







NLP中很多问题要求解的输出标签不是相互独立的,而是时间或结构上相互依存的结构化标签。这种结构包括序列、树状或更普通意义上的图结构。而对于中文分词、词性标注、组块标注、浅层语法分析等任务,标记和切分观察序列都是序列结构的。解决词类方法最常用的模型也是概率图模型中的序列算法。该技术基本成熟,已经被成功地用于文本检索、文本分类、信息抽取等应用之中,并对这些应用产生了实质性的帮助。
任务的顺序应该为,首先进行命名实体识别,然后进行词性标注,最后才是语义组块标注。但从算法应用策略的复杂性而言,先介绍词性标注,语义组块标注,最后是命名实体识别。
词性标注:仅仅使用最大熵算法即可得到比较高精度的结果
组块标注最常用的算法是条件随机场算法,在特征上加了词性之后,结果也不错
命名实体识别,使用了含有外部词典的条件随机场算法及多层隐马尔科夫模型(张华平)
收费资源:
宾州大学开发的汉语句法树库(Chinese Tree Bank, CTB)和汉语命题库(Chinese Proposition Bank, CPB),一个是中文短语结构树库,另一个是谓词论元库
也可用NLTK下载CTB的英文样例版,大约1000句
5.1 汉语词性标注
词性:由它在句子中的成分所决定的,这是划分词类的依据。
英文中的大多数单词是没有歧义的。但是汉语缺乏丰富的形态变化,无法从词的形态变化来判断汉语词汇的词性。而且常用词的兼类现象非常严重。
因此,汉语的词性标注的主要任务与汉语分词差别不大,主要仍是消歧问题。
宾州树库的词性标注规范
《宾州规范》在实词上与《北大规范》大同小异,但在虚词上差异较大。
最著名的是stanfordNLP的词性标注模块。遵循宾州树规范
训练模型文件
修改chinese-distsim.tagger.props即可完成训练自己的模型
5.2 语义组块标注
法国语言学家Steven Abney提出了组块(Chunk)描述体系,即句内的一个非递归的核心成分。这种成分包含核心成分的前置修饰成分,而不包含后置附属结构。他将句法分析问题分为如下三个阶段:
块识别:利用块识别器快速识别出句子中所有的块
块内结构分析:对每个块内部的成分赋予合适的句法结构
块间关系分析:利用块连接器将各个不同的块组合成完整的句法结构树
这样的好处是,一方面由于对不同的子问题的准确功能定位,可以独立地选用不同的语言模型和搜索策略加以分析处理;另一方面,通过在块层次上进行自底向上的块间关系分析和自顶向下的块内结构分析,可以大大提高整体分析效率,达到降低句子分析难度的目的。
语义组块的另一个用处在于浅层语法分析,即将语义角色标注的工作建立在浅层语法分析之上,不再使用句法解析树,而是利用分析出来的语法组块直接进行语义角色标注,希望利用相对更准确的组块分析结果提升语义角色标注准确率。
最后,最常用的一个领域是,语义组块可用于知识库的实体关系抽取。
语义组块的种类
在滨州树库中的名词短语(NP)是指中心词为名词所构成的短语,其语法功能相当于名词性成分,一般可以在句子中充当主语、宾语、定语等。从语法的角度来讲,该结构具有两种含义:一种是指按句法成分构成的短语,如组块在句子中充当主语、宾语等,这种NP可以增加辅助标签NP-Sbj、NP-Obj;另一种是指知识库中的实体和属性,这种组块称为baseNP,
(1)名词-名词复合词:NN1 NN2 ... NNi序列
