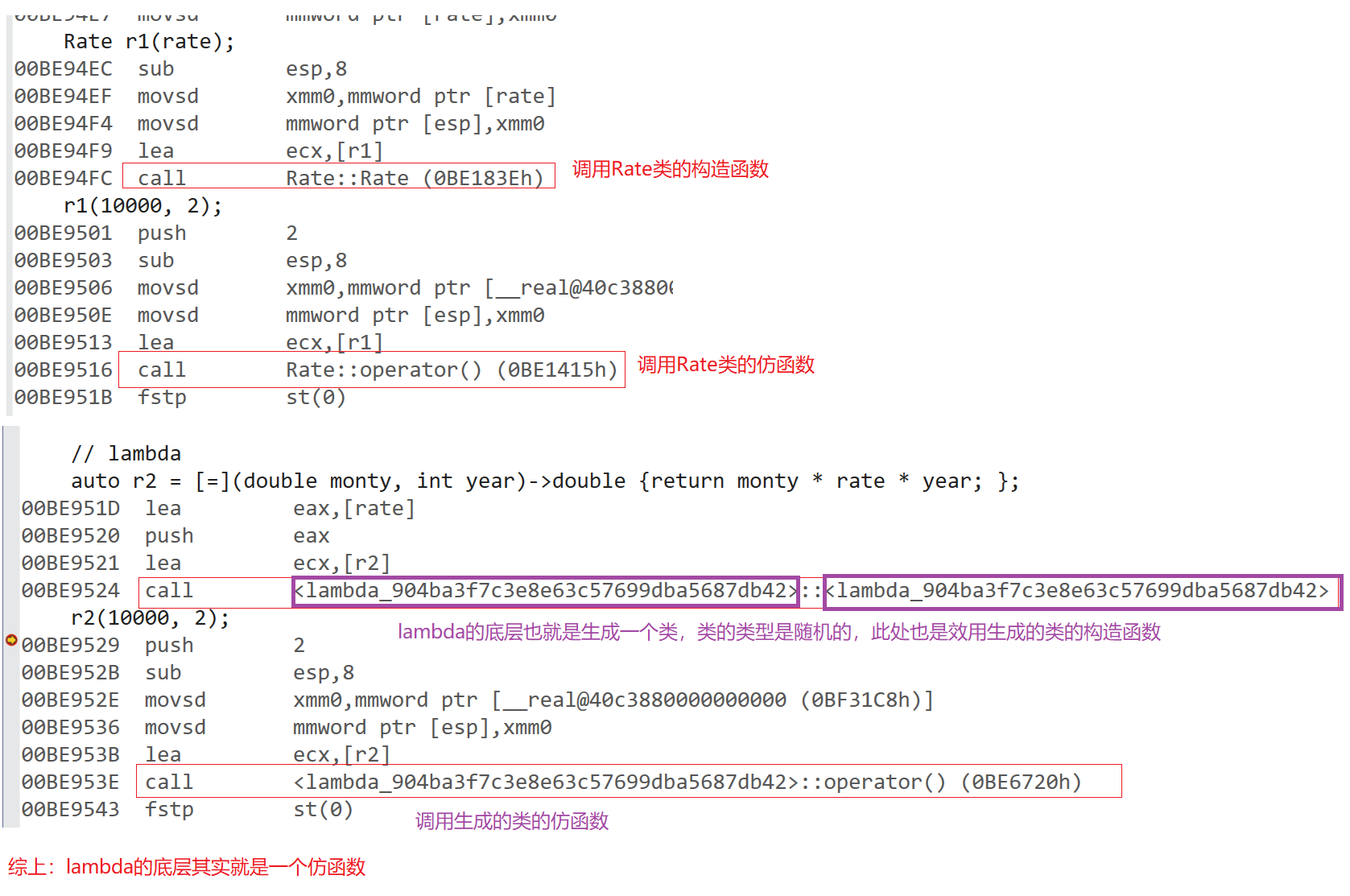
// 从使用方式上来看,函数对象与lambda表达式完全一样。
// 函数对象将rate作为其成员变量,在定义对象时给出初始值即可,
// lambda表达式通过捕获列表可以直接将该变量捕获到。
// 具体的底层调用如下图所示
7.可变参数模板
- 场景一:
// Args是一个模板参数包,args是一个函数形参参数包
// 声明一个参数包Args... args,这个参数包中可以包含0到任意个模板参数。
template <class ...Args>
void ShowList(Args... args)
{
// 用sizeof来判断参数包中有几个参数
// 需要注意sizeof的格式
cout << sizeof...(args) << endl;
}
int main()
{
// 函数形参 参数包,可以接收0~n个参数
ShowList(1);
ShowList(1, 1.1);
ShowList(1, 1.1, string("xxxxxx"));
ShowList();
return 0;
}
- 场景二:
上面的参数args前面有省略号,所以它就是一个可变模版参数,我们把带省略号的参数称为“参数包”,它里面包含了0到N(N>=0)个模版参数。我们无法直接获取参数包args中的每个参数的,只能通过展开参数包的方式来获取参数包中的每个参数,这是使用可变模版参数的一个主要特点,也是最大的难点,即如何展开可变模版参数。
// 打印函数形参参数包中的参数
void ShowList()
{
cout << endl;
}
// args参数包可以接收0-N个参数
template <class T, class ...Args>
void ShowList(T val, Args... args)
{
cout << val << " ";
ShowList(args...);
}
int main()
{
ShowList(1);
ShowList(1, 1.1);
ShowList(1, 1.1, string("xxxxxx"));
ShowList();
return 0;
}
// 具体如何调用,请看下图

逗号表达式展开参数包
- 场景一
注:在逗号表达式中,最后一个表达式的结果是整个逗号表达式的结果
逗号表达式会按顺序执行逗号前面的表达式
函数中的逗号表达式:(printarg(args), 0),也是按照这个执行顺序,
先执行printarg(args),再得到逗号表达式的结果0(第二个表达式的结果为0)。同时还用到了C++11的另外一个特性——>初始化列表,
