







前端代码实现原理 - 界面渲染
前面提到前端 HTML+CSS 可以看成一种描述界面的低代码 DSL,因此前端界面实现低代码会比较容易,只需要对 HTML+CSS 进行更进一步封装,这里以我们的开源项目 amis 为例进行介绍。
amis 核心原理是将 JSON 转成自研的 React 组件库,然后使用 React 进行渲染。
比如下面这段 JSON:
{
“type”: “page”,
“title”: “页面标题”,
“subTitle”: “副标题”,
“body”: {
“type”: “form”,
“title”: “用户登录”,
“body”: [
{
“type”: “input-text”,
“name”: “username”,
“label”: “用户名”
}
]
}
}
可以理解 amis 原理就是转成了下面这样的 React 组件树,最终由各个 React 组件库渲染 HTML:
虽然也有低代码平台直接使用 HTML+CSS 来实现更灵活的界面控制,但这样做会导致用起来复杂度高,因为通常需要多层嵌套 HTML 才能实现一个组件,使用者还必须熟悉 HTML 及 CSS,上手门槛过高,因此大部分低代码平台都是类似 amis 那样使用 JSON 进行简化。
这里有个小问题,为什么大家几乎全都使用 JSON?我觉得有两方面原因:
-
低代码平台编辑器几乎都是基于 Web 实现,JavaScript 可以方便操作 JSON。
-
JSON 可以支持双向编辑,它的读取和写入是一一对应的。
第二点怎么理解?可以对比一下 YAML,它有引用功能,导致了不好实现双向编辑,比如下面 YAML 示例:
paths:
root_path: &root
val: /path/to/root/
patha: &a
root_path: *root
转成了对应的 JSON 数据后,就变成了
{
“paths”: {
“root_path”: {
“val”: “/path/to/root/”
},
“patha”: {
“root_path”: {
“val”: “/path/to/root/”
}
}
}
}
可以看到之前的引用关系没了,而是复制出了一部分,如果直接基于这个数据进行可视化编辑,编辑器在修改的时候就只会改一处,也没法再还原成之前的 YAML 了,要想实现 YAML 可视化编辑就不能先转成 JSON,而是要对 YAML 解析后的树形结构进行操作,前端界面实现成本很高,因此目前还没见过 YAML 的可视化编辑器。
但 JSON 的优点就是它的缺点,因为它的用途是数据交换而不是人工编写,导致基于 JSON 构建 DSL 不方便编辑,会有以下 3 个问题:
-
不支持注释
-
不支持多行字符串
-
语法过于严格,比如不支持单引号,不能在最后多写一个逗号
其中我们对这个注释问题进行了特殊支持,开发了带注释的 JSON 解析,存储的时候将注释内嵌到一个特殊的字段中,在代码显示的时候将它提取出来变成注释。
另外许多低代码平台会将这个 JSON 配置隐藏,只提供界面编辑,但在 amis 可视化编辑器里提供了直接修改 JSON 的功能,因为对于熟悉的开发者,直接编写 JSON 要比在属性面板里找半天效率高,还可以直接将 amis 文档中的示例粘贴进来快速创建。

amis 开始编辑器里 JSON 编辑模式
前面提到声明式容易向下兼容,amis 自己就是最好的例子,在 amis 诞生的 2015 年前端框架和现在有大量区别:
-
Vue 还是 1,现在已经到 3 了,不向下兼容。
-
Angular 还是 1,现在已经 13 了,不向下兼容。
-
React 虽然整体用法没变,但有大量细节不向下兼容,加上 hooks 推出后,许多第三方库改成了 hooks 版本,导致旧的类组件形式没法直接使用。
而 amis 早期的界面配置现在还能继续使用,不受框架升级影响。
交互逻辑的实现
前面说到前端界面低代码是比较容易,但交互及逻辑处理却很难低代码话,目前常见有三种方案:
-
使用图形化编程
-
固化交互行为
-
使用 JavaScript
先说第一种图形化编程,这是非常自然的想法,既然低代码的关键是可视化,那直接使用图形化的方式编程不就行了?
但我们发现这么做局限性很大,本质的原因是「代码无法可视化」,这点在 35 年前没有银弹的论文里就提到了。
为什么代码无法可视化?首先想一想,可视化的前提条件是什么?
