






本篇笔记内容主要是关于爬取小红书关键词笔记下所有评论并做词云分析(升级版),为了帮助大学生们实现论文数据采集而做,可以采集上万条数据如需源代码私信即可获取(不支持白嫖哦)
爬虫部分(部分代码):
def sava_data(comment):
try:
ip_location = comment['ip_location']
except:
ip_location = '未知'
data_dict = {
"用户ID": comment['user_info']['user_id'].strip(),
"用户名": comment['user_info']['nickname'].strip(),
"头像链接": comment['user_info']['image'].strip(),
"评论时间": get_time(comment['create_time']),
"IP属地": ip_location,
"点赞数量": comment['like_count'],
"评论内容": comment['content'].strip().replace('\n', '')
}
# 评论数量+1
global comment_count
comment_count += 1
print(f"当前评论数: {comment_count}\n",
f"用户ID:{data_dict['用户ID']}\n",
f"用户名:{data_dict['用户名']}\n",
f"头像链接:{data_dict['头像链接']}\n",
f"评论时间:{data_dict['评论时间']}\n",
f"IP属地:{data_dict['IP属地']}\n",
f"点赞数量:{data_dict['点赞数量']}\n",
f"评论内容:{data_dict['评论内容']}\n"
)
writer.writerow(data_dict)
# 爬取根评论
def get_comments(note_id):
cursor = ''
page = 0
while True:
url = f'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={note_id}&cursor={cursor}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP'
# 爬一次就睡1秒
time.sleep(1)
json_data = spider(url)
for comment in json_data['data']['comments']:
sava_data(comment)
if not json_data['data']['has_more']:
break
# 下一页评论的地址
cursor = json_data['data']['cursor']
# 每爬完一页,页数加1
page = page + 1
print('================爬取Page{}完毕================'.format(page))
爬虫效果图:

数据分析部分(部分代码):
# 对评论进行分词,去除一些停用词
segmented_comments = []
for comment in clean_comments:
if len(comment) == 0:
continue
seg_list = ' '.join(jieba.lcut(comment, cut_all=True))
segmented_comments.append(seg_list)
print(segmented_comments)
# 分析每条评论的情感倾向得分
sentiment_scores = [analyze_sentiment(comment) for comment in segmented_comments]
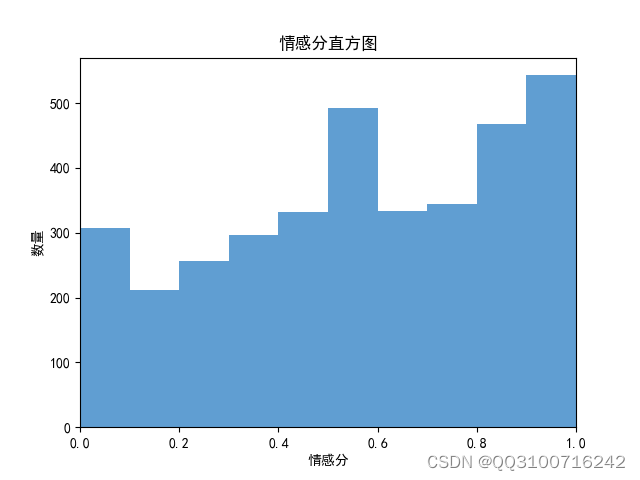
# 绘制情感分直方图
bins = np.arange(0, 1.1, 0.1)
plt.hist(sentiment_scores, bins, color='#4F94CD', alpha=0.9)
plt.xlim(0, 1)
plt.xlabel('情感分')
plt.ylabel('数量')
plt.title('情感分直方图')
plt.show()
# 根据情感倾向分数将评论分类为积极和消极
positive_comments = [comment for comment, score in zip(segmented_comments, sentiment_scores) if score > 0.5]
negative_comments = [comment for comment, score in zip(segmented_comments, sentiment_scores) if score <= 0.5]
# 积极消极评论占比
pie_labels = ['积极评论', '消极评论']
plt.pie([len(positive_comments), len(negative_comments)],
labels=pie_labels, autopct='%1.2f%%', shadow=True)
plt.title("积极和消极评论占比")
plt.show()
# 绘制积极评论词云图
positive_text = ' '.join(positive_comments)
generate_wordcloud(positive_text)
# 绘制消极评论词云图
negative_text = ' '.join(negative_comments)
generate_wordcloud(negative_text)
数据分析效果图:


















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









