






前言:学了半天终于领悟,浅浅记录一下
题目:
给定一个字符串 S,以及一个模式串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模式串 P在字符串 S 中多次作为子串出现。
求出模式串 P 在字符串 S 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N,表示字符串 P 的长度。
第二行输入字符串 P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 00 开始计数),整数之间用空格隔开。
数据范围
1≤N≤1e5
1≤M≤1e6输入样例:
3 aba 5 ababa输出样例:
0 2朴素算法:
例如:长的字符串 S = “ababababfab” ,短的字符串 P = “ababf”,可以看出 P 在 S 中第一次出现位置是在S[4] 到S[8],所以输出4。
例如:长的字符串 S = “abababfab” ,短的字符串 P = “ababg”,可以看出 P 在 S 中没有出现过,输出 -1。
最容易想到的做法是:暴力求解。
依次比较以长字符串各个字母为开头的子串是否与短字符串匹配。
如果有匹配的输出起始位置,如果没有,输出 -1。
例如:以长的字符串 S = “ababababfab” ,短的字符串 P = “ababf” 为例,过程如下:
首先用S[0]开头的子串:ababa 与 P比较,不匹配。
接着用S[1]开头的子串:babab 与 P比较,不匹配。
接着用S[2]开头的子串:ababa 与 P比较,不匹配。
接着用S[3]开头的子串:babab 与 P比较,不匹配。
接着用S[4]开头的子串:ababf 与 P比较,匹配。输出4。
S[M],P[N];
for(int i=1;i<=m;i++)
{
bool flag = true;
for(int j=1;j<=n;j++)
{
if(p[j]!=s[i+j-1]){
flag=false;
break;
}
}
if(flag==true)
printf("%d ",i-j);
}朴素算法的时间复杂度为O(m*n);
但也由此看出,会执行许多没用的步骤
接下来是优化:
KMP:
KMP主要分两步:求next数组、匹配字符串。
核心思想:在每次失配时,不是把p串往后移一位,而是把p串往后移动至下一次可以和前面部分匹配的位置,这样就可以跳过大多数的失配步骤。而每次p串移动的步数就是通过查找next[ ]数组确定的。
next[j]含义是:P[j] 前面的字符串的最长公共前后缀长度,换句话说next[j] 就是所求最长相等前后缀中前缀的最后一位的下标。
1.匹配字符串
s串 和 p串都是从1开始的。i 从1开始,j 从0开始,每次s[ i ] 和p[ j + 1 ]比较
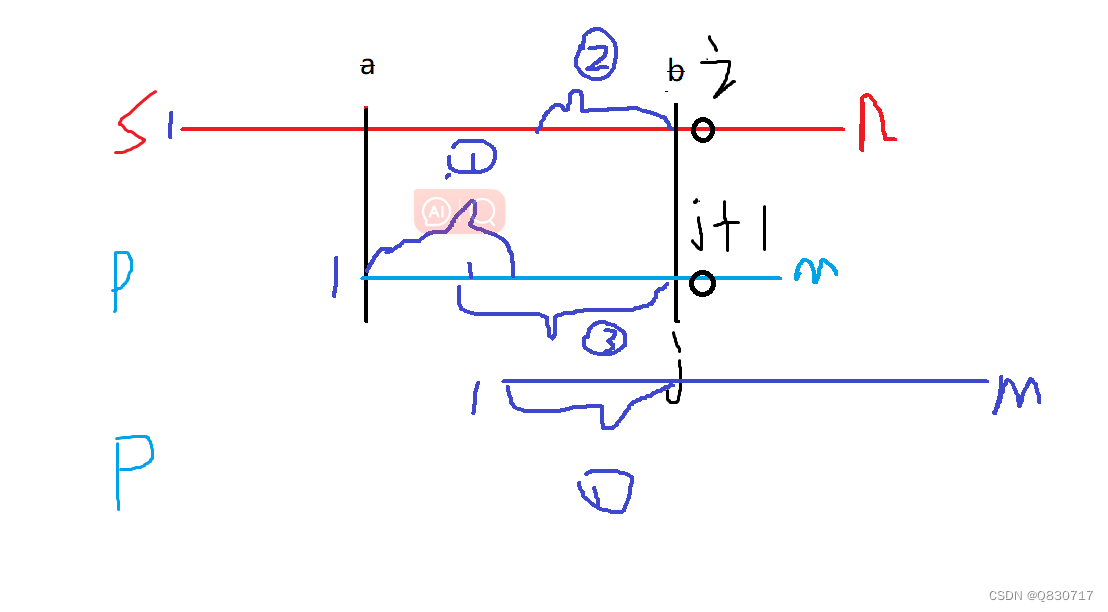
其中1串为[ 1, next[ j ] ],3串为[ j - next[ j ] + 1 , j ]。由匹配可知 1串等于3串,3串等于2串。所以直接移动p串使1到3的位置即可。这个操作可由j = next[ j ]直接完成。 如此往复下去,当 j == m时匹配成功。
s[ a , b ] = p[ 1, j ] && s[ i ] != p[ j + 1 ] 此时要移动p串(不是移动1格,而是直接移动到下次能匹配的位置)
for(int i = 1, j = 0; i <= n; i++)
{
while(j && s[i] != p[j+1]) j = ne[j];
//如果s[i] != p[j+1]匹配失败,且j还能往后退,除非到了第一个字符,继续移动j的位置缩小
