







新闻开始通过精确推荐增强用户使用黏性,最终做到千人千面,完成“读新闻”到“消费内容”的转变。
虽然新闻资讯类的竞争已经白热化,但在各个垂直领域仍大有可为。如,程序员看IT新闻,星座爱好者研究每日运势,股民研究上市公司的动向。
具有以下特点:
- 垂直分类,满足不同人群的兴趣和需求。
- 内容时效性强,需及时更新。
- 内容丰富,多种媒体共存(图片、视频、直播)。
根据新闻资讯类产品的特点制定了技术手段,如垂直分类可以用duoTab按类别展示、用下拉刷新保证及时更新,支持图文等。
5.1 项目介绍
http://www.cnblogs.com博客园开放了博客和新闻接口,我们用这些接口实现一个小程序客户端。
关键知识点:tabBar、网络请求、图片、页面路由、数据缓存、XML解析、下拉刷新、模板、文件导入、可滚动视图区域等
项目结构:分server端和client端,其中server端采用PHP,用来将XML格式的数据转化为JSON格式;
blog_rss.php #获取最新20条博客
post_rss.php #全文内容
news_rss.php #获取新闻列表
proxy.php #图片代理
function.php #公共函数
rss_php.php #解析XML的库
cache #缓存目录
(1)将server目录上传到PHP的服务器cnblogs目录内
(2)utils/commo.js中baseUrl = 'http://wxamples.com/cnblogs/';
设置中不进行证书和安全域名,发布时请读者自行配置HTTPS证书和安全域名。
5.2 server端及API接口
用了博客园3个API接口
(1)博客园获取最新20条博客的接口:
http://wcf.open.cnblogs.com/blog/sitehome/recent/20
(2)博客园提供的全文内容接口:
http://wcf.open.cnblogs.com/blog/post/body/{id}其中,id是博客的唯一标识
(3)获取新闻列表的接口,是典型的RSS订阅地址:
http://feed.cnblogs.com/news/rss
返回结果均为XML结构。需要将其处理为JSON格式。blog_rss.php
由于博客列表不是每时每刻都有新博客出现,因此我们采用缓存机制提高性能。
<?php
include './function.php';
$filename = './cache/blog_rss.html';
$response = '';
if (!file_exists($filename) || rand(0, 10) == 1) { #90%的概率读取缓存
$response = curl_get('http://wcf.open.cnblogs.com/blog/sitehome/recent/20');
if (!$response) {
echo "cURL Error";
exit(0);
} else {
if (is_writable($filename)) {
file_put_contents($filename, $response);
}
}
} else {
$response = file_get_contents($filename);
}
echo xmltojson($response);
<?php
include './function.php';
$post_id = isset($_GET['id'])?intval($_GET['id']):exit('缺失id参数');
$response = curl_get('http://wcf.open.cnblogs.com/blog/post/body/' . $post_id);
if (!$response) {
echo "cURL Error";
exit(0);
}
$isMatched = preg_match('/<string>(.*?)<\/string>/ms', $response, $matches);
$text = strip_tags(htmlspecialchars_decode($matches[1])); #处理HTML
echo json_encode([$text]);
<?php
include './function.php';
include './rss_php.php';
$filename = './cache/news_rss.html';
$response = '';
if (!file_exists($filename) || rand(0, 10) == 1) {
$response = curl_get('http://feed.cnblogs.com/news/rss');
if (!$response) {
echo "cURL Error";
exit(0);
} else {
if (is_writable($filename)) {
file_put_contents($filename, $response);
}
}
} else {
$response = file_get_contents($filename);
}
$rss = new rss_php(); #rss解析库,将RSS订阅内容转换为数组
$rss->loadRSS($response);
echo json_encode($rss->getRSS());
5.3 博客列表页
发起网络请求、获得JSON数据,从JSON中解析出博客列表
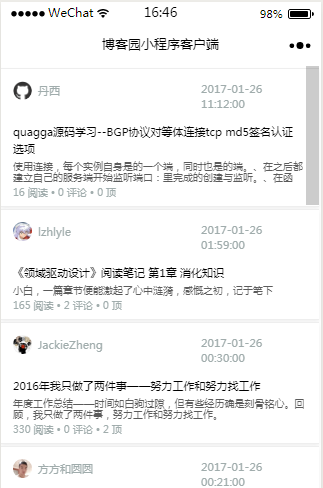
程序的主体是对feeds的列表渲染,设置每个条目的标题、作者、发布时间、简介、阅读数、评论数和赞数。
博客列表页与博客详情页包括的信息基本相同,唯一的差异是列表页显示简介、详情页展示全文。基于此,我们采用模板简化代码。
<!--pages/blog/index.wxml-->
<import src="postItem.wxml" />
<scroll-view scroll-y="true" class="container" upper-threshold="5" bindscrolltoupper="upper">
<block wx:for="{{feeds}}" wx:key="id">
<template is="postItem" data="{{item}}" />
</block>
</scroll-view>blog/postItem.wxml
<template name="postItem">
<view class="feed-item" bindtap="bindViewTap" data-blogid="{{item.id}}">
<view class="feed-source">
<view class="avatar">
<image src="{{item.avatar}}"></image>
</view>
<text>{{item.name}}</text>
<text class="item-more">{{item.pubDate}}</text>
</view>
<view class="feed-content">
<view class="entry">
<text class="entry-title">
{{item.title}}
</text>
</view>
<view class="statistics-body">
<view>
<text class="statistics-txt">
<block wx:if="{{item.detail == 1}}"> {{item.content}} </block>
<block wx:else> {{item.summary}}</block>
</text>
</view>
<view class="statistics-actions">
{{item.views}} 阅读 • {{item.comments}} 评论 • {{item.diggs}} 顶
</view>
</view>
</view>
</view>
</template>
5.4 博客详情页
5.5 新闻列表页
tabBar

5.6 新闻详情页
5.7 公共JS脚本
utils里面common.js和feed.js(将内容解析为博客或新闻)















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









