







文章目录
一、LDA的双重身份:降维工具与主题模型
LDA(Linear Discriminant Analysis)在机器学习领域有两种经典应用场景:
- 线性判别分析:一种监督学习的降维技术,通过最大化类间距离与最小化类内距离实现分类优化。
- 隐含狄利克雷分布(Latent Dirichlet Allocation):一种无监督生成式模型,用于从文本中挖掘潜在主题。
两者名称相同但应用场景迥异,需根据上下文区分。
二、核心原理详解
1. 线性判别分析(监督学习降维)
- 核心思想:寻找投影方向使同类样本聚集、异类样本分离。
- 数学实现:
- 计算类内散度矩阵 ( S_W ) 和类间散度矩阵 ( S_B )
- 通过广义特征值分解求解最优投影矩阵[[8]]。
- 适用场景:高维数据分类(如人脸识别)、数据可视化前处理。
2. LDA主题模型(无监督文本分析)
- 生成过程假设:
- 每篇文档由多个主题混合生成,每个主题对应词分布[[2]]
- 采用Dirichlet-Multinomial共轭结构建模文档-主题-词关系[[3]]
- 参数推断:常用吉布斯采样或变分推断求解隐变量[[7]]。
三、方法演变与改进
1. 算法层面的演进
- 从pLSA到LDA:引入Dirichlet先验解决过拟合问题
- 动态主题模型:结合时间序列分析主题演化规律
- 神经LDA:融入深度学习提升语义表达能力
2. 工程优化方向
- 主题数量选择:
通过困惑度(Perplexity)或主题连贯性(Coherence)评估最优K值 - 时间窗口划分:
结合领域知识与生命周期理论优化主题演化分析
四、实战技巧总结
1. 数据预处理关键点
- 文本处理:去停用词、词形还原、TF-IDF加权
- 数值特征:标准化处理提升LDA分类效果
2. 参数调优建议
| 模型类型 | 关键参数 | 推荐范围 |
|---|---|---|
| 主题模型 | α (文档-主题先验) | 0.1-1.0 |
| 分类模型 | 正则化系数 | 根据样本平衡性调整 |
3. 可视化工具
- 主题模型:pyLDAvis展示主题空间分布
- 降维结果:matplotlib/seaborn绘制分类边界
五、案例
以下是一个完整的主题建模代码示例,涵盖了文本预处理、LDA模型训练、困惑度评估最优主题数 K、结果可视化以及详细的代码解释。
案例应用
# 导入必要的库
import matplotlib.pyplot as plt
import gensim
from gensim import corpora, models
from nltk.tokenize import RegexpTokenizer
from stop_words import get_stop_words
from nltk.stem.porter import PorterStemmer
import numpy as np
import pyLDAvis.gensim_models as gensimvis
import pyLDAvis
# 文本预处理函数
def preprocess(documents):
tokenizer = RegexpTokenizer(r'\w+') # 初始化正则表达式分词器
en_stop = get_stop_words('en') # 获取英文停用词列表
p_stemmer = PorterStemmer() # 初始化词干提取器
texts = [] # 存储预处理后的文档
for doc in documents:
raw = doc.lower() # 转换为小写
tokens = tokenizer.tokenize(raw) # 分词
stopped_tokens = [token for token in tokens if token not in en_stop] # 去除停用词
stemmed_tokens = [p_stemmer.stem(token) for token in stopped_tokens] # 词干化
texts.append(stemmed_tokens)
return texts
# 示例文档(增加至10个)
doc_a = "Broccoli is good to eat. My brother likes to eat good broccoli, but not my mother."
doc_b = "My mother spends a lot of time driving my brother around to baseball practice."
doc_c = "Some health experts suggest that driving may cause increased tension and blood pressure."
doc_d = "I often feel pressure to perform well at school, but my mother never seems to drive my brother to do better."
doc_e = "Health professionals say that broccoli is good for your health."
doc_f = "Artificial intelligence is revolutionizing technology and transforming industries worldwide."
doc_g = "Machine learning algorithms can analyze large datasets and make predictions with high accuracy."
doc_h = "Renewable energy sources like solar and wind power are essential for sustainable development."
doc_i = "Climate change poses significant challenges to ecosystems and human societies globally."
doc_j = "The future of transportation lies in electric vehicles and autonomous driving technologies."