答案是需要具备空间形体特征,可视化只能用来展现二维及三维的物体,因为一维没什么意义,四维及以上大部人无法理解,所以如果一个事物没有形体特征,它就没法被可视化。
举个例子,下面是一段 amis中 代码,作用是遍历 JSON 并调用外部函数进行处理:
function JSONTraverse(json, mapper) {
Object.keys(json).forEach(key => {
const value = json[key];
if (isPlainObject(value) || Array.isArray(value)) {
JSONTraverse(value, mapper);
} else {
mapper(value, key, json);
}
});
}
虽然只有 10 行代码,却包含了循环、调用函数、类型检测、分支判断、或操作符、递归调用、参数是函数这些抽象概念,这些概念在现实中都找不到形体的,你可以尝试一下用图形来表示这段代码,然后给周围人看看,我相信任何图形化的尝试都会比原本这段代码更难懂,因为你需要先通过不同图形来区分上面的各种概念,其他人得先熟悉这些图形符号才能看懂,理解成本反而更高了。
代码的这些抽象思维**「难以像积木一样进行拼接」**,积木拼接这种方式只适合用来实现简单的逻辑,比如 scratch。
Scratch
而前面图形化是低代码唯一不可少的功能,这就使得低代码不适合做复杂的抽象逻辑处理,这是图形化缺陷决定的,因此在复杂逻辑处理方面低代码永远无法彻底取代专业代码开发。
但如果是面向特定领域,低代码平台可以先将这个领域难以图形化的算法预置好,让使用者只需做简单的处理,比如在 Blender 中将 PBR 算法封装了,使用的时候只需要调整参数就行
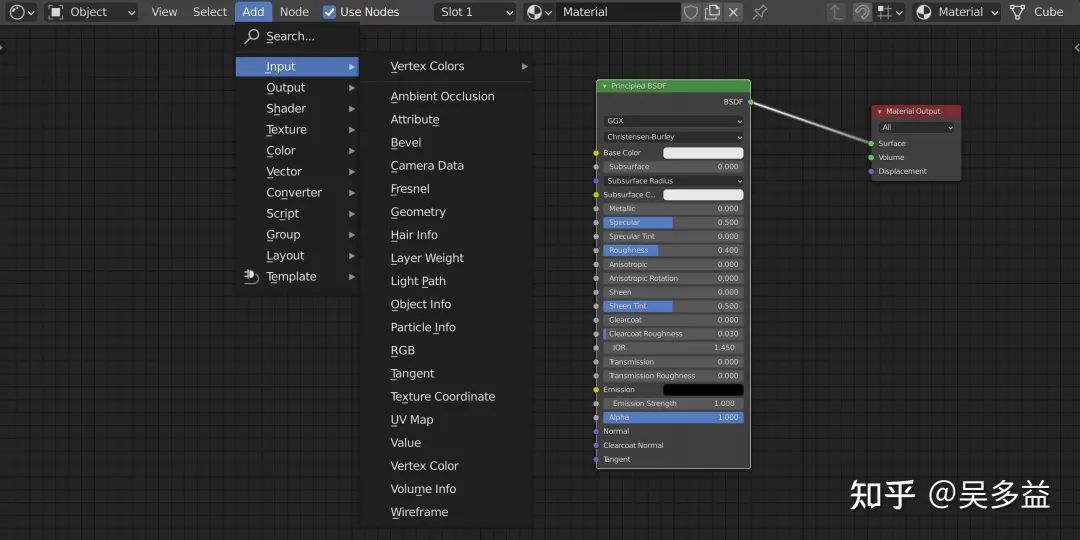
Blender 中的材质节点编辑
如果真要用节点实现这个算法会非常复杂,大概长这样
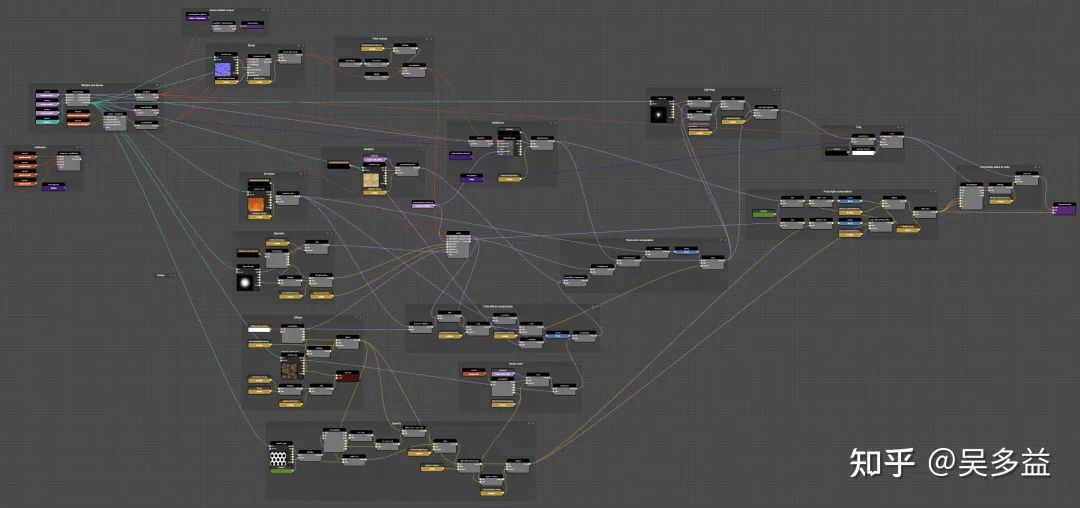
在复杂逻辑下,图形中的连线反而变成了视觉干扰,比如下面的例子
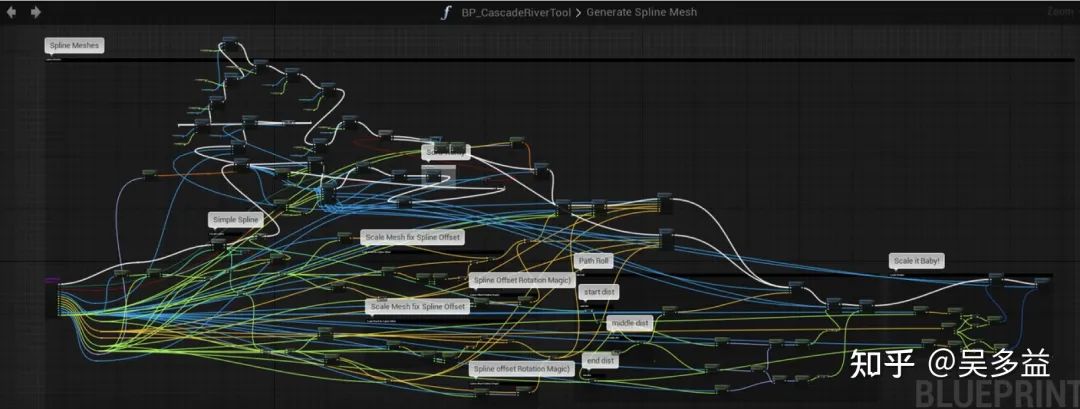
来自 UE4 Blueprints From Hell 里的一张图
想象一下假设客户做出了上面这个图的复杂逻辑,然后找你排查问题,而客户的程序是部署在内网的,没法导出,只能通过微信拍屏幕给你看。。。
因此我认为图形化不适合用来实现业务逻辑,只适合用来做更高层次流程控制,比如审批流,审批流是现实真实存在的,没有复杂的抽象逻辑,因此适合图形化。