//用while是由于移动后可能仍然失配,所以要继续移动直到匹配或j移到了开头if(s[i] == p[j+1]) j++;
//当前元素匹配,j移向p串下一位,包括了开头字符
if(j == m)
{
//匹配成功,进行相关操作
j = next[j]; //继续匹配下一个子串
}
}
其中1串为[ 1, next[ j ] ],3串为[ j - next[ j ] + 1 , j ]。由匹配可知 1串等于3串,3串等于2串。所以直接移动p串使1到3的位置即可。这个操作可由j = next[ j ]直接完成。 如此往复下去,当 j == m时匹配成功。
2.求next数组
next数组的求法是通过模板串自己与自己进行匹配操作得出来的(代码和匹配操作几乎一样)。
for(int i = 2, j = 0; i <= m; i++)
{
while(j && p[i] != p[j+1]) j = next[j];if(p[i] == p[j+1]) j++;
next[i] = j;
}
代码和匹配操作的代码几乎一样,关键在于每次移动 i 前,将 i 前面已经匹配的长度记录到next数组中。
AC代码
#include<iostream>
using namespace std;
const int N=1e5+10,M=1e6+10;
char p[N],s[M];
int ne[N];//存放以j结尾的前缀的最后一位
int main(){
int n,m;
cin>>n>>p+1>>m>>s+1;//从一开始
//计算ne
for(int i=2,j=0;i<=n;i++){//1的前缀为0,所以从2开始,j是从j+1开始判断,所以j=0,i与j永远错开一位
while(j!=0&&p[j+1]!=p[i])j=ne[j];//如果p[j+1]!=p[i]并且j还能退的话,j就一直退
//直到j退到1的位置,或者p[j+1]==p[i];即匹配上了
if(p[j+1]==p[i])j++;//再次判断能不能匹配的上,不管是1的位置还是p[j+1]和p[i]匹配上了
//都要进行判断
ne[i]=j;//记录ne[i];
}
for(int i=1,j=0;i<=m;i++){//i和j错开一位
while(j!=0&&p[j+1]!=s[i])j=ne[j];//同上面
if(p[j+1]==s[i])j++;
if(j==n){
printf("%d ",i-j);
j=ne[j];//继续从前缀的最后一位开始匹配,效率更高,与暴力算法不同之处
}
}
return 0;
}
我们看到 for 循环中每一个 i 都有一个 while 循环,这样 j 回退的次数可能不可预计,为什么 KMP 的时间复杂度为 O(n+m)?
首先,在 kmp 整个 for 循环中 i 是不断加 1 的,所以在整个过程中 i 的变化次数是 O(m)
级别,接下来考虑 j 的变化,我们注意到 j 只会在一行中增加,并且每次只加 1,这样在整个过程中 j 最多增加 m 次;而其它情况 j 都是不断减小的,由于 j 最小不会小于 -1,因此在整个过程中,j 最多只能减少 m 次。也就是说 while 循环对整个过程来说最多只会执行 m 次,因此 j 在整个过程中变化次数是 O(m)级别的。由于 i 和 j 在整个过程中的变化次数都是 O(m),因此 for 循环部分的整体复杂度就是 O(m)。考虑到计算 next 数组需要 O(n) 的时间复杂度(分析方法与上同),因此 kmp 算法总共需要 O(n+m) 的时间复杂度。
//单纯的记录一下














 7790
7790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