doc_set = [doc_a, doc_b, doc_c, doc_d, doc_e, doc_f, doc_g, doc_h, doc_i, doc_j]
# 预处理文本
texts = preprocess(doc_set)
# 构造词典和语料库
dictionary = corpora.Dictionary(texts) # 创建词典
corpus = [dictionary.doc2bow(text) for text in texts] # 转换为文档-词频矩阵
# 模型训练与困惑度评估
def compute_perplexity(corpus, dictionary, max_topics=10):
perplexities = []
for num_topics in range(2, max_topics + 1): # 测试不同主题数
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
num_topics=num_topics,
id2word=dictionary,
passes=20,
random_state=42 # 固定随机种子以确保结果可重复
)
perplexity = lda_model.log_perplexity(corpus) # 计算困惑度
perplexities.append(perplexity)
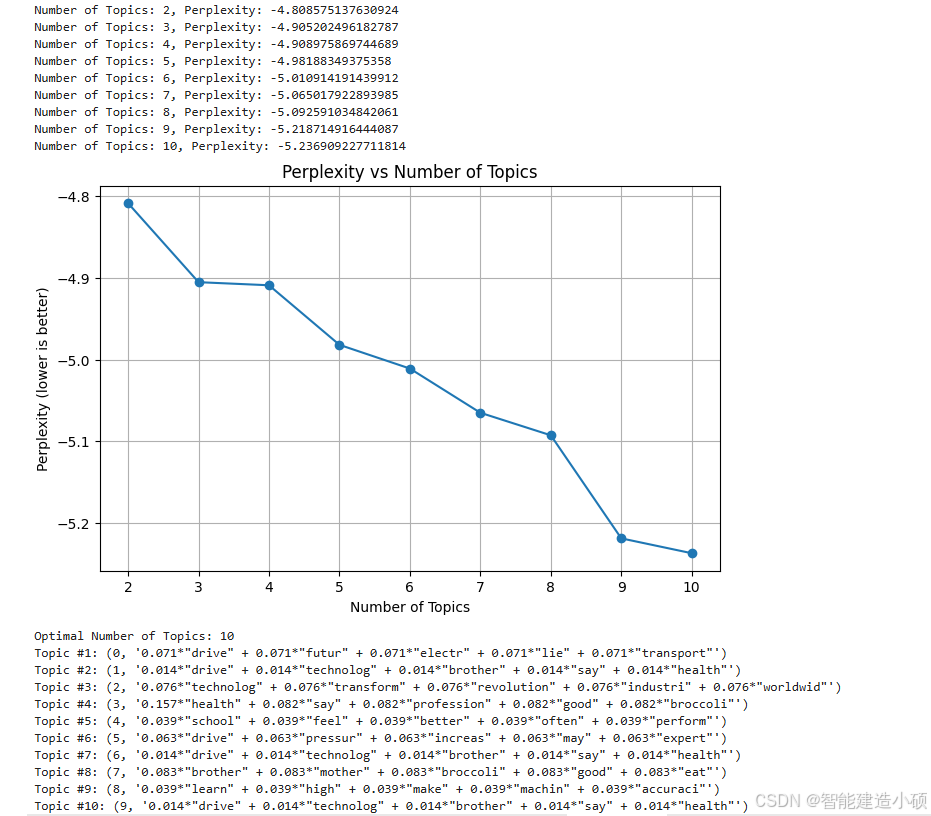
print(f"Number of Topics: {num_topics}, Perplexity: {perplexity}")
return perplexities
# 计算困惑度并绘制曲线
max_topics = 10
perplexities = compute_perplexity(corpus, dictionary, max_topics=max_topics)
# 绘制困惑度曲线
plt.figure(figsize=(8, 5))
plt.plot(range(2, max_topics + 1), perplexities, marker='o')
plt.title("Perplexity vs Number of Topics")
plt.xlabel("Number of Topics")
plt.ylabel("Perplexity (lower is better)")
plt.grid(True)
plt.show()
# 选择最优主题数(这里假设我们选择困惑度最低的主题数)
optimal_topics = perplexities.index(min(perplexities)) + 2 # 因为从2开始计数
# 使用最优主题数训练最终的LDA模型
final_lda_model = gensim.models.ldamodel.LdaModel(
corpus,
num_topics=optimal_topics,
id2word=dictionary,
passes=20,
random_state=42
)
# 打印主题内容
print("Optimal Number of Topics:", optimal_topics)
topics = final_lda_model.print_topics(num_words=5)
for idx, topic in enumerate(topics):
print(f"Topic #{idx+1}: {topic}")
# 可视化主题模型
lda_visualization = gensimvis.prepare(final_lda_model, corpus, dictionary, mds="mmds", R=30)
pyLDAvis.display(lda_visualization)

高级应用:知道全局主题及主题词确定不同主题随时间的演变
import pandas as pd
import numpy as np
from gensim import corpora, models
from nltk.tokenize import RegexpTokenizer
from stop_words import get_stop_words
from nltk.stem.porter import PorterStemmer
from sklearn.metrics import pairwise_distances
from scipy.optimize import linear_sum_assignment
import matplotlib.pyplot as plt
# 示例数据(包含时间戳)
data = [
{"text": "Broccoli is good to eat.", "date": "2020-01"},
{"text": "My brother likes to eat broccoli.", "date": "2020-01"},
{"text": "Driving may cause increased tension.", "date": "2020-02"},
