







1 绪论
c语言在线编辑工具:菜鸟工具
2 线性表
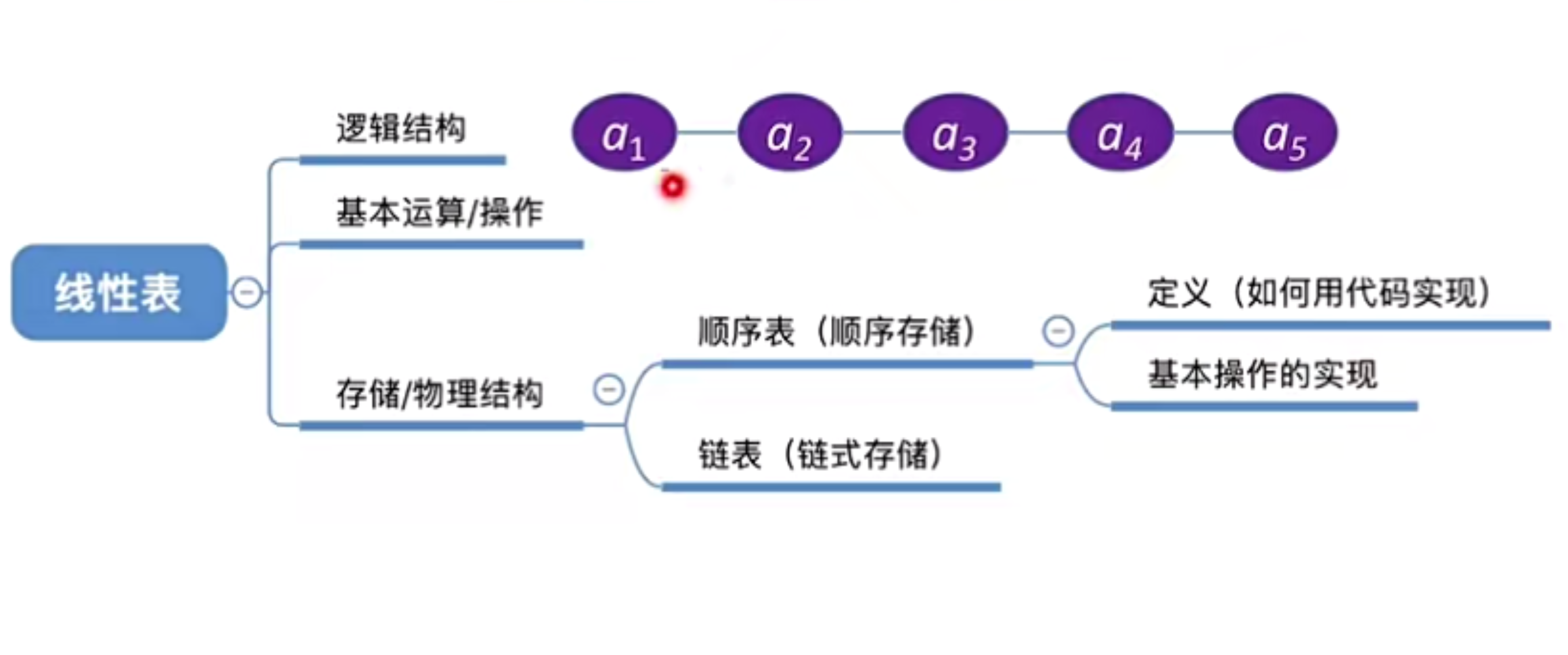
注: 数据结构三要素 – 逻辑结构、数据的运算、存储结构(物理结构)
2.1 定义(逻辑结构)
线性表(Linear List) 是具有相同数据类型的n(n>=0)个数据元素的有限序列,其中n为表长,当n=0时线性表是一个空表。若用L命名线性表,则其一般表示为
L=(a1,a2,… ,ai,ai+1,… ,an)
几个概念:
ai是线性表中的“第i个”元素线性表中的位序
a1是表头元素;an是表尾元素。
除第一个元素外,每个元素有且仅有一个直接前驱;除最后一个元素外,每个元素有且仅有一个直接后继

2.2 基本操作(运算)
Tips:
① 对数据元素的操作(记忆思路) – 创毁、增删,改查
② C语言函数的定义-- <返回值类型>函数名(<参数1类型>参数1,<参数2类型>参数2,…
③ 实际开发中,可根据实际需求定义其他的基本操作
④ 函数名和参数的形式、命名都可改变(Reference:严蔚敏版《数据结构》) 命名要有可读性
⑤ 什么时候要传入参数的引用"&" --对参数的修改结果需要 “带回来”
//初始化表。构造一个空的线性表L,分配内存空间。
InitList(&L):
//销毁操作。销毁线性表,并释放线性表L所占用的内存空间。
DestroyList(&L)
//InitList() DestroyList() 实现了线性表从无到有
//插入操作。在表L中的第i个位置上插入指定元素e。
