







无论是与其他NoSQL存储相比,还是与传统的关系型数据库相比,图数据库都具有显著的好处。但是一旦选择了图数据库,接下来我们就会问:如何使用图来建模呢?
3.1 模型和目标
建模是为了让不规则的领域的一些具体方面变成结构化的、可操纵的空间。对于事物实际存在的方式,并没有一种天然的表达方式,我们只能有目的地选择、抽象和简化,一些方法能更好地满足某个特定目标。
在这方面,用图来表示也没有什么不同。图建模与其他建模技术的不同之处在于其逻辑模型和物理模型之间有更加密切的关系。关系型数据管理技术背离了用自然的语言来描述领域:先是哄骗我们将其表述成逻辑模型,然后再生硬地将其转换成物理模型。这些转换使得概念化的世界和模型的数据库实例之间产生了语义失调。但如果使用图数据库,这个分歧明显地缩小了。
3.2 带标签的属性图模型
3.3 查询图:Cypher简介
Cypher是一种言简意赅的图数据库查询语言。尽管现在它还是Neo4j特有的语言,但它和我们使用示意图来表示图的方式非常相似,因此非常适合程序化地描述图。(不同的图数据库有不同的查询数据的方式。很多图数据库(包括Neo4j)都支持资源描述框架RDF查询语言SPARQL,也支持必要的基于路径的查询语言Gremlin)
Cypher的理念:通俗一点说就是,我们让数据库去”找类似于这样的数据“,而我们描述”这样的数据方式就是用ASCII字符画把它们画出来。
ASCII字符画模式是Cypher的根基。一个Cypher查询使用断言将模式的一个或多个部分锚定到图的具体位置上,然后通过缩小没有被锚定的范围来寻找附近的匹配。与大多数的查询语言一样,Cypher也是有子句组成的。
寻找用户Jim的共同朋友
MATCH (a:Person {name:'Jim'})-[:KNOWS]->(b)-[:KNOWS]->(c),
(a)-[:KNOWS]->(c)
RETURN b, c
MATH子句:Cypher查询的核心。用()表示节点,-->和<--表示联系
RETURN子句指明在已经匹配查询的数据中,哪些节点、联系和属性是需要返回给客服端的。
WHERE子句:提供过滤模式匹配结构的条件
CREATE和CREATE UNIQUE:用来创建节点和联系
MERGE:保证给出的模式在图中一定存在,要么复用已经存在的与断言匹配的节点和联系,要么创建新的节点和联系。
DELETE:删除节点、联系以及属性
SET:用来设置属性值
FOREACH:对一个列表中的每个元素执行更新操作。
UNION:合并两个或更多查询的结果
WITH:链式查询,前一个查询的结果作为后一个查询的条件。
START:在图中指定一个或多个起始点,它可以是节点,也可以是联系
3.4 关系建模和图建模对比
关系世界建模的最初阶段和其他很多数据建模是一样的:我们寻求对这一领域中实体的理解,它们是如何相关联的,以及它们状态变化的规律。画实体-联系图(ER图),它将概念模型转换成逻辑模型。
图建模和领域模型是完全同构的。
测试模型:验证它对我们真实的查询到底适不适合。
3.5 跨域模型
商业洞察力往往依赖于我们对复杂的价值链背后的网络效应的理解。为了到达一定程度的理解,我们需要联合多个领域,同时又不能让每个领域的细节失真或者牺牲掉。属性图为这种情况提供了解决方案。使用属性图,我们可以给一个价值链建模,使其成为一个图的集合,每张图里都由具体的联系关联其子领域,又能将它们区别开来。
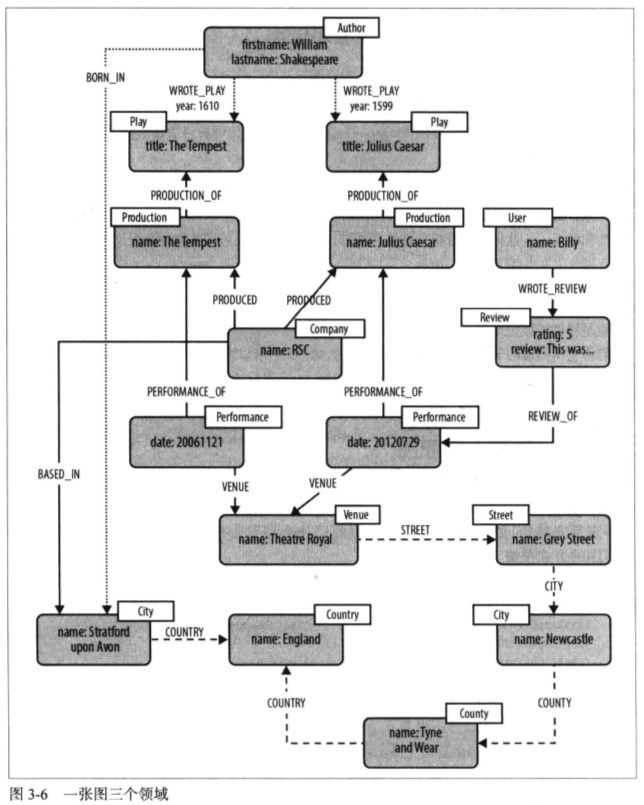
P50 图中呈现了莎士比亚文学的生产和消费的价值链。关于莎士比亚和他的几个戏剧,还有一个最近才上演了这些戏剧的公司的详细信息,再加上一个演出地点和一些地理数据,一则评价。总之,这个图描述了
三个不同的领域,并把它们关联起来。在示意图中,我们可以用不同样式的联系区别它们:短虚线用来表示文学领域,实线用来表示戏剧领域,长虚线用来表示地理信息领域。
1)文学领域