通过初始化列表来初始化一个变长数组,
{ (printarg(args), 0)... }将会展开成
((printarg(arg1), 0),(printarg(arg2), 0), (printarg(arg3), 0), etc...),最终会创建一个元素值都为0的数组
int arr[sizeof...(Args)]。由于是逗号表达式,在创建数组的过程中会先执行逗号表达式前面的部分
printarg(args)打印出参数,也就是说在构造int数组的过程中就将参数包展开了,这个数组的目的纯粹是为了在数组构造的过程展开参数包
template <class T>
void PrintArg(T t)
{
cout << t << " ";
}
//展开函数
template <class ...Args>
void ShowList(Args... args)
{
int arr[] = { (PrintArg(args), 0)... };
cout << endl;
}
int main()
{
ShowList(1);
ShowList(1, 1.1);
ShowList(1, 1.1, string("xxxxxx"));
return 0;
}
- 场景二
// 不适用逗号表达式来展开
template <class T>
int PrintArg(T t)
{
cout << t << " ";
return 0;
}
//展开函数
template <class ...Args>
void ShowList(Args... args)
{
// 将PrintArg(args)...展开传递给函数PrintArg(T t)
// 并返回0
// 因为PrintArg(T t)函数的返回值为0,所以不需要用到逗号表达式
int arr[] = { PrintArg(args)... };
cout << endl;
}
int main()
{
ShowList(1);
ShowList(1, 1.1);
ShowList(1, 1.1, string("xxxxxx"));
return 0;
}
STL容器中的empalce相关接口函数:
template <class... Args>
void emplace_back(Args&&... args);
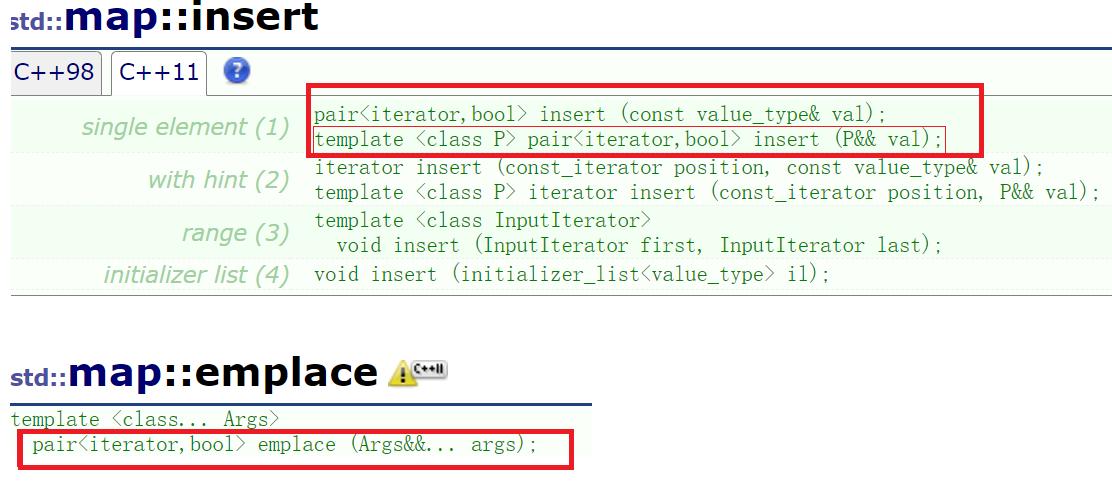
首先我们看到的emplace系列的接口,支持模板的可变参数,并且使用了万能引用。那么相对insert和emplace系列接口的优势到底在哪里呢?