{"text": "I often feel pressure at school.", "date": "2020-02"},
{"text": "Artificial intelligence is revolutionizing technology.", "date": "2020-03"},
{"text": "Machine learning algorithms are powerful.", "date": "2020-03"},
{"text": "Climate change poses challenges globally.", "date": "2020-04"},
{"text": "The future of transportation lies in EVs.", "date": "2020-04"},
]
# 转换为 DataFrame
df = pd.DataFrame(data)
# 文本预处理函数
def preprocess(text):
if not isinstance(text, str):
return []
tokenizer = RegexpTokenizer(r'\w+')
en_stop = get_stop_words('en')
p_stemmer = PorterStemmer()
try:
tokens = tokenizer.tokenize(text.lower())
stopped_tokens = [token for token in tokens if token not in en_stop]
stemmed_tokens = [p_stemmer.stem(token) for token in stopped_tokens]
except Exception:
return []
return stemmed_tokens
# 预处理所有文本
df['tokens'] = df['text'].apply(preprocess)
df = df[df['tokens'].apply(len) > 0]
# 构造全局词典
all_tokens = [token for doc in df['tokens'] for token in doc]
dictionary = corpora.Dictionary([all_tokens])
# 按时间窗口划分
time_windows = df.groupby('date')['tokens'].apply(list)
dates = sorted(time_windows.index)
# 训练全局LDA模型(用于初始化主题)
global_corpus = [dictionary.doc2bow(doc) for doc in df['tokens']]
global_lda = models.LdaModel(global_corpus, num_topics=2, id2word=dictionary, passes=10)
# 手动定义主题标签(基于全局主题的关键词)
def assign_topic_labels(topic_keywords):
label_mapping = {}
for topic_id, words in topic_keywords.items():
# 根据关键词手动分配标签
if any(word in ["broccoli", "eat", "health"] for word in words):
label_mapping[topic_id] = "Health & Environment-related "
elif any(word in ["intellig", "algorithm", "technolog"] for word in words):
label_mapping[topic_id] = "Technical "
else:
label_mapping[topic_id] = f"未分类主题{topic_id}"
return label_mapping
# 获取全局主题关键词
global_topic_keywords = {
0: [word for word, _ in global_lda.show_topic(0, topn=10)],
1: [word for word, _ in global_lda.show_topic(1, topn=10)]
}
label_mapping = assign_topic_labels(global_topic_keywords) # 主题标签映射
# 主题对齐与演化分析
aligned_topics = {}
topic_keywords = {}
topic_labels = {} # 存储每个时间窗口的主题标签
for date in dates:
docs = time_windows[date]
corpus = [dictionary.doc2bow(doc) for doc in docs]
lda_model = models.LdaModel(corpus, num_topics=2, id2word=dictionary, passes=10)
