







第1章 正则表达式入门
进行大规模文本编辑时,需要检索重复单词(如"this this"),程序必须满足:
(1)能检查多个文件,挑出包含重复单词的行,高亮标记每个重复单词(使用标准ANSI的转义字符列),同时必须显示这行文字来自哪个文件。
(2)能跨行查找,即使两个单词一个在某行末尾而另一个在下一行的开头,也算重复单词。
(3)能进行不区分大小写的查找,例如"The the...",重复单词之间可以出现任意数量的空白字符(空格符、制表符、换行符之类)
(4)能查找用HTML tag分隔的重复单词。HTML tag用于标记互联网页上的文本,例如,粗体单词是这样表示的:”...it is <B>verry</B> very important...“
正则表达式能够添加、删除、分离、叠加、插入和修整各种类型的文本和数据
正则表达式的思维框架
完整的正则表达式有小的构建模块单元组成
检索文本文件:egrep
在指定了正则表达式和需要检索的文件之后,egrep尝试用正则表达式来匹配每个文件的每一行,并显示能够匹配的行。
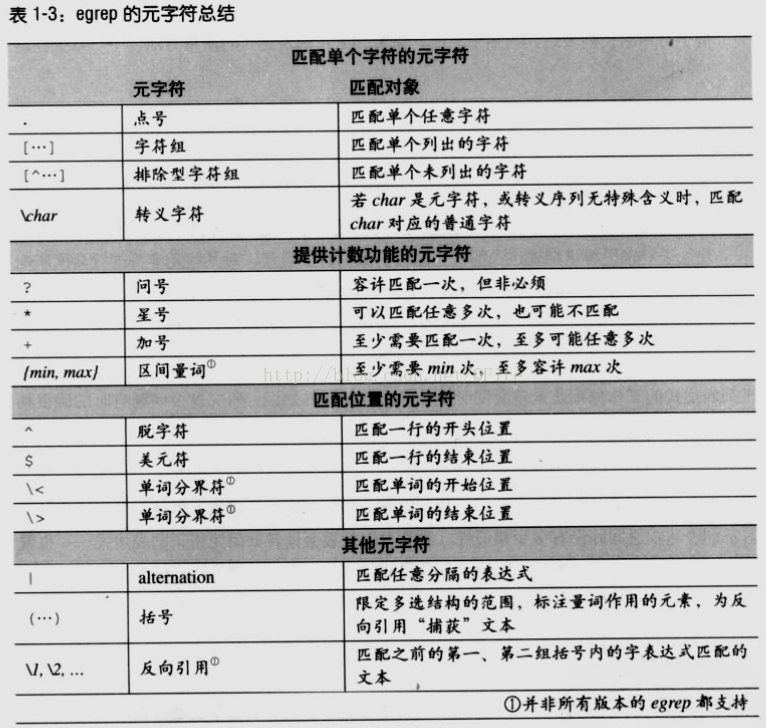
egrep元字符(Metacharacters):
^:行的开始 ^cat 表示以cat开头的行
$:结束
字符组(character classes): gr[ea]y的意思是grey 或 gray
'-'连字符表示一个范围:[0-9] [a-z],注:'-'只有在字符组内部,才是元字符,否则它就只能匹配普通的连字符号
排除型字符组:[^1-6]匹配除了1到6以外的任何字符,^表示”排除“。
匹配任意字符“.”:03.19.76可表示03/19/76、03-19-76。
匹配任意子表达式:“|” :or
忽略大小写: egrep -i .....
单词分界符:\< 和 \>为单词开头和结束,如\<cat\>
可选项元素“?”:color和colour的匹配,colou?r来解决,最多出现一次
“+”:表示“之前紧邻的元素出现一次或多次“
”*“:表示”之前紧邻的元素出现任意多次,或者不出现“
问号、加号和星号这3个元字符,统称为量词
规定重现次数的范围:长度范围
...{min, max},如...{3,12},能够容许的重现次数在3到12之间
括号及反向引用:
括号的两者用途:限制多选项的范围;将若干字符组合为一个单元,受问号或星号之类量词的作用。
反向引用:容许我们匹配与表达式先前部分匹配的同样的文本
语言的差异:
任何语言中都存在不同的方言和口音,很不幸,正则表达式也一样。情况似乎是,每一种支持正则表达式的语言都提供了自己的”改进“。正则表达式不断发展,但多年的变化也造就了数目众多的正则表达式”流派“。
正则表达式的目标:
必须进行权衡:匹配符合要求的文本,同时忽略不符合要求的文本















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









