






笔者参加了今年字节跳动举办的后端青训营,在听了其中一节关于HTTP框架入门介绍的课后,作下本篇笔记。
本篇笔记,主要讲述了更多在大学课堂上没有了解到的HTTP协议的部分内容以及HTTP框架的设计与实现。
前言
HTTP 协议是当今使用最为广泛的协议之一,HTTP 是前(客户)端与服务端通信的基础协议。如下图就是一个前后端分离的一个流程图,前后端之间通过 HTTP 请求进行通信。
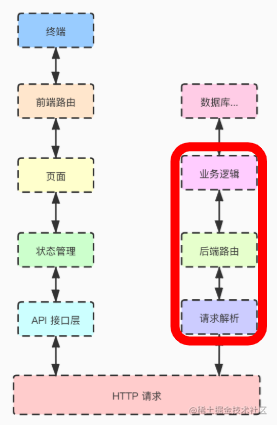
HTTP 框架负责的就是对 HTTP 请求的解析、根据对应的路由选择对应的后端逻辑了,也就是图上标出来的这些。HTTP 在企业实际业务场景中使用广泛。
第一个大规模使用的 HTTP 协议的版本是0.9,从1991年开始的大规模使用。现在到今年的话已经 30 多年过去了。那这么这样一款 30 岁的一个协议,它依然能够这么生机盎然,持续地去迭代,甚至还有一些更新的版本。
再谈HTTP协议
HTTP:超文本传输协议(Hypertext Transfer Protocol)
协议里面有什么?
请求报文:
- 请求行
- 方法名(GET、POST等)
- URL
- 协议版本
- 请求头
- 协议约定(Content-length等)
- 业务相关(自定义的元数据)
- 请求体
响应报文:
- 状态行
- 协议版本
- 状态码
- 状态码描述
- 响应头
- 协议约定
- 业务相关
- 响应体
常见的方法名:GET、POST、PUT、DELETE、HEAD、CONNECT、OPTIONS、TRACE、PATCH
GET是HTTP 0.9中唯一的一个方法,之后在HTTP 1.0中增加了HEADER和POST,紧接着在HTTP 1.1中又陆续了增加了5个方法。
PATCH和PUT的区别:
- PATCH是部分更新,PUT是完整更新
- PATCH是幂等的,PUT不是幂等的
请求流程
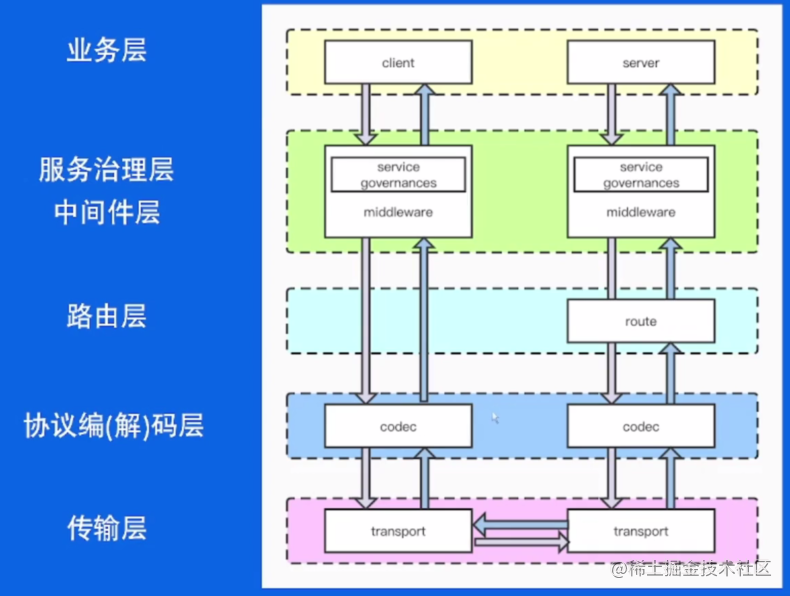
在那一次完整的请求发生了什么?
首先在业务层,业务方的使用框架提供的 API 完成业务逻辑。
服务治理层,是依托于中间件层的。完成业务逻辑之后,会进入到一些服务服务治理的逻辑。也就是大家经常说的比如熔断、限流等等。服务治理层对每个请求可以有一些先处理逻辑和后处理逻辑,和请求级别绑定。
对于 client 来说,之后就可以进入一个协议编(解)码层。协议的编解码层是用于将报文编译成能识别的内容,然后最后通过传输层进行传输。
HTTP的处理过程中包含一个路由层,它是根据 URI 选择对应的执行的 handler。
HTTP的不足与期望
首先对于 http 1 来说:
- 因为 http 1 是基于 TCP 的。基于 TCP 的协议都会有一个队头阻塞的问题,后续的分片必须要等待前面的分片的到来才能继续发送后面的数据,否则的话会一直等待。
- 第二个是 http 1 的传输效率很低,就像如果只想传简单的讯息,但是这里面同时发送的无用的信息其实非常多,存在很多重复的信息如头部数据等。
- 除此之外,http 1 也不支持多路复用,这个请求没结束之前是不能再发送其他请求的。
- 最后是 http 1 是明文传输,这不安全。
HTTP 2 解决了 HTTP 1 的一部分问题,但没有完全解决。HTTP 2 引入的改进比如说可以进行多路复用、头部压缩,以及使用二进制协议解析起来更加高效。 但是由于 http 2 还是基于 tcp 的,所以并没有解决队头阻塞的问题,而且握手的开销也没有优化。于是出现了基于UDP协议的 QUIC ,解决了上面说的两个问题。