list的实现,参考文章(右值引用)
int main()
{
// 创建一个list对象
// list节点存放了一个键对值,first的类型是int,second的类型是qwy::string
std::list< std::pair<int, qwy::string> > mylist;
// 会先调用string的构造函数,将"sort"构造为一个string对象
// 构造+深拷贝
pair<int, qwy::string> kv(20, "sort");
// kv是左值,插入时,需要创建一个新节点,new node("sort"构造的string对象),这个对象传参时就需要用拷贝函数
// 详情看list的具体实现
// void push_back (const value_type& val);
mylist.push_back(kv);
// 构造+移动拷贝
// make_pair(30, "sort") 是右值,会先调用构造来构造一个匿名对象
// list类的push_back 调用insert,insert调用节点的构造函数,节点的构造函数调用String类的移动构造函数
mylist.push_back(make_pair(30, "sort")); // 右值
// 构造+移动拷贝
// { 40, "sort" } 会先调用构造来构造一个匿名对象
// 再将这个匿名对象传递给移动构造
mylist.push_back({ 40, "sort" }); // 右值
// 构造+深拷贝
// 会先调用string的构造函数
// 再将kv传递给拷贝构造(进行深拷贝)
mylist.emplace_back(kv); // 左值;因为kv是左值,所以会调用string深拷贝
// 只调用构造
// 对于emplace_back()并不会先调用构造,
// 而是将参数 make_pair(20, "sort") 层层传递
// 直到传递到构造新的节点,用make_pair(20, "sort")直接构造新节点
mylist.emplace_back(make_pair(20, "sort")); // 右值
// 只调用构造
// 对于emplace_back()并不会先调用构造,
// 而是将参数 (10, "sort") 层层传递
// 直到传递到构造新的节点,用(10, "sort")直接构造新节点
mylist.emplace_back(10, "sort");
cout << endl;
return 0;
}
// 对string的调用具体如下图:
// 想要达到如下效果的打印,string的拷贝构造必须使用传统写法,
// 因为string的拷贝构造的现代写法会多调用一次构造函数,为了保证直观性,使用了传统写法

8. function包装器
- 首先,先来看一下如下的场景
// 通过下面的打印结果,我们可以发现,useF(F f, T x)被实例化了3份
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i)
{
return i / 2;
}
struct Functor
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{
// 函数名
cout << useF(f, 11.11) << endl;
// 函数对象
cout << useF(Functor(), 11.11) << endl;
// lamber表达式
cout << useF([](double d)->double{ return d / 4; }, 11.11) << endl;
return 0;
}
// 打印结果:
// count:1
// count:00B9F3D8
// 5.555
// count:1
// count:00B9F3DC
// 3.70333
// count:1
// count:00B9F3E0
// 2.7775
使用function进行包装
int f(int a, int b)
{
return a + b;
}
struct Functor
{
public:
int operator() (int a, int b)
{
return a + b;
}
};
class Plus
{
public:
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return a + b;
}
};
- 情况1
int main()
{
// 函数指针
// 使用function包装器来包装函数指针
// int f(int a, int b)
// <int(int, int)>中的第一个int是返回值,(int, int)是我们需要传递的参数
// 只要函数指针满足这个条件,我们就可以进行包装
function<int(int, int)> f1;
f1 = f;
// 直接使用函数指针f来构造包装器f2()
function<int(int, int)> f2(f);
// 包装之后,使用包装器来调用这个函数
cout << f1(1, 2) << endl;
cout << f2(1, 2) << endl;
return 0;
}
- 情况2
int main()
{
// 方法一
// 函数对象
// 使用function包装器来包装函数对象
f1 = Functor();
// 方法二:现将函数对象Functor显示定义出来
