







服务器拒绝处理表单,IP地址被封杀。如何克服网站阻止自动采集
12.1 道德规范
为什么要教采集 :
- 采集那些不想被采集的网站时,其实存在一些非常符合道德和法律规范的理由
- 不太可能建立一个完全“防爬虫”的网站
- 和大多数程序员一样,从来不相信禁止某一类信息的传播就可以让世界变得更和谐
12.2 让网站机器人看起来像人类用户
网站防采集的前提是要正确地区分人类访问用户和网络机器人。
修改请求头:HTTP定义了十几中古怪的请求头类型,不过大多数都不常用。只有下面的七个字段被大多数浏览器用来初始化所有网络请求


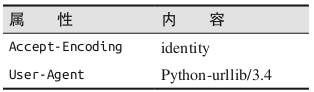
经典的Python爬虫在使用urllib标准库时,都会发送如下的请求头:
import requests
from bs4 import BeautifulSoup
session = requests.Session()
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit 537.36 (KHTML, like Gecko) Chrome",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"}
url = "http://www.whatismybrowser.com/developers/what-http-headers-is-my-browser-sending"
req = session.get(url, headers=headers)
bsObj = BeautifulSoup(req.text)
print(bsObj.find("table",{"class":"table-striped"}).get_text)处理cookie:网站会用cookie跟踪你的访问过程,如果发现了爬虫异常行为就会中断你的访问,比如特别快速地填写表单,或者浏览大量页面。虽然这些行为可以通过关闭并重新连接或者改变IP地址来伪装,但是如果cookie暴露了你的身份,再多努力也是白费。
一些浏览器插件可以为你显示访问网站和离开网站是cookie是如何设置的。EditThisCookie(http://www.editthiscookie.com/)就是我最喜欢的Chrome浏览器插件之一。
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='phantomjs-2.1.1-linux-x86_64/bin/phantomjs')
driver.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver.get_cookies())from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='phantomjs-2.1.1-linux-x86_64/bin/phantomjs')
driver.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver.get_cookies())
savedCookies = driver.get_cookies()
driver2 = webdriver.PhantomJS(executable_path='phantomjs-2.1.1-linux-x86_64/bin/phantomjs')
driver2.get("http://pythonscraping.com")
driver2.delete_all_cookies()
for cookie in savedCookies:
driver2.add_cookie(cookie)
driver2.get("http://pythonscraping.com")
driver2.implicitly_wait(1)
print(driver2.get_cookies())12.3 常见表单安全措施
如果网络机器人在你的网站上创造了几千个账号并开始向所有用户发送垃圾邮件,就是一个大问题了。
隐含输入字段值:表单中,“隐含”字段可以让字段的值对浏览器可见,但是对用户不可见。主要用于阻止爬虫自动提交表单。
第一种是一个字段可以用服务器生成的随机变量表示。最佳方法是,首先采集随机变量,然后再提交到表单处理页面。
第二种是“蜜罐”,具有普通名称的隐含字段,通过CSS设置成对用户不可见,但bot填写了
避免蜜罐:通过Selenium中is_displayed()可以判断元素在页面上是否可见。
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
driver = webdriver.PhantomJS(executable_path='phantomjs-2.1.1-linux-x86_64/bin/phantomjs')
driver.get("http://pythonscraping.com/pages/itsatrap.html")
links = driver.find_element_by_tag_name("a")
for link in links:
if not link.is_displayed():
print("The link "+link.get_attribute("href")+" is a trap")
fields = driver.find_element_by_tag_name("input")
for field in fields:
if not field.is_displayed():
print("Do not change value of "+field.get_attribute("name"))12.4 问题检查表
如果你一直被网站封杀却找不到原因,那么这里有个检查列表,可以帮你诊断一下问题出在哪里。















 1715
1715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









