









在我的Java并发学习笔记专栏的前四篇文章中,讲述了关于Java锁机制、乐观锁和悲观锁以及AQS、Reentrantlock、volatile关键字、ThreadLocal类等关于Java并发的内容。
本篇将讲述Java中的ConcurrentHashMap是如何解决线程安全问题的,分JDK1.7和JDK1.8两个版本来介绍。
前言
HashMap是用于存储存在映射关系的键值对的集合,但是HashMap是线程不安全的,在并发环境下会出现脏读脏写的问题,在JDK1.7版本的HashMap中甚至会出现著名的环形链表的问题,不过环形链表在JDK1.8中由于将头插法改为尾插法而被解决了。
关于HashMap在并发下出现的问题在本文不做详细介绍,不过有一个视频我也推荐大家看看,视频链接点这里,我觉得这个视频把HashMap出现死循环的过程讲的特别清楚,值得一看。
HashTable这个集合解决了HashMap的线程安全问题,但是它的解决方法是简单粗暴的,直接在每个get/put方法上用synchronized进行修饰,这样操作的效率是低下的,每当有一个线程正在使用HashTable时,就会把整个散列表都锁住,其它线程若想操作HashTable则都会被阻塞。因此现在基本上都不推荐使用HashTable来解决HashMap的线程安全问题。
下面开始说我们本期的主角:ConcurrentHashMap。
ConcurrentHashMap是JUC包中的一个类,概括来说就是一个能够使元素同步的HashMap。在JDK1.7和JDK1.8中,ConcurrentHashMap的实现方式差别很大,本文会将这两个版本下ConcurrentHashMap的不同实现方式都讲讲。
JDK1.7中的ConcurrentHashMap
上文说到HashTable解决线程安全问题是通过将整个散列表加锁来实现的,这样做效率较低。JDK1.7下ConcurrentHashMap的解决思想将散列表分别多个段,进而使用分段锁,来降低锁的粒度(锁粒度越小事务的并行度越高)。可以参考下图:
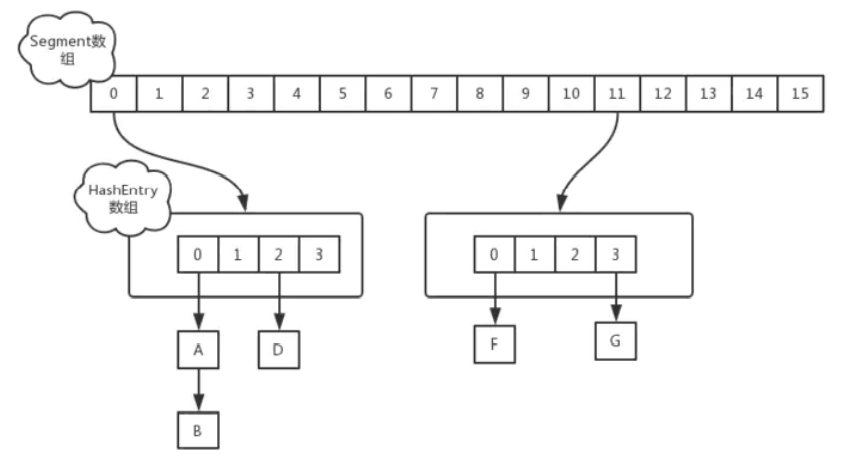
ConcurrentHashMap内部维护一个Segment(段)数组,该Segment数组中的每一个元素是一个HashEntry数组,而HashEntry的结构与HashMap基本一致。
Segment继承了Reentrantlock(关于Reentrantlock,在我的Java并发专栏中的文章已提到了,有兴趣可以看看),意味着每个Segment对象就是一把锁,而每个Segment对象内部都存储着一个HashEntry数组,也就是说该HashEntry数组中的数据同步依赖于该Segment对象这一把锁,这就形成了分段锁。
设ConcurrentHashMap中的Segment数组的长度为n,相较于HashTable,也就是说ConcurrentHashMap将散列表分成了n段,那么性能就提升了n倍。但实际上,ConcurrentHashMap本身还对锁进行了优化,使得性能达到了n倍以上。 是怎么优化的呢?