// 再用定义的函数对象ft来构造包装器f3
Functor ft;
function<int(int, int)> f3(ft);
// 方法三:使用Functor匿名函数对象Functor()来构造f4
// 这种方法编译器无法识别
// function<int(int, int)> f4(Functor());
// 方法四:使用赋值符号,用匿名对象Functor()来构造f5
function<int(int, int)> f5 = Functor();
cout << f1(1, 2) << endl;
cout << f3(1, 2) << endl;
// cout << f4(1, 2) << endl; // 编译器无法识别
cout << f5(1, 2) << endl;
// lambda对象
function<int(int, int)> f6 = [](const int a, const int b) {return a + b; };
cout << f6(1, 2) << endl;
return 0;
}
- 情况3
int main()
{
// 类静态成员函数指针
// function<int(int, int)> f7 = Plus::plusi;
// 上面这种写法也是正确的,但是为了与类成员函数使用的方法一致,我们通常会加上&
// 静态成员函数和对象没有关系,它是类的特性,不需要通过对象来调用,所以不需要传递this指针
function<int(int, int)> f7 = &Plus::plusi;
cout << f7(1, 2) << endl;
// 类成员函数指针
// 当我们调用类成员函数时,编译器都会隐式传参this指针给到成员函数
// 因此,在包装器中,我们也需要将类的对象,传递给包装器,
// 包装器就可以通过类的对象来调用类成员函数
function<int(Plus,int, int)> f8 = &Plus::plusd;
cout << f8(Plus(),2, 2) << endl; // Plus() 是Plus类的一个匿名对象
// 对类成员函数指针进行进一步的包装
// 创建一个类的对象
Plus ps;
function<int(Plus, int, int)> f9 = &Plus::plusd;
// ps是已经创建的Plus类类型的具体对象
cout << f9(ps, 2, 2) << endl;
// 使用lambda表达式,使封装统一规范
// 我们通过lambda的捕捉列表捕捉了类成员对象的地址(&ps),此处是引用捕捉,也就是捕捉了对应的this指针
// 因此,不在需要我们传递类对象ps了,统一了使用的规范
function<int(int, int)> f10 = [&ps](int x, int y)->int {return ps.plusd(x,y); };
cout << f10(2, 3) << endl;
return 0;
}
静态成员函数和普通成员函数
下面的内容是其他博客对静态成员函数和普通成员函数的解释
在C++的类中,static 除了可以声明静态成员变量,还可以声明静态成员函数。普通成员函数可以访问所有成员(包括成员变量和成员函数),静态成员函数只能访问静态成员。
1、静态成员函数可以通过类直接调用,而不一定必须通过实例化对象来调用。
- 编译器在编译一个普通成员函数时,会隐式地增加一个形参 this指针,并把当前对象的地址赋值给 this指针,所以普通成员函数只能在创建对象后通过对象来调用,因为它需要当前对象的地址,也就是this指针。
- 而静态成员函数可以通过类来直接调用,编译器不会为它增加形参 this指针,它不需要当前对象的地址,所以不管有没有创建对象,都可以调用静态成员函数。
2、普通成员变量占用对象的内存。
- 静态成员函数没有 this 指针,不知道指向哪个对象,无法访问对象的成员变量,也就是说静态成员函数不能访问普通成员变量,只能访问静态成员变量。
3、普通成员函数必须通过对象才能调用。
- 而静态成员函数没有 this 指针,无法在函数体内部访问某个对象,所以不能调用普通成员函数,只能调用静态成员函数。
4、静态成员函数与普通成员函数的根本区别在于:普通成员函数有 this 指针,可以访问类中的任意成员;
- 而静态成员函数没有 this 指针,只能访问静态成员(包括静态成员变量和静态成员函数)。
使用包装器解决模板效率低下,实例化多份的问题
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i)
{
return i / 2;
}
struct Functor
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{
// 函数名
// function<int(double)>(f) 是一个包装器的匿名对象
cout << useF(function<int(double)>(f), 11.11) << endl;
// 函数对象
Functor ft;
cout << useF(function<int(double)>(ft), 11.11) << endl;
// 用lamber表达式去构造包装器
cout << useF(function<int(double)>([](double d)->double { return d / 4; }), 11.11) << endl;
return 0;
}