在爱速搭中,我们除了实现流程功能,还实现了树形结构的 api 编排功能,它本质上是模仿代码结构,将会在后面进行介绍。
说完了图形化编程,接下来谈第二种方案:固化交互行为,这是不少低代码平台的做法,我们还是以 amis 为例进行介绍。
amis 将常用的交互行为固化并做成了配置,比如弹框是下面的配置:
{
“label”: “弹框”,
“type”: “button”,
“actionType”: “dialog”,
“dialog”: {
“title”: “弹框”,
“body”: “这是个简单的弹框。”
}
}
除了弹框之外还有发起请求、打开链接、刷新其它组件等,使用固化交互行为有下面两个优点:
-
可以可视化编辑
-
整合度高,比如弹框里可以继续使用 amis 配置,通过嵌套实现复杂的交互逻辑
但这个方案最大的缺点是灵活性受限,只能使用 amis 内置的行为。
要实现更灵活的控制,还是得支持第三个方案:JavaScript,目前有的低代码平台只在界面编辑提供可视化编辑,一旦涉及到交互就得写 JavaScript,这和 30 年前的 C++ Builder 本质上是一样的:
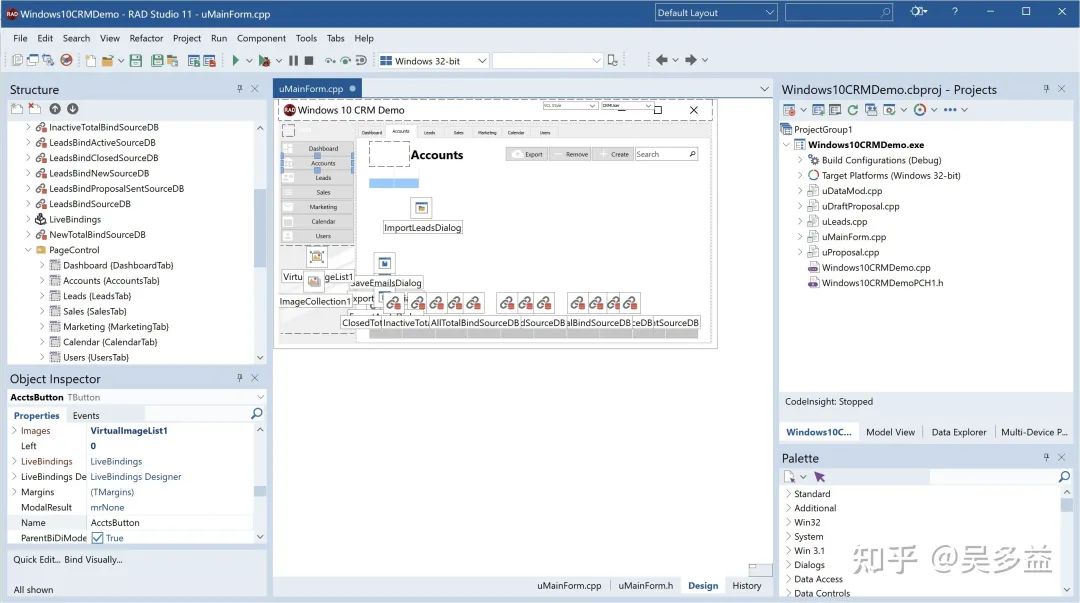
RDA Studio 11 的界面编辑
但第三个方案的最大缺点就是无法可视化编辑,因此不算是低代码。
后端低代码的方案
前端讨论完了,接下来是后端部分,后端低代码需要解决以下三个问题:
-
如何实现自定义数据存储?
-
如何实现业务逻辑?
-
如何实现流程流转?
如何自定义数据存储?
低代码平台需要支持用户存储自定义数据,因为每个应用所需的字段是不一样的。
自定义数据存储是后端低代码最重要的功能,使用什么方案将直接影响这个产品的适用范围,目前我们已知有 5 种方案,每种都有自己的优缺点。
存储的实现方案 1:直接使用关系型数据库
这个方案的原理是将数据模型的可视化操作转成数据库 DDL,比如添加了一个字段,系统会自动生成表结构变更语句:
ALTER TABLE ‘blog’ ADD ‘title’ varchar(255) NULL;
这个方案的优点是:
-
所有方案里唯一支持直连外部数据库,可以对接已有系统。
-
性能高和灵活性强,因为可以使用高级 SQL。
-
开发人员容易理解,因为和专业开发是一样的。
但它的缺点是:
-
需要账号有创建用户及 DDL权限,如果有安全漏洞会造成严重后果,有些公司内部线上帐号没有这个权限,导致无法实现自动化变更。
-
DDL 有很多问题无解,比如在有数据的情况下,就不能再添加一个没有默认值的非 NULL 字段。
-