设现在线程A正在修改一个HashEntry数组中的数据,此时线程B也想尝试在HashEntry数组中进行put操作,但是这时候线程A已经独占了这个锁,所以线程B只能等待或者重试,但与其让线程B干等或不断重试,ConcurrentHashMap改为让线程B在重试的过程当中提前依据put操作中的key和value去完成HashEntry键值对节点的创建。
其实这里存在一个问题,如果线程B在获取到锁时发现锁被占用,它在等待过程中先进行了HashEntry键值对节点的初始化之后,获取到了锁,此时发现了在原本的散列表中已经存在了当前key的键值对节点,那我们这个新创建的HashEntry键值节点对不就浪费了吗?其实这是一种 “预创建” 的思想,与其让线程在原地干等,还不如让它先去把可能需要用到的工作(在这里指创建一个HashEntry键值对节点)做了,以防在后面发现了不存在当前key的键值对时可以直接使用该新建的HashEntry键值对节点。
在JDK1.7中ConcurrentHashMap的扩容方面,Segment数组一旦初始化后就不会再进行扩容,而HashEntry是可以进行扩容的,扩容原理与HashMap一致,且该扩容操作是在put方法中发生的,而put操作已经被使用锁保证了线程安全,所以也保证了扩容的线程安全。
对JDK1.7中ConcurrentHashMap的总结:
- 使用分段锁,Segment继承于Reentrantlock,将每个Segment对象作为锁,每个Segment对象中有一个HashEntry数组
- Segment数组经初始化后不再扩容,HashEntry数组可扩容
- 使用预创建的思想,当线程要进行put操作而获取锁时发现锁被占用,会先进行对节点的创建,以避免线程处于空闲状态
- 扩容是在HashEntry中的put方法中进行,而当前HashEntry已经使用了Segment对象作为锁来确保线程安全,进而确保了扩容的线程安全
JDK1.8中的ConcurrentHashMap
HashMap在JDK1.8版本中引入了红黑树的结构,在JDK1.8版本的ConcurrentHashMap中也引入了红黑树的结构。关于红黑树这种数据结构可以看我之前写的这篇文章《红黑树 图解快速入门》来了解。
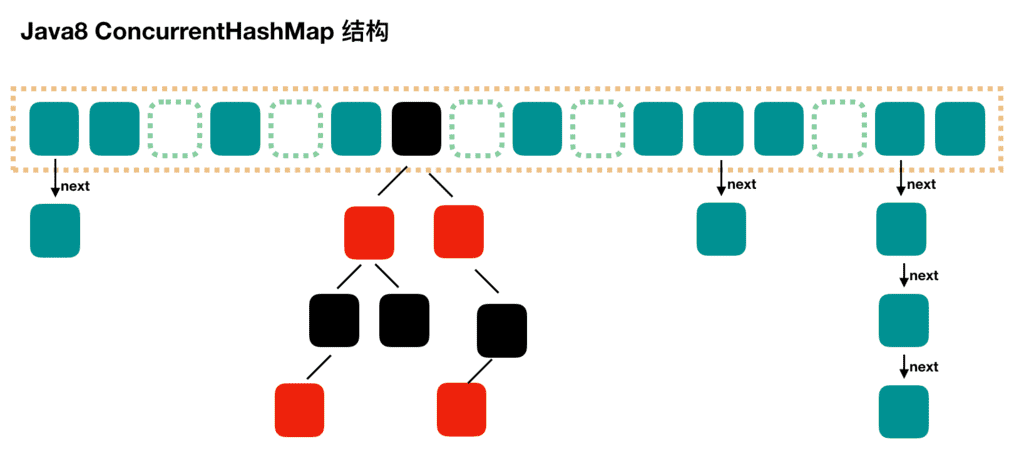
当冲突链表个数增大到 8 个时,就会将链表转化为红黑树结构,以提高查询效率。当红黑树节点个数小于 6 个时,就会将红黑树转化回链表的结构。
在结构上,JDK1.8中的ConcurrentHashMap由JDK1.7中的Segment数组 + HashEntry数组 + 链表 进化为 Node数组 + 链表 / 红黑树 的结构。其中Node数组中的每一个Node对象也即存储了键值对的信息。
在解决线程安全方面,简单来说,相较于JDK1.7,JDK1.8不再使用分段加锁的操作,而是直接在散列表的每一个头节点上进行加锁,进一步缩小了锁的粒度。同时在JDK1.7中是使用继承了Reentrantlock的Segment对象作为锁来进行加锁操作,而JDK1.8中是直接在节点上使用CAS或者Synchronized关键字修饰来进行并发控制。(关于CAS和Synchronized关键字在我的Java并发专栏之前的文章中已经讲述过了,有兴趣可以看看)
ConcurrentHashMap中有一个比较关键的属性sizeCtl,这个属性的不同值代表ConcurrentHashMap目前处于不同的状态:
- -1 说明正在初始化
- -N 说明有N-1个线程正在进行扩容
- 表示 table 初始化大小,如果 table 没有初始化
- 表示 table 容量,如果 table 已经初始化。
在ConcurrentHashMap初始化操作中,使用CAS进行初始化,以防同时与其它线程对当前ConcurrentHashMap进行了初始化。
下面讲JDK1.8中ConcurrentHashMap的put操作与get操作。