HTTP框架的设计与实现
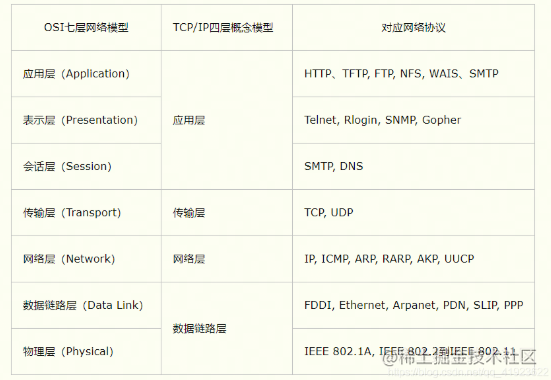
计算机网络中的协议使用了分层设计。分层设计可以简化系统设计,让不同的人专注做某一层次的事情。有了分层的设计,大家只需要使用下一层提供给上层的接口,专注特定层的开发就可以了,至于这个接口底层是如何实现是不用关心的。
分层架构可以让我们更容易做横向扩展。如果系统没有分层,那相关的扩展就会变得不太容易,比如某些Go的 HTTP 框架,到现在也没有支持 http 2,那肯定不是它不想支持。
最后,分层之后可以做到很高的复用。比如,我们在设计模块A的时候,发现这一模块具有一定的通用性,那么我们可以把它抽取独立出来,在设计系统B的时候使用起来,减少工作量。
总结来说,分层设计的好处在于三点:
- 专注性
- 扩展性
- 复用性
既然分层设计有这些的好处,HTTP 框架的设计也应该采用分层设计。在进行分层设计时,我们需要考虑一些点,比如高内聚低耦合,复用性、扩展性等等。

