






安装Kibana
1 什么是Kibana
Kibana是ES提供的一个基于Node.js的管理控制台, 可以很容易实现高级的数据分析和可视化,以图标的形式展现出来。
kibana可以用来编辑请求语句的,方便学习操作es的语法。有时在进行编写程序,
写到查询语句时,往往我会使用kibana进行书写,然后再粘贴到程序中。(不容易出错)
2 下载
ElasticSearch官网:https://www.elastic.co/cn/
3 安装
在window中安装Kibana很方便,解压即安装
4 修改配置
修改config/kibana.yml配置:
server.port: 5601
server.host: "0.0.0.0" #允许来自远程用户的连接
elasticsearch.url: http://192.168.204.132:9200 #Elasticsearch实例的URL
5 启动
./bin/kibana
6 测试
浏览器访问:http://127.0.0.1:5601
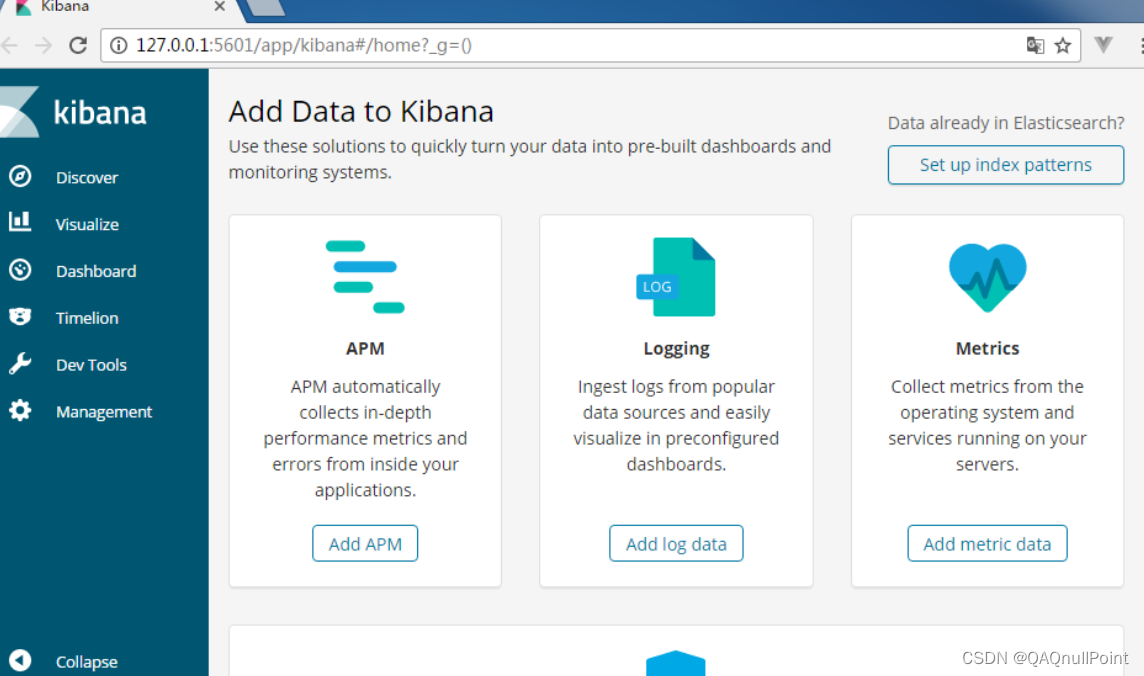
安装head
1 什么是head
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,
比如创建映射、创建索引等。从ES6.0开始,head插件支持使得node.js运行。
2 安装
- 下载
下载地址:https://github.com/mobz/elasticsearch-head - 运行(cmd窗口中解压目录下使用命令)
npm run start
3 测试
浏览器访问:http://127.0.0.1:9100/

安装IK分词器
使用IK分词器可以实现对中文分词的效果。
1 下载IK分词器:(Github地址:https://github.com/medcl/elasticsearch-analysis-ik)
- 下载zip:
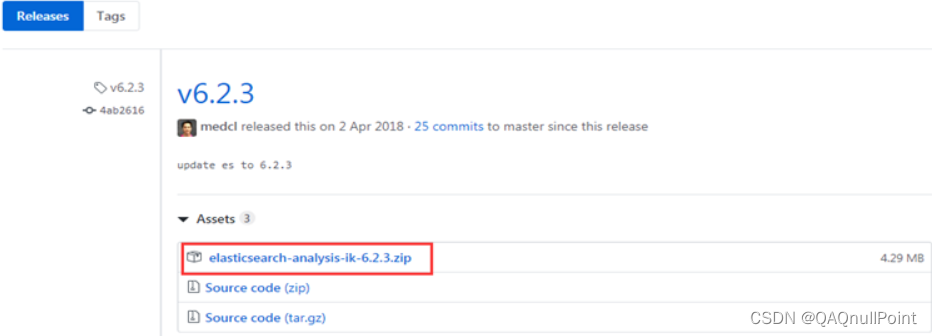
- 解压,并将解压的文件拷贝到ES安装目录的plugins下的ik(重命名)目录下,重启es

- 测试分词效果:
POST /_analyze
{
“text”:“中华人民共和国人民大会堂”,
“analyzer”:“ik_smart”
}
2 两种分词模式
ik分词器有两种分词模式:ik_max_word和ik_smart模式。
- ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为
“中华人民共和国、中华人民、中华、华人、人民大会堂、人民、共和国、大会堂、大会、会堂等词语。
- ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
3 自定义词库
如果要让分词器支持一些专有词语,可以自定义词库。
iK分词器自带的main.dic的文件为扩展词典,stopword.dic为停用词典。

也可以上边的目录中新建一个my.dic文件(注意文件格式为utf-8(不要选择utf-8 BOM))
可以在其中自定义词汇:
比如定义:
配置文件中 配置my.dic,
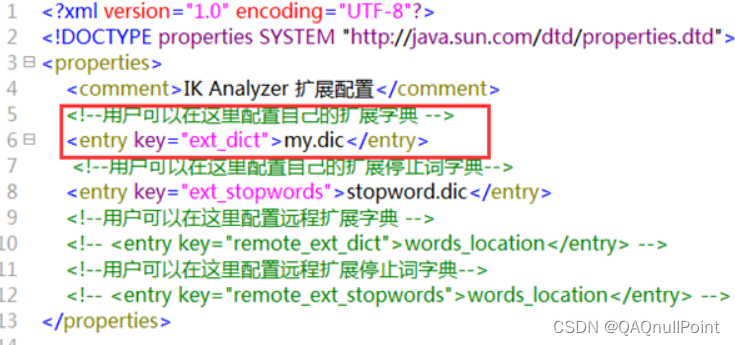
然后去 Kibana 测试你自定义的词语就可以了。















 3190
3190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