// 通过打印结果我们可以得知,通过包装器只是实例化了一个函数
// 打印结果:
//count:1
//count : 00B156D4
//5
//count : 2
//count : 00B156D4
//3
//count : 3
//count : 00B156D4
//2
逆波兰表达式求值

// 由题目要求这个函数就是将后缀表达式,改为我们常用的中缀表达式
class Solution {
public:
int evalRPN(vector<string>& tokens) {
// 创建一个栈对象st
stack<int> st;
for(auto str : tokens)
{
// 比较两个字符串的大小,其实比较的是ASCLL值
// c++ 重载了 <, >, !=, == 等等
if(str == "+" || str == "-" || str == "*" || str == "/")
{
// 因为操作数入栈时,是左操作数先入栈,右操作数后入栈
// 因此,出栈时,是右操作数先出栈,左操作数后出栈
// 并且,操作符是紧跟在两个操作数之后的
int right = st.top();
st.pop();
int left = st.top();
st.pop();
// swicth传参,必须传一个整型(语法规定)
// str[0]的类型是char,char也是整型家族的一员
switch(str[0])
{
// 用单引号引出的一个字符本质上代表的就是一个整数,整数的数值由编译器的字符集来表示。比如ASCLL字符集的编译器下 ,字符 'A' 的含义就是 十进制的 65。
case '+':
// 计算后入栈
st.push(left+right);
break;
case '-':
st.push(left-right);
break;
case '*':
st.push(left*right);
break;
case '/':
st.push(left/right);
break;
}
}
else
{
// 如果str不是操作符,那么用stoi()将str这个字符串转化为整型,并将其入栈到st中
st.push(stoi(str));
}
}
return st.top();
}
};
- 方法二:使用包装器和
lambda表达式
class Solution {
public:
int evalRPN(vector<string>& tokens) {
// 创建一个栈对象st
stack<int> st;
// 创建一个map用来存储操作符和其对应的运算函数
// 运算函数,我们使用lambda来封装
// 再使用function包装器,将所有的lambda的使用方式规范统一
// 且解决了模板效率低下,实例化多份的问题
// 使用{}也来初始化
// first是string对象,second是包装器对象function<int(int,int)>
map<string,function<int(int,int)>> opFuncMap =
{
{"+",[](int x, int y)->int{return x+y;}},
{"-",[](int x, int y)->int{return x-y;}},
{"*",[](int x, int y)->int{return x*y;}},
{"/",[](int x, int y)->int{return x/y;}},
};
for(auto& str : tokens)
{
// map中的key为操作符 + - * /
// 如果没有查找到,那么说明str为操作数
if(opFuncMap.count(str) == 0)
{
// 代码运行到这里,说明str为操作数,因此直接入栈
st.push(stoi(str));
}
else
{
//代码运行到这里,说明str为操作符,那么我们就需要进行相应的运算
// 首先,从栈里面将操作数拿出
int right = st.top();
st.pop();
int left = st.top();
st.pop();
// opFuncMap[str]的返回值就是second的引用,也就是包装器的传引用返回
// 我们再通过包装器调用对应的lambda表达式opFuncMap[str](left,right),并进行传参
// 这样就计算出了左右操作数对应运算后的结果了
// 最后再将结果入栈就可以了
st.push(opFuncMap[str](left,right));
}
}
// 运行到这里,栈里面只剩下一个数,也就是最终的计算结果
return st.top();
}
};
9. bind(绑定)
std::bind 是 C++11 中引入的函数模板,位于 <functional> 头文件中,用于创建一个可调用对象(函数对象)并将其与参数绑定。这样可以延迟调用函数、改变函数的参数顺序或固定一部分参数。
std::bind 的语法如下:
std::bind(Function, Args...);
其中:
Function是一个可调用对象,可以是函数指针、函数对象、成员函数指针或者 Lambda 表达式。Args...是一系列参数,用于绑定到Function中的参数。
std::bind 返回一个可调用对象,可以直接调用或者传递给其他函数。
std::bind 的具体用法有很多,以下是几个示例:
示例 1:绑定普通函数
#include <functional>
#include <iostream>
// 普通函数
int add(int a, int b) {