# 计算当前窗口主题与全局主题的相似度
similarity_matrix = np.zeros((2, 2))
for i in range(2):
global_topic = global_lda.get_topic_terms(i, topn=10)
for j in range(2):
current_topic = lda_model.get_topic_terms(j, topn=10)
vec_global = np.zeros(len(dictionary))
vec_current = np.zeros(len(dictionary))
for (word_id, _) in global_topic:
vec_global[word_id] = 1
for (word_id, _) in current_topic:
vec_current[word_id] = 1
similarity = 1 - pairwise_distances([vec_global], [vec_current], metric='cosine')[0][0]
similarity_matrix[i, j] = similarity
# 使用匈牙利算法对齐主题编号
row_ind, col_ind = linear_sum_assignment(-similarity_matrix)
# 保存对齐后的主题信息
aligned_topics[date] = [lda_model.print_topic(col_ind[i]) for i in range(2)]
current_keywords = [dict(lda_model.show_topic(col_ind[i], topn=5)) for i in range(2)]
topic_keywords[date] = current_keywords
# 分配语义化标签(根据全局标签映射) [[5]][[8]]
current_labels = [label_mapping[i] for i in row_ind]
topic_labels[date] = current_labels
# 提取主题强度(基于文档-主题分布)
topic_strength = {label: [] for label in label_mapping.values()}
for date in dates:
docs = time_windows[date]
corpus = [dictionary.doc2bow(doc) for doc in docs]
doc_topics = [global_lda[doc] for doc in corpus]
avg_strength = {label: 0 for label in label_mapping.values()}
label_count = {label: 0 for label in label_mapping.values()}
for dt in doc_topics:
for topic_id, prob in dt:
label = label_mapping[topic_id]
avg_strength[label] += prob
label_count[label] += 1
for label in avg_strength:
avg_strength[label] /= label_count[label] if label_count[label] > 0 else 1
topic_strength[label].append(avg_strength[label])
# 可视化主题演化趋势(使用语义化标签) [[7]]
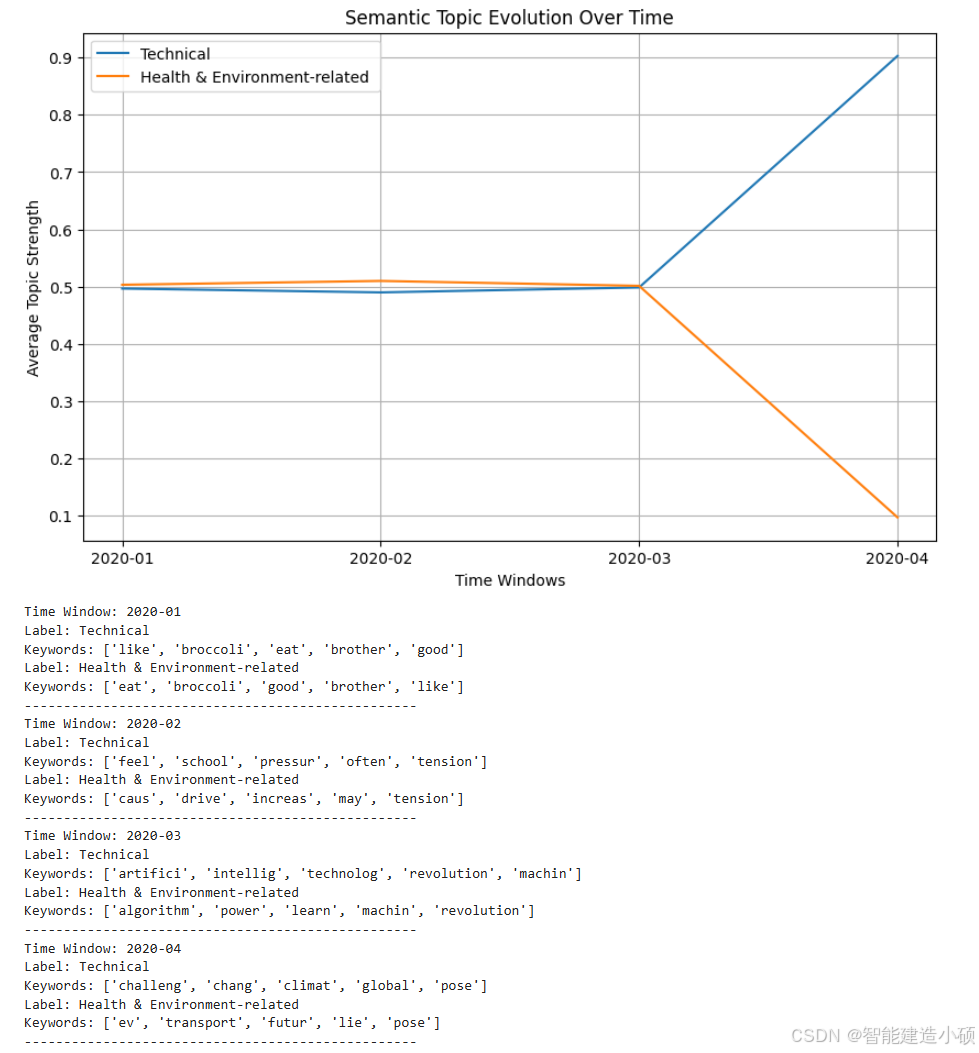
plt.figure(figsize=(10, 6))
for label in topic_strength:
plt.plot(dates, topic_strength[label], label=label)
plt.title("Semantic Topic Evolution Over Time")
plt.xlabel("Time Windows")
plt.ylabel("Average Topic Strength")
plt.legend()
plt.grid(True)
plt.show()
# 打印对齐后的主题标签与关键词
for date in dates:
print(f"Time Window: {date}")
for i, label in enumerate(topic_labels[date]):
print(f"Label: {label}")
print(f"Keywords: {list(topic_keywords[date][i].keys())}")
print("-" * 50)
-end-


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











