






# 所用技术
前端: vue3+elementui
后端: python3+django3+simpleui
爬虫: python3+scrapy
数据库: mysql
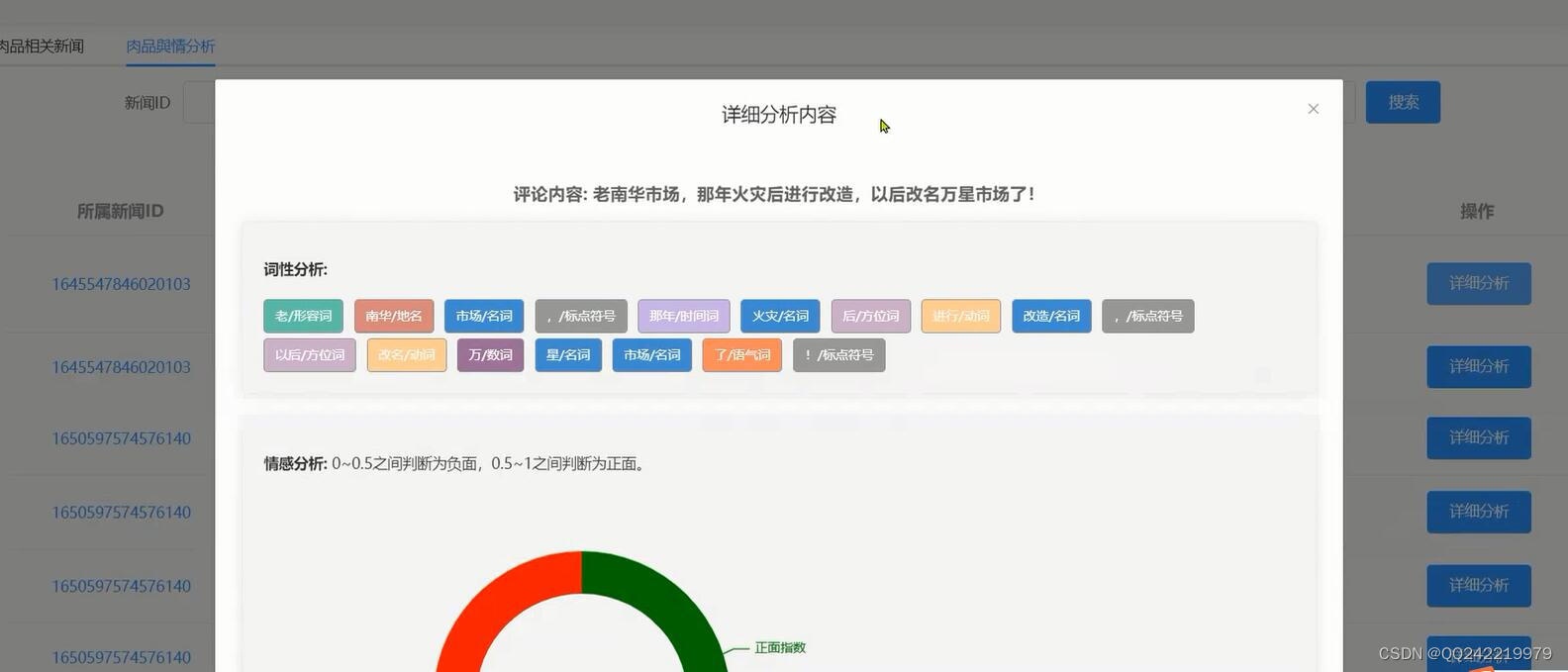
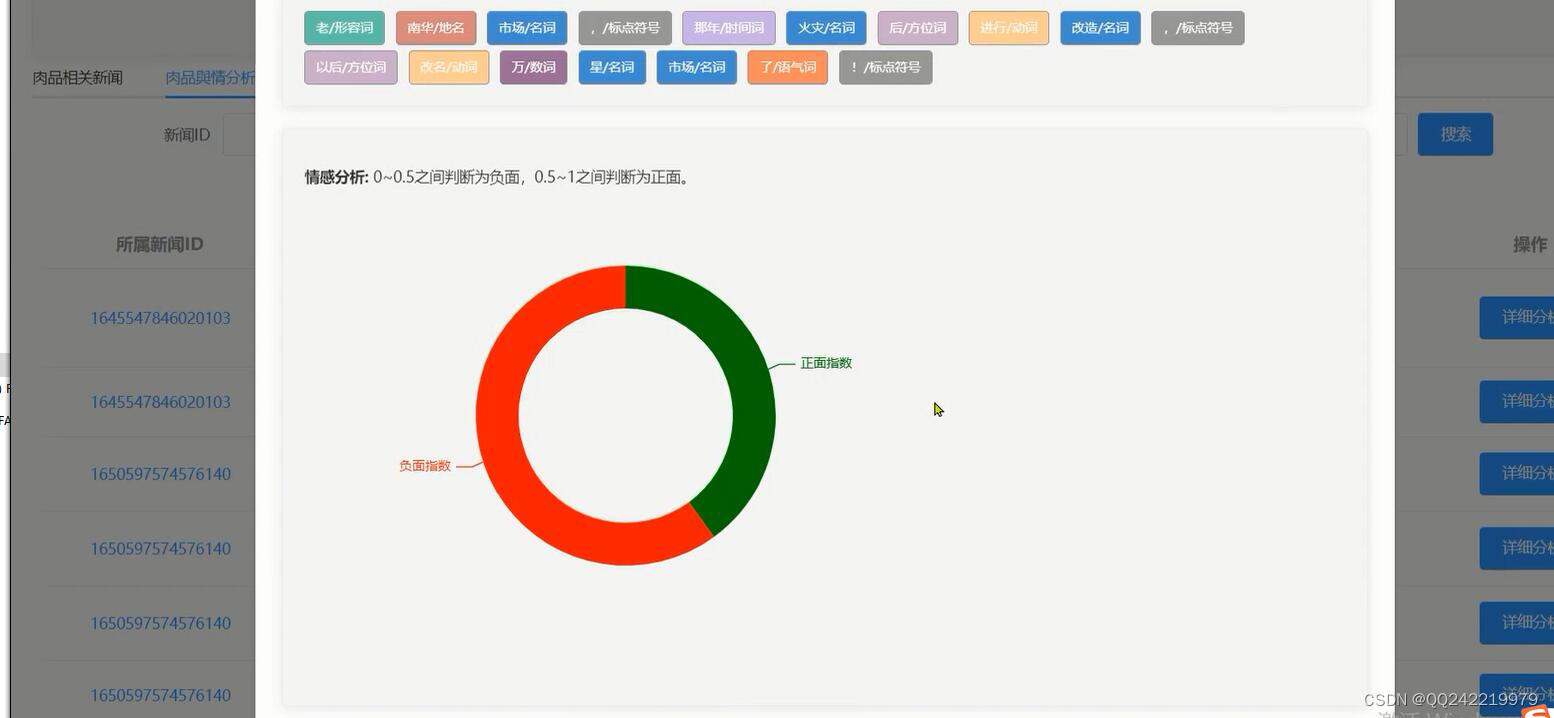
情感分析: 用微博、新闻、餐饮等行业语料进行标注和机器学习,将文本的情感分为负面和非负面两类
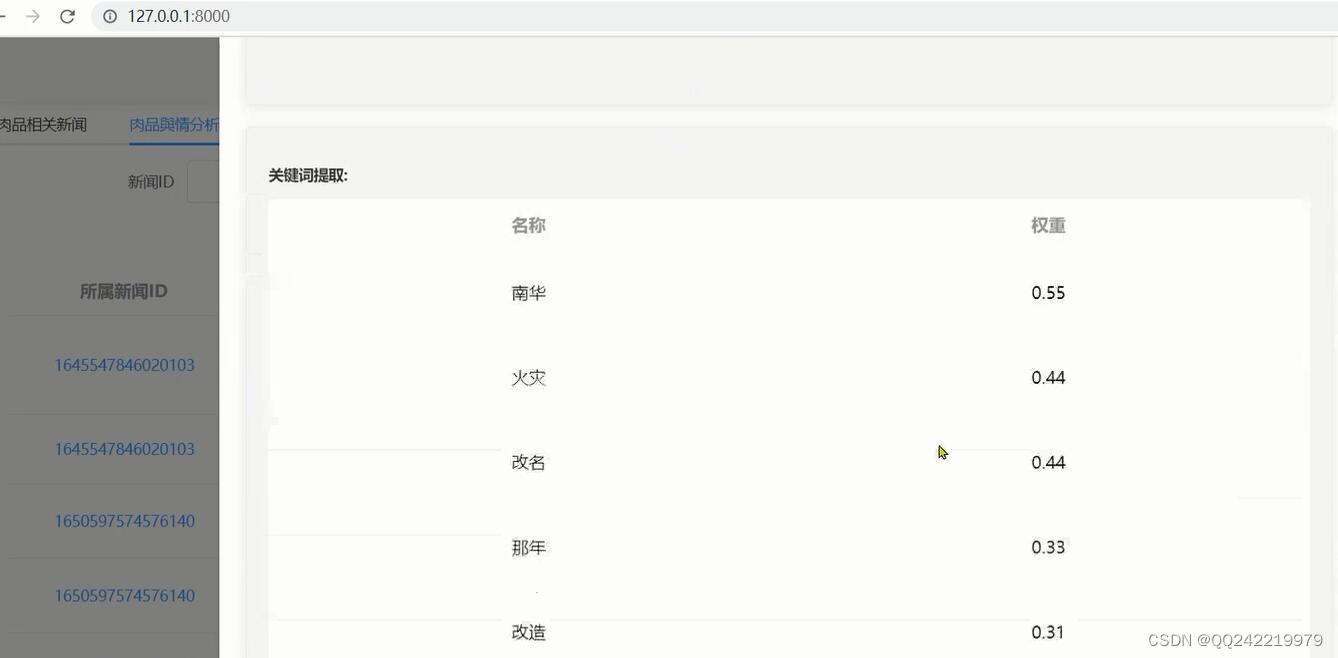
关键词提取: 将文本自动进行关键词分析,给出每个词语相应的权重