DDL 执行时会影响线上性能,比如 MySQL 5.6 之前的版本在一个大数据量的表中添加索引字段会锁整个表的写入(但也有数据库不受影响,比如 TiDB、OceanBase 支持在线表结构变更,不会阻塞读写)。
-
部分数据库不支持 DDL 事务,比如 MySQL 8 之前的版本,导致一旦在执行过程中出错将无法恢复。
-
实现成本较高,需要实现「动态实体」功能,如果要支持不同数据库还得支持各种方言。
尽管这个方案有很多缺点,但它的优点也很突出,因此爱速搭里实现了这个方案,因为我们觉得能连已有数据库是非常重要的,其它方案都只适合用来做新项目,这个方案使得可以逐步将已有项目低代码化,不需要做数据迁移。
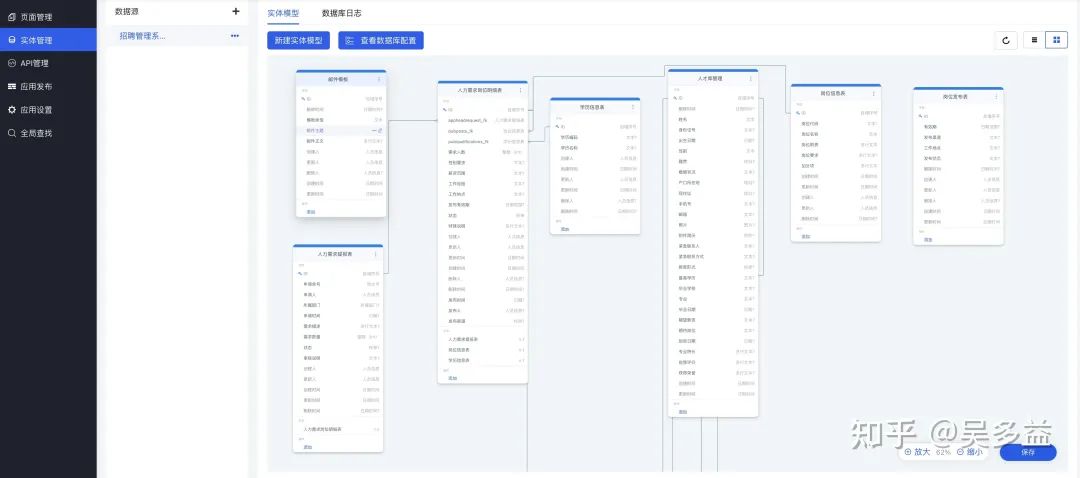
爱速搭里的数据库模型
实现这个方案的关键是「动态实体」,在专业开发中实体(Entity)定义都是静态的,以 Java 为例,它从 2006 年开始就有专门的 JPA 规范,但这个规范是定义基于 Java 代码注解,使得需要经过编译才能使用,毕竟它的定位是面向专业开发,只有写在代码里才能支持代码提示,提升开发体验,而低代码平台中需要将这个实体定义抽象成配置,在运行时动态生成实体,如果使用 JPA 就需要生成 Java 代码后进行编译,这很容易出错,不太适合低代码平台,所以使用这个方案需要实现「动态实体」功能,是整个方案最大难点。
存储的实现方案 2:使用文档型数据库
文档型数据库不需要预先定义表结构,因此它很适合用来存储用户自定义数据,这个方案实现起来比较简单,以 MongoDB 为例,可以这样做:
-
用户创建一个自定义表的时候,系统就自动创建一个 collection,所有这个表的数据都存在这个 collection 里。
-
用户新增字段的时候,就随机分配一个 fileId,后续对这个字段的操作都自动映射到这个 fileId 上,用 fileId 的好处是用户重命名字段后还能查找之前的数据,因为所有数据查询底层都基于这个 fileId。
-
查询的时候先找到对应的 collection,再通过 meta 信息查询字段对应的 fileId,使用这个 fileId 来获取数据。
这个方案的优点是实现简单,用户体验可以做得更好,是目前大部分零代码平台的选择,使用这个方案的产品也很好识别,只要看一下它的私有部署文档,如果有要求装 MongoDB 就肯定是。
但这个方案也有显著缺点:
-
无法支持外部数据库,数据是孤岛,外部数据接入只能通过导入的方式。
-
MongoDB 在国内发展缓慢,接受度依然很低,目前还没听说有哪家大公司里最重要的数据存在 MongoDB 里,一方面有历史原因,另一方面不少数据库都开始支持 JSON 字段,已经能取代大部分必须用 MongoDB 的场景了。