在此之前,需要注意:ConcurrentHashMap中键值对的key和value不能为null,因为如果key和value可以为null,会出现二义性问题。
当通过一个key获取到的value为null时,我们没法知道是不存在这个键值对还是存在value为null的键值对,这就产生了二义性问题。
在HashMap中,当获取到的value为null,我们可以通过containsKey方法来判断是否存在这个键值对。
但是在ConcurrentHashMap中,当获取到的value为null,我们再去调用containsKey方法,但这个过程没法确保是否刚好有别的线程把查询的对象加入到集合中或者把它删除掉,所以为了避免二义性问题,ConcurrentHashMap不允许key和value为null。
在put操作中的流程:
- 判断key和value是否为null,如果是则报错。
- 判断当前ConcurrentHashMap是否需要进行初始化,如果当前ConcurrentHashMap为空,则使用CAS进行初始化
- 依据当前key定位出Node的位置,如果当前位置为空,则使用CAS在当前位置尝试加入Node,失败则进行自旋保证成功
- 如果当前位置不为空,判断当前位置是否有其它线程正在进行扩容,如果有则当前线程进入协助扩容阶段
- 如果当前位置不为空且无其它线程在进行扩容,则使用synchronized关键字对当前位置的头节点加锁后,进行数据修改
- 如果当前位置的节点是链表结构,则遍历链表找是否有key相同的元素,有则修改value,无则在最后插入新链表节点,然后判断当前链表中的节点个数是否超过了树化阈值(这个阈值是TREEIFY_THRESHOLD,是相对链表节点个数而言,值为8),如果超过,则考虑将链表转化为红黑树
- 如果当前链表中的节点个数超过了树化阈值,会调动treeifyBin方法,然后看当前散列表数组的大小是否小于最小树化阈值(这个阈值是MIN_TREEIFY_CAPACITY,是相对散列表个数而言,值为64),如果小于它,则不进行改造为红黑树,而是将散列表数组容量扩大为两倍,然后重新调节节点位置
- 如果当前位置的节点是红黑树结构,则按照红黑树的插入规则进行新节点的插入
- 新节点插入之后节点数量 + 1,判断ConcurrentHashMap是否需要进行扩容
在get操作中的流程:
- 根据 hash 值计算位置。
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value.
- 如果头节点 hash 值小于 0 ,说明此处正在扩容或者此处是红黑树,查找之。
- 如果是链表,遍历查找之。
什么时候会发生扩容?
- 新增节点后链表节点数达到了8个但是散列表数组长度小于64,这时不会选择将链表转化为红黑树而是将散列表数组大小变为2倍,调用tryPresize方法。
- 新增节点后当前数组中的总元素个数达到了扩容阈值,则进行扩容,调用transfer方法。
- 当调用了putAll方法时,发现当前容量不足以存放所有的元素,则进行扩容。
JDK1.8中ConcurrentHashMap扩容机制比较复杂,内容较多,大家可以参考这篇文章《ConcurrentHashMap1.8 - 扩容详解》,里面有图解扩容。
对JDK1.8中ConcurrentHashMap的总结:
- 引入了红黑树的数据结构,且不再使用分段锁,改用Node数组
- 直接在散列表的每个头节点上使用CAS进行创建头节点或者使用synchronized关键字加锁
- 扩容时可能会有多个线程参与扩容
- key和value不能为null,目的是在于避免二义性问题
参考:
- B站up主寒食君的视频:视频链接
- B站up主图灵官方诸葛的视频:视频链接
- JavaGuide中的一篇文章
- 参考文章1、参考文章2(这2篇博客文章讲得特别细,写得很用心,有时间可以看看)

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