(2)词级并列结构:
(3)有NR(专有名词)加上一个或多个NN所组成的专有名词NR+NN组成的专有名词,组织或公司名称、姓名+称谓
(4)日期与地点:
所谓动词短语(VP)就是以动词为中心,与其修饰、限定或并列成分共同构成的一种语义组块,除中心动词表达的行为之外,其修饰和限定成分更明确和具体化动作的语义。有复合动词短语、动词+体标记(如了、着、过)
语义块的抽取
使用CRF来进行语义块的识别,使用的语料一般为Penn TreeBank的CTB树库语料(标注方法为短语结构法)。
需要通过如下三个阶段来完成:
(1)将Penn TreeBank树库中的语料从树状结构变为序列结构:转换程序https://github.com/rainarch/ChunkLinkCTB在Perl环境下运行。
IOB表示法,推荐使用IOB的一个变种---start/end表示法,在中文分词中最常使用的就是这种方法,其优势是可对序列表达更为细致。
(2)使用CRF算法对制作好的语料进行训练,生成模型
工具包:CRF++和CRFsuite
(3)使用训练的结果,测试组块标注
https://github.com/rainarch/ChunkLinkCTB
# perl chunklinkctb.pl -fhHct 源文件.mrg > 目标文件.chunk
https://taku910.github.io/crfpp/#download
% ./configure
% make
% make install
# ldconfighttp://www.threedweb.cn/thread-1589-1-1.html
从
../../crf_learn template chtb_utf8_sample.chunk chunkmodel
5.3 命名实体识别
命名实体识别技术是未登录词中数量最多、识别难度最大、对分词效果影响最大的问题,是信息提取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。
分词架构与专名词典
一个大型分词系统的简单架构:
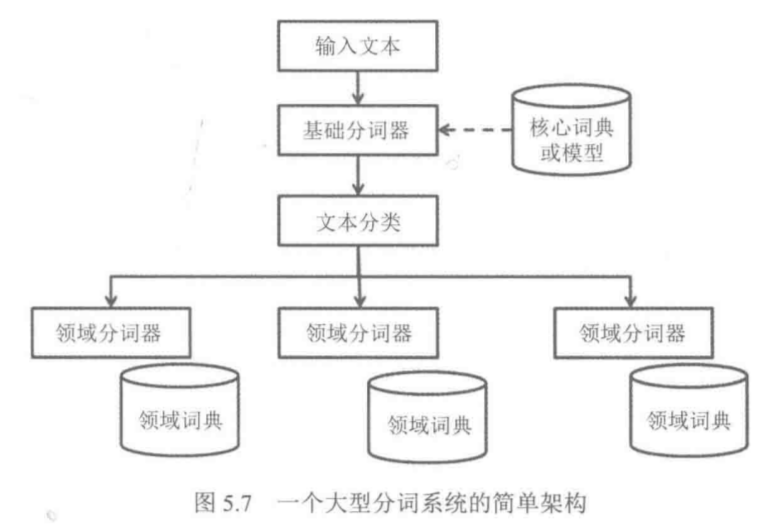
执行步骤如下:
(1)将输入文本先使用核心词典进行基础分词处理
(2)对分词结构的文本再按所属领域计算文本所属的分类
(3)根据文本所属的领域不同,执行使用领域专属的分词器,再对领域内的专名进行分词
上述架构的特点,将分词器针对不同领域做了优化。
一种设计思路是将命名实体任务从中文分词的基础模块中分离出来,Ltp和Stanford NLP中如此
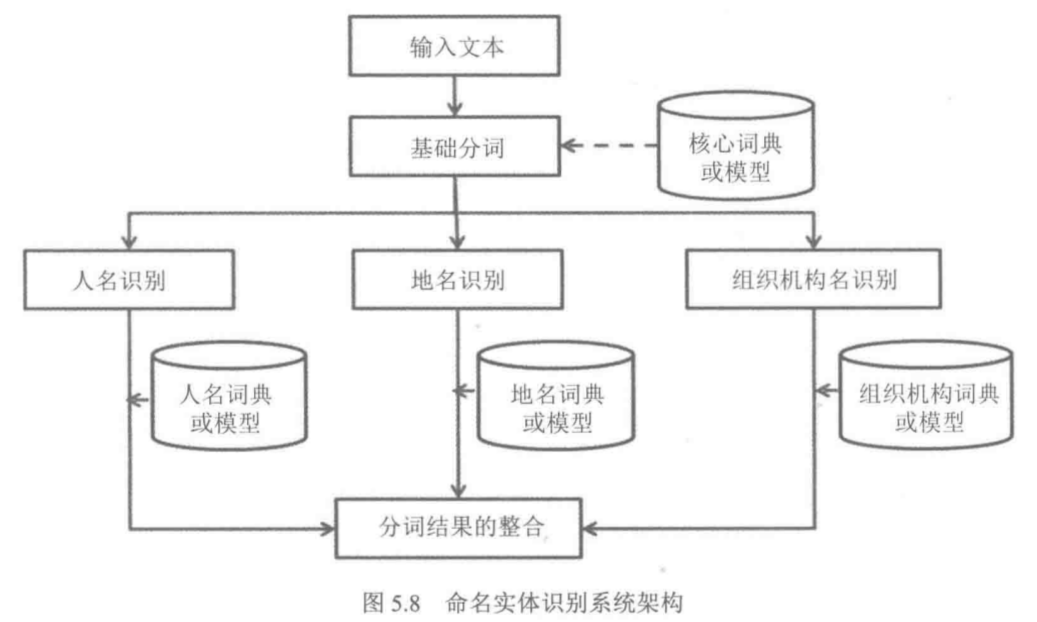
算法的策略----词典与统计相结合
以Ltp为案例,简要剖析词典与CRF算法结合如何实现领域自适应的中文分词
http://www.threedweb.cn/thread-1394-1-2.html
http://www.threedweb.cn/thread-1396-1-1.html
算法的策略---层叠式架构
NLP中常用的层叠式架构包括:层叠式HMM和层叠式CRF
HanLP分析















 3200
3200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