-
不支持高级 SQL 查询。
你可能会问,现在 MySQL、Postgres 等数据库都支持 JSON 字段类型了,是否可以用这个字段来实现低代码?答案是不太行,只适合数据量不大的场景,虽然 JSON 字段可以用来存用户自定义数据,但无法创建字段索引,比如在 MySQL 要想给 JSON 创建索引,还是得创建一个特殊的字段,这又需要 DDL 权限了,没有索引会导致这个方案无法支持大量数据查询。
在爱速搭中我们也实现这个方案,目前是基于 MySQL JSON 字段,后续可能也会支持存储使用 MongoDB,目前它的使用场景是流程执行过程中的数据存储,因此数据量不会很大,我们希望流程功能用起来可以更简单些。
它的最大特点是界面编辑和数据存储是统一的,当你拖入文本框到页面后就会自动创建对应的字段,不需要先创建数据模型再创建界面,因此用起来更简单。
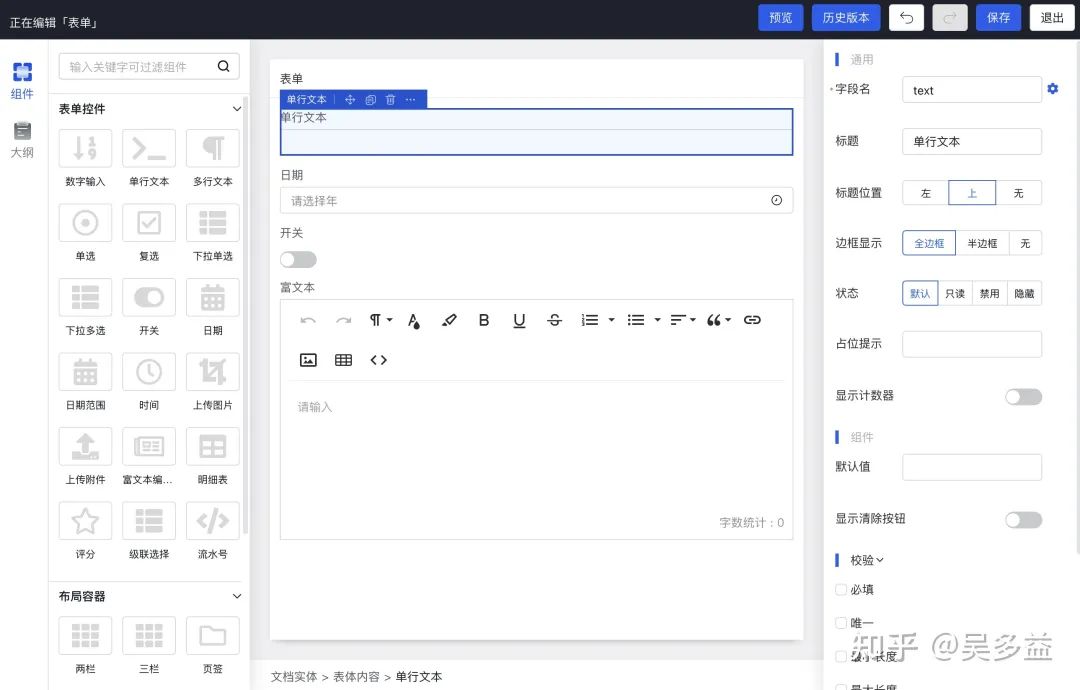
爱速搭里的表单模型
存储的实现方案 3:使用行代替列
这是很多可扩展平台里使用的技术,比较典型的是 WordPress,它的扩展性很强,装个扩展就能变成电商网站。而整个 WordPress 只有 12 个表,它是怎么做到的?方法是靠各种 meta 表,比如用于扩展文章的 wp_postmeta 表结构如下
CREATE TABLE wp_postmeta (
meta_id bigint(20) unsigned NOT NULL auto_increment,
post_id bigint(20) unsigned NOT NULL default ‘0’,
meta_key varchar(255) default NULL,
meta_value longtext,
PRIMARY KEY (meta_id),
KEY post_id (post_id),
KEY meta_key (meta_key)
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
其中的关键就是 meta_key 和 meta_value 这两个字段,相当于将数据库当 KV 存储用了,因此可以任意扩展字段名及值。
这个方案的优点是实现简单,但缺点也很明显:
-
查询性能低,如果有 10 个字段就要查 10 行。
-
无法支持 SQL 高级查询,因为数据是按行存的。
这个方案主要用于成熟项目的扩展,比如在 CRM 产品中允许用户扩展字段,但因为性能较低,并不适合通用低代码平台。