分词与词性标注: 词性标注是建立在分词基础上的另一个自然语言处理的基础步骤。采用将分词和词性标注联合枚举的方法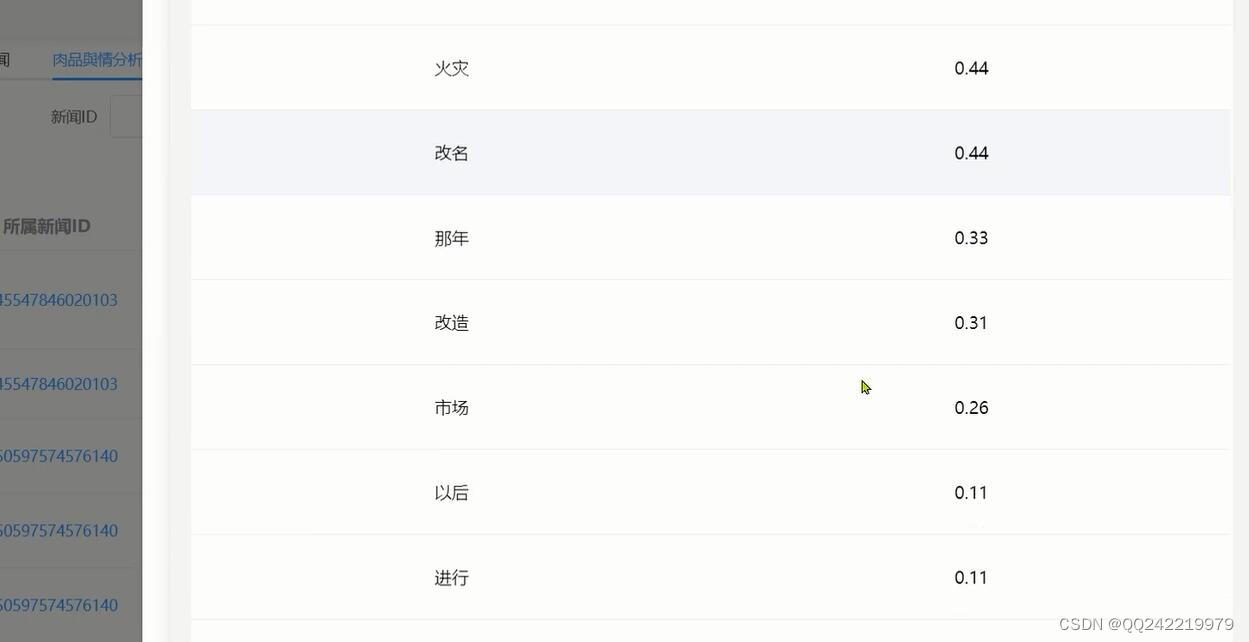
# 模块
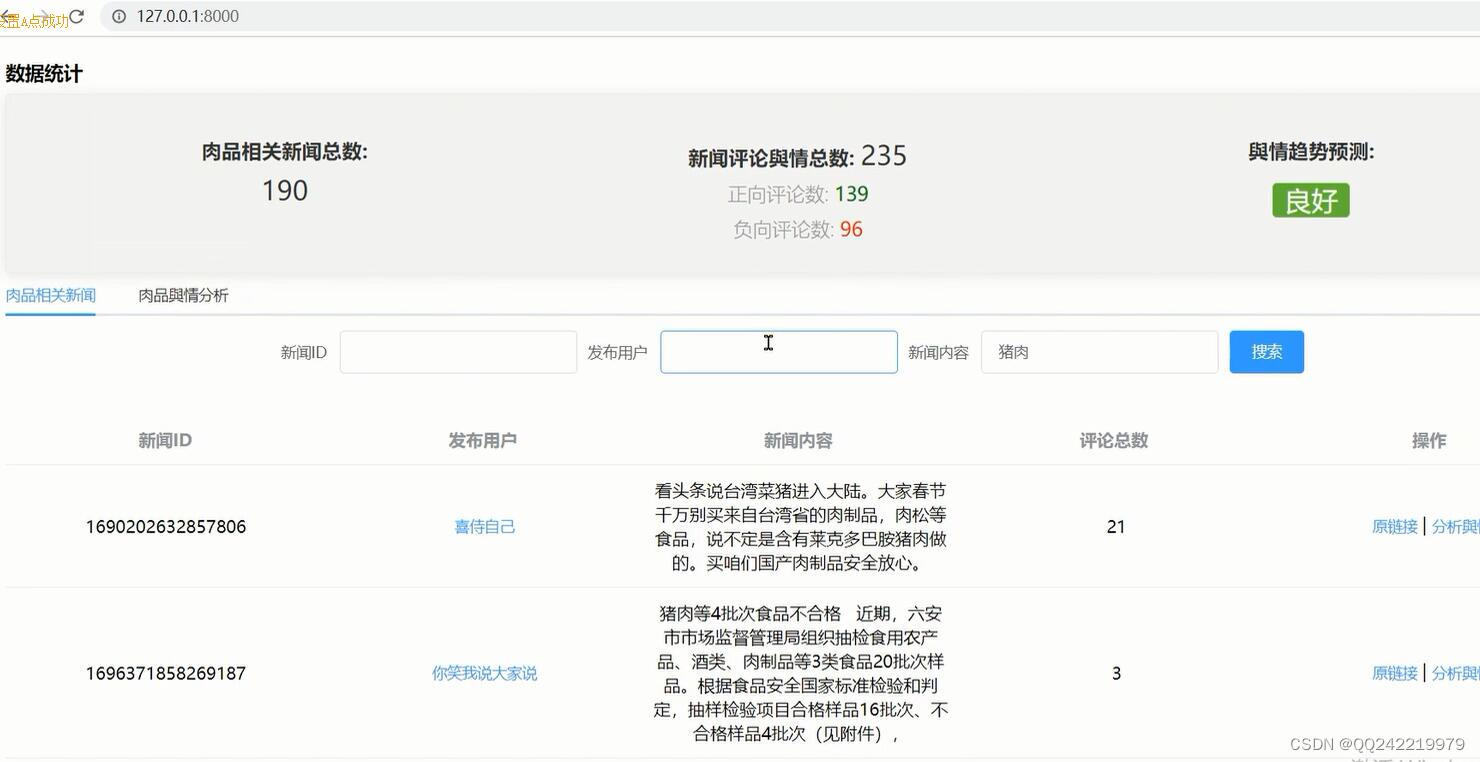
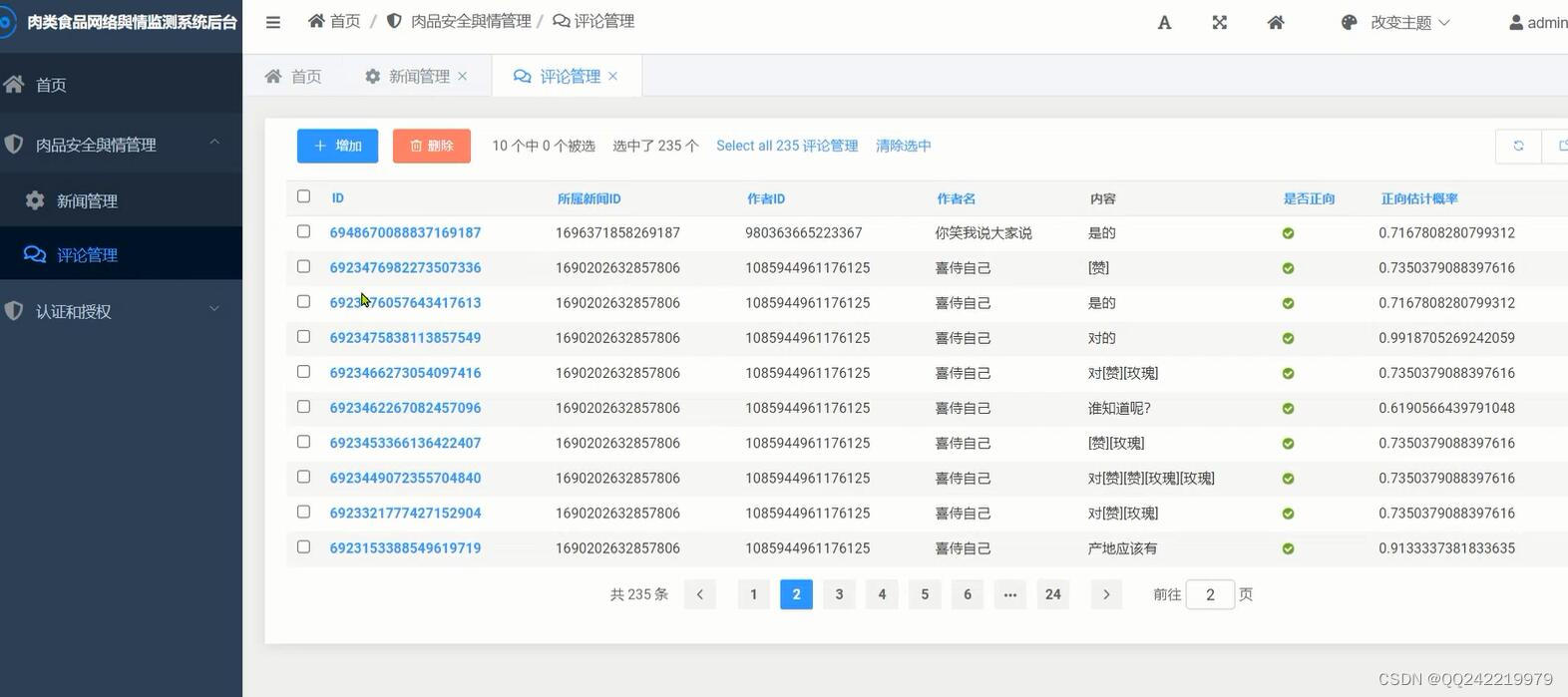
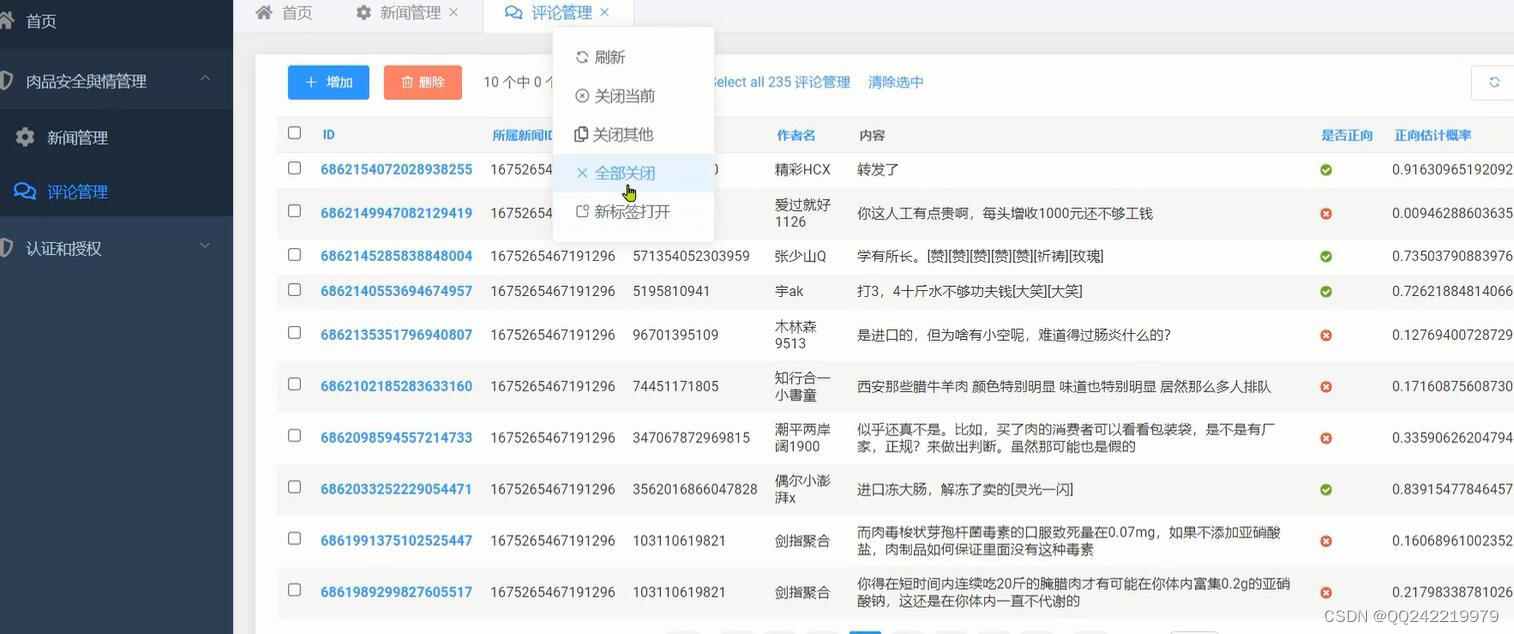
1. 肉品新闻/评论采集: 通过爬虫爬取头条相关肉品安全新闻,并同时抓取用户评论,以便进行與情分析
2. 前台统计模块,全局统计新闻/(正负向)评论条数,并实时分析告知與情趋势