return a + b;
}
int main() {
// 绑定 add 函数,并将第一个参数固定为 10
auto bound_add = std::bind(add, 10, std::placeholders::_1);
// 调用 bound_add,并传入第二个参数
std::cout << bound_add(5) << std::endl; // 输出 15
return 0;
}
在这个示例中,std::bind 绑定了 add 函数,并将第一个参数固定为 10。然后,调用 bound_add 时只需要传入第二个参数,它会自动将第一个参数作为 10 传递给 add 函数,从而实现了对 add 函数的柯里化。
示例 2:绑定成员函数
#include <functional>
#include <iostream>
class A {
public:
void print(int x) {
std::cout << "Value: " << x << std::endl;
}
};
int main() {
A obj;
// 绑定成员函数 print,并将 obj 指针传入
auto bound_print = std::bind(&A::print, &obj, std::placeholders::_1);
// 调用 bound_print
bound_print(42); // 输出 Value: 42
return 0;
}
在这个示例中,std::bind 绑定了 A 类的成员函数 print,并将 obj 指针作为成员函数的隐式参数传入。
示例 3:使用占位符
#include <functional>
#include <iostream>
// 普通函数
int add(int a, int b, int c) {
return a + b * c;
}
int main() {
// 绑定 add 函数,并使用占位符指定参数顺序
auto bound_add = std::bind(add, std::placeholders::_2, std::placeholders::_1, 5);
// 调用 bound_add
std::cout << bound_add(3, 2) << std::endl; // 输出 17
return 0;
}
在这个示例中,std::bind 绑定了 add 函数,并使用占位符指定了参数的顺序。std::placeholders::_1 表示第一个参数,std::placeholders::_2 表示第二个参数,以此类推。
综合
int Plus(int a, int b)
{
return a + b;
}
int SubFunc(int a, int b)
{
return a - b;
}
class Sub
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
function<int(int, int)> func1 = bind(Plus, placeholders::_1,placeholders::_2);
cout << func1(1, 2) << endl;
function<int(int, int)> func2 = bind(SubFunc, placeholders::_1, placeholders::_2);
// 调换参数顺序
// placeholders::_1 占位符处的参数与SubFunc函数的第二个参数绑定
// placeholders::_2 占位符处的参数与SubFunc函数的第一个参数绑定
function<int(int, int)> func3 = std::bind(SubFunc, placeholders::_2, placeholders::_1);
cout << func2(1, 2) << endl;
cout << func3(1, 2) << endl;
// 绑定固定参数,注:sub是一个成员函数,因此要传递成员对象
// 未绑定时
function<int(Sub, int, int)> func4 = &Sub::sub;
cout << func4(Sub(), 10, 20) << endl;
cout << func4(Sub(), 100, 200) << endl;
// 本来我们调用,需要传递3个参数,第一个参数为类对象,也就是Sub()这个匿名对象
// 将第一个参数Sub()绑定后,我们只需要传后面两个参数就可以了
// 绑定后,只需要传后两个参数
function<int(int, int)> func5 = bind(&Sub::sub, Sub(),placeholders::_1, placeholders::_2);
cout << func5( 10, 20) << endl;
cout << func5( 100, 200) << endl;
// 也可以调换参数的顺序
function<int(int, int)> func6 = bind(&Sub::sub, Sub(), placeholders::_2,placeholders::_1);
cout << func6(10, 20) << endl;
cout << func6(100, 200) << endl;
return 0;
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