存储的实现方案 4:元信息+宽表
早期数据库不支持 JSON 字段的时候,有些开发者会预留几个列来给用户扩展自定义属性,比如在表里加上 ext1、ext2、ext3 字段,让用户可以存 3 个定制数据,基于这个原理我们可以进一步扩展,通过预留大量列来实现应用自定义存储。
这个方案最早出现在 http://force.com,具体细节可以阅读它架构说明文档。
实现它有两个关键点:元数据、预留列,这里简单说明一下原理,首先系统预先创建一个 500 列的表,比如就叫 data:
| tenant_id | table_id | uuid | value0 | value1 | … | value 4000 |
| — | — | — | — | — | — | — |
|
|
|
|
|
|
|
|
也可以创建更多,但注意有的数据库对列的数量有限制,比如 MySQL 最多是 4096 列。
上面的 data 表里主要有 4 类字段:
-
tenant_id 是租户 id,用于隔离不同租户
-
table_id 是自定义表的 id
-
uuid 是具体这一行数据的 id
-
后面的 value0 到 value500 都是预留的列,用于存储实际数据,一般使用变长字符串类型
当用户给这个表新增一个字段的时候,怎么知道这个字段放哪?这就需要另一个用于描述字段信息的元数据表,比如增加一个「标题」字段时,使用另一个 table_fields 表来描述这个字段的信息,示例如下:
| tenant_id | table_id | field_id | value_index | name | type |
| — | — | — | — | — | — |
| 1 | 1 | 0 | 0 | 标题 | string |
在这个 table_fields 表里:
-
tenant_id 和 table_id 和前面一样。
-
field_id 对应的是给这个「标题」字段分配的 id。
-
value_index 对应前面那个 data 表里预览列的位置,比如这个值是 0,就意味着 value0 列被分配给了这个「标题」字段。
-
name 用来存名称,type 用来标识类型,这样查询和写入数据的时候,首先从这里查询 value_index 是什么,然后再去前面那个预留列的表中查询对应列的值。
最终在实际查询的时候需要根据元数据表做一下转换,比如 select 标题 from blog 要转成 select value0 from data where tenal_id = 1 and table_id = 1。