3. 前台肉品新闻数据展示,支持筛选/查看/查看评论等功能
4. 前台评论数据展示,支持筛选/查看/具体分析等功能
5. 前台登录注册模块
6. 后台模块
- 管理员登录
- 肉品新闻增删改查管理
- 评论增删改查管理
- 全局用户/权限管理
目录结构说明
├── README.md
├── auth 用户登陆注册相关接口目录
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ ├── models.py
│ ├── tests.py
│ ├── urls.py 用户登陆注册相关路由
│ └── views.py 用户登陆注册相关接口
├── crawl_comments.py 抓取肉品安全评论爬虫文件
├── db.sqlite3 数据库文件
├── ff3d9d515ea91388a80023ea37586927.jpg
├── index 渲染前端文件的相关接口目录
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ ├── models.py
│ ├── templates
│ ├── tests.py
│ ├── urls.py 渲染前端文件的相关路由
│ ├── utils.py 工具类文件
│ └── views.py 渲染前端文件的相关接口
├── manage.py 后端启动入口文件
├── meat_product_analysis 后端总配置目录
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py 总配置文件
│ ├── urls.py 总路由配置文件
│ └── wsgi.py
├── meat_product_spider 爬虫scrapy框架目录
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders 爬虫文件目录
├── requirements.txt 依赖库文件
├── scrapy.cfg
├── test.html
├── toutiao 头条新闻相关肉品安全接口目录
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ ├── models.py 数据库模型文件
│ ├── tests.py
│ ├── urls.py 头条新闻相关肉品安全路由
│ └── views.py 头条新闻相关肉品安全接口
├── 答疑.txt
└── 使用方法.txt
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