2)戏剧领域


3)地理数据领域

创建莎士比亚图:
CREATE (shakespeare:Author {firstname:'William', lastname:'Shakespeare'}),
(juliusCaesar:Play {title:'Julius Caesar'}),
(shakespeare)-[:WROTE_PLAY {year:1599}]->(juliusCaesar),
(theTempest:Play {title:'The Tempest'}),
(shakespeare)-[:WROTE_PLAY {year:1610}]->(theTempest),
(rsc:Company {name:'RSC'}),
(production1:Production {name:'Julius Caesar'}),
(rsc)-[:PRODUCED]->(production1),
(production1)-[:PRODUCTION_OF]->(juliusCaesar),
(performance1:Performance {date:20120729}),
(performance1)-[:PERFORMANCE_OF]->(production1),
(production2:Production {name:'The Tempest'}),
(rsc)-[:PRODUCED]->(production2),
(production2)-[:PRODUCTION_OF]->(theTempest),
(performance2:Performance {date:20061121}),
(performance2)-[:PERFORMANCE_OF]->(production2),
(performance3:Performance {date:20120730}),
(performance3)-[:PERFORMANCE_OF]->(production1),
(billy:User {name:'Billy'}),
(review:Review {rating:5, review:'This was awesome!'}),
(billy)-[:WROTE_REVIEW]->(review),
(review)-[:RATED]->(performance1),
(theatreRoyal:Venue {name:'Theatre Royal'}),
(performance1)-[:VENUE]->(theatreRoyal),
(performance2)-[:VENUE]->(theatreRoyal),
(performance3)-[:VENUE]->(theatreRoyal),
(greyStreet:Street {name:'Grey Street'}),
(theatreRoyal)-[:STREET]->(greyStreet),
(newscastle:City {name:'Newcastle'}),
(greyStreet)-[:CITY]->(newscastle),
(tyneAndWear:Country {name:'Tyne and Wear'}),
(newscastle)-[:COUNTRY]->(tyneAndWear),
(england:Country {name:'England'}),
(tyneAndWear)-[:COUNTRY]->(england),
(stratford:City {name:'Stratford upon Avon'}),
(stratford)-[:COUNTRY]->(england),
(rsc)-[:BASED_IN]->(stratford),
(shakespeare)-[:BORN_IN]->(stratford)
在实际使用中,如果不在乎重复数据,我们将倾向于使用CREATE,但如果领域里不允许出现重复数据,我们就使用MERGE

开始查询:通常从一个或多个熟悉的起始点开始查询,也就是所谓的“绑定”节点,如找到所有在Newcastle的皇家剧院演出的莎士比亚戏剧
MATCH (theater:Venue {name:'Theatre Royal'}),
(newcastle:City {name:'Newcastle'}),
(bard:Author {lastname:'Shakespeare'}),
(newcastle)<-[:STREET|CITY*1..2]-(theater)
<-[:VENUE]-()-[:PERFORMANCE_OF]->()
-[:PRODUCTION_OF]->(play)<-[:WROTE_PLAY]-(bard)WHERE w.year > 1608
RETURN DISTINCT play.title AS play- 匹配的子图中必须有(或者没有)限制的路径
- 节点必须有指定的标签或者指定名字的联系
- 在匹配的节点或联系上的某个属性必须有(或者没有)特定的属性,无论它们的值是什么
- 在匹配的节点或联系上的某个属性必须有特定的属性值
- 必须满足其他任意复杂的表达式断言(例如,在某个特定的日期或者之前必须有演出上演。
处理结果:RETURN,DISTINCT能保证返回的结果是唯一的。
查询链:有时候用一个MATCH得到一切你想要的,可能是不切实际的(或是不可能的)。WITH子句允许我们将几个匹配连接到一起,将前一个查询的结果当做条件输送到下一个查询中去。
3.6 建模时常见的陷阱
虽然图建模是掌握复杂的问题域的一种极具表现力的方式,但只有表现力并不能保证每一个图都适合其用途。事实上,即便是那些每天都和图打交道的人也可能会犯错。















 8366
8366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