要完全实现这个方案还有很多细节问题得解决,由于篇幅原因这里不详细介绍,感兴趣可以阅读前面提到的 http://force.com 技术白皮书,这里列举其中几个问题:
-
因为存储只能是字符串,所以对于日期、数字等其他类型,因此读取的时候需要根据类型使用数据库里的函数进行转换,比如
STR_TO_DATE。 -
需要单独处理唯一性功能,因为这个数据表是所有租户共用的,没法设置表级别的唯一性索引,这时就需要新建一个表来单独做,坏处是数据多份容易产生不一致,需要在所有更新操作都加事务。
-
需要单独处理索引功能,同样是因为字段是字符串,因此没法直接在
data表里加索引,如果数据存储的是数字,排序就是错的,为了解决这个问题需要另外创建一个一个包含常见字段的索引表,数据更新的时候。 -
自增字段需要自己实现。
-
元数据信息需要缓存,不然每次查询前都需要先查询元数据信息,然后再去查询真正的数据。
这个方案比前面几个方案的优点是:
- 比起第一种原生数据库表方案,它不需要 DDL 操作,不容易出问题,跟适合 SaaS 产品。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数前端工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注前端)

文末
篇幅有限没有列举更多的前端面试题,小编把整理的前端大厂面试题PDF分享出来,一共有269页

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

eEyx-1712806534854)]
[外链图片转存中…(img-5yDtWPzQ-1712806534855)]
[外链图片转存中…(img-8PoCfArh-1712806534855)]
[外链图片转存中…(img-ogj4XAtp-1712806534855)]
[外链图片转存中…(img-jsa5Jh5B-1712806534856)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注前端)
[外链图片转存中…(img-fHrhHAFO-1712806534856)]
文末
篇幅有限没有列举更多的前端面试题,小编把整理的前端大厂面试题PDF分享出来,一共有269页
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-ZbO5g5yO-1712806534856)]














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