HTTP 架构从整体上来看,从上往下总共分为了五层,层与层之前使用接口解耦。
从上开始的话就是应用层,这一层是跟用户直接打交道的一层,这一层会对请求进行一个抽象,包括像 request response context 等等。应用层也会提供一些丰富的易用的API。
然后下一层就是中间件层,可以对请求有一些预处理和后处理的逻辑,像可以打一些 accesslog,打一些耗时的点。其他中间件比如 Reacovery 中间件用于捕获 Panic。
之后是路由层,路由层有一个原生的路由实现来提供类似于跟注册、路由寻址的一些操作。这一部分的内容在下一部分会具体进行详细地展开。
然后再往下的话就是协议层。现在 http 1.1 已经不能够满足我们所有的需求了,我们需要支持 HTTP 2、Quic 等等,甚至是在 TLS 握手之后的 ALPN 协商升级操作,那这些都需要能够很方便的支持。
最后一层的话就是网络层,不同的网络库使用的场景并不相同,那也需要一个灵活替换网络库的能力。
右边的 Common 层主要放一些公共逻辑,这一部分可能每一层都会使用。
这里记一下网络层设计的部分内容,因为涉及到了BIO与NIO。

设想一个场景,比如说打客服电话,客服跟我说问我身份证号是多少,那这时候我忘了身份证号多少,我就必须说你等一下,我去找一下这个身份证,但我又没找着,那这个客服是不是占线,那占线的话他就什么都做不了,然后并在这里占住了,他等不下去了,就等到了超时。
这种编程模型在互联网界就叫 block io,简称 bio。可以看左边这段代码,这段代码是go一个经典的connection处理,我们在一个 go function 里面维护一个 listener, listener 每次 accept 获取一个连接之后,会开一个 goroutine 去单独处理它。这 goroutine 行为应该是先去读取数据,读取完之后处理业务逻辑,然后再把这个response写回去。假如说你在读数据的时候读到了一半,它就读在这里了,它啥也干不了。
那有没有解决这种办法的方式也比较简单,我们在中间引入一种通知的机制,就是当他数据有一半的时候,我让客服小姐姐也去干别的事情。那当它后续把整个包都已经发完的时候,我们再去通知他去处理,这样的话就不会阻塞。这在互联网界就是 non block io 的一种编程模式,简称 nio ,是非阻塞的。我们可以看一下右边这段代码,在第一个go function里面还是维护这个连接, 但是每次我们拿到这个连接之后,我们把它加到一个监听器里面,然后我们在另外一个部分里面去轮询这个 monitor 就是监听器,搜索可读的连接数。因为这里 monitor 已经知道有数据了,但这个服务方式去执行的时候可能是 read ,这时候就能拿到完整的数据并处理,然后再返回,这个时候整个流程是没有阻塞的。

在用户态来看, go net 是由用户管理的 buffer,这两个接口都是传入 buffer,进行读或者写,那它本身是不管理buffer的。
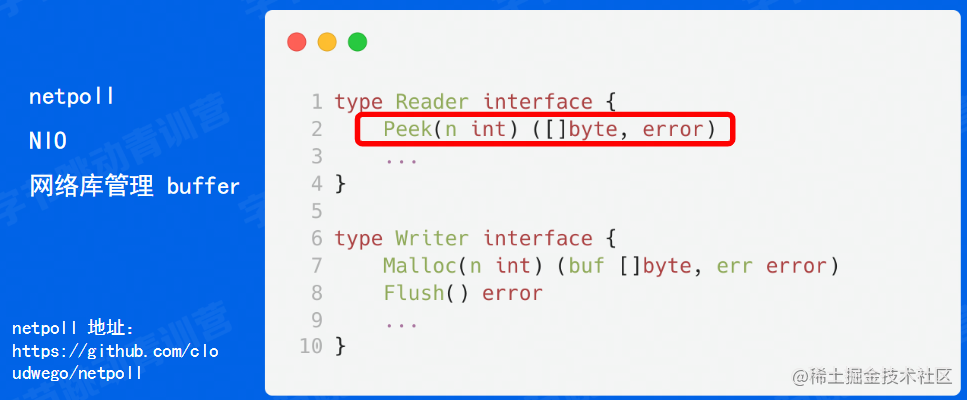
netpoll是字节跳动自研的网络库,使用了NIO,目前已开源,链接:https://github.com/cloudwego/netpoll
性能修炼之道
这部分以后有空再补充吧
企业实践
这部分以后有空再补充吧

















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