Listlnsert(&Li,e)
//删除操作。删除表L中第i个位置的元素,并用e返回删除元素的值
ListDelete(&L,i,&e)
//按值查找操作。在表L中查找具有给定关键字值的元素。
LocateElem(L,e)
//按位査找操作。获取表L中第i个位置的元素的值。
GetElem(L,i)
其他常用操作:
//求表长。返回线性表L的长度,即L中数据元素的个数
Length(L)
//输出操作。按前后顺序输出线性表L的所有元素值。
PrintList(L)
//判空操作。若L为空表,则返回true,否则返回false
Empty(L)
2.3 存储/物理结构
2.3.1 顺序表(顺序存储)
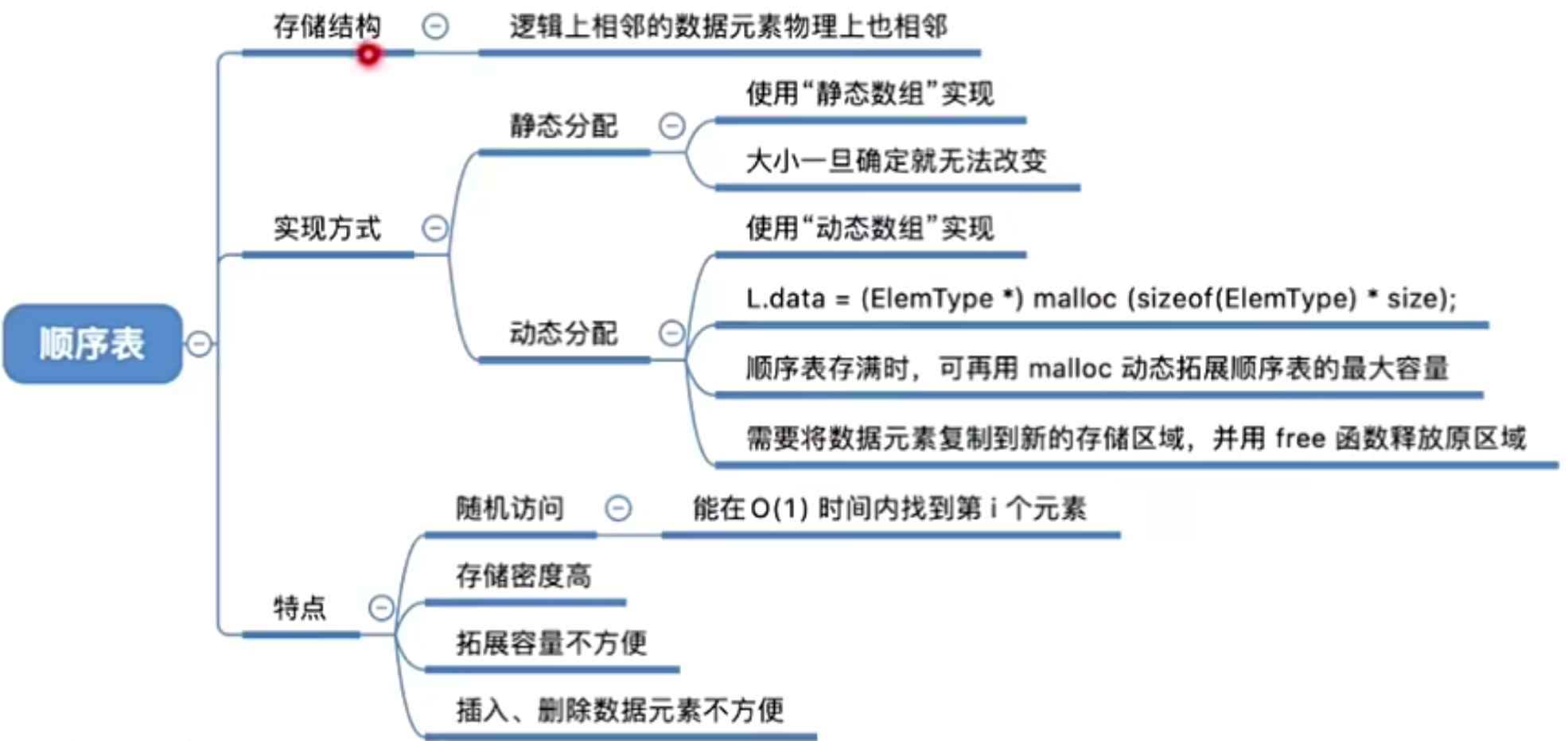
2.3.1.1 定义
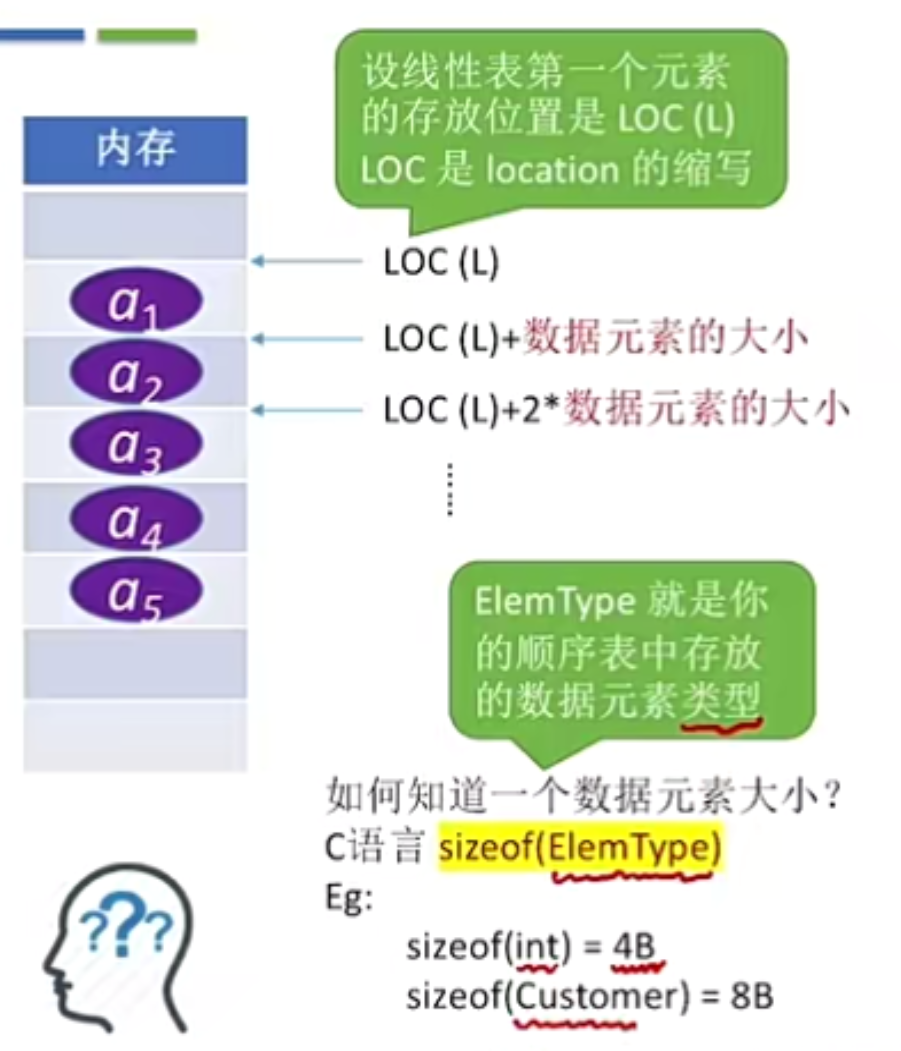
顺序表–用顺序存储的方式实现线性表顺序存储。把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的邻接关系来体现。

2.3.1.2 顺序表的实现
2.3.1.2.1 静态分配
//大小一但 声明就不能改变
#define MaxSize 10 //定义最大长度
typedef struct{
ElemType data[MaxSize]; //用静态的‘数组’存放数据元素
int length; //顺序表的当前长度
}SeqList; //顺序表的类型定义(静态分配方式)
实例:
#include <stdio.h>
#define MaxSize 10 //定义最大长度
typedef struct{
int data[MaxSize]; //用静态的‘数组’存放数据元素
int length; //顺序表的当前长度
}SeqList; //顺序表的类型定义(静态分配方式)
//基本操作- 初始化一个顺序表
void InitList(SeqList &L){
for(int i=0;i<MaxSize;i++){
L.data[i]=0; //将所有数据元素设置为默认初始值
}
L.length=0; //顺序表初始长度为0
}
int main(){
SeqList L; //声明一个顺序表
InitList(L) //初始化顺序表
//。。。。。后续操作
return 0;
}
2.3.1.2.2 动态分配
#define InitSize 10 //顺序表的初始长度
typedef struct{
ElemType *data; //指示动态分配数组的指针
int MaxSize; //顺序表的最大容量
int length; //顺序表的当前长度
}SeqList; // 顺序表的类型定义(动态分配方式)
key:动态申请和释放内存空间
C – malloc、free函数
//(ElemType *):malloc函数返回一个指针,需要强制类型转换为你定义的数据元素类型指针
//sizeof(ElemType) * InitSize :malloc函数的参数,指明要分配多大的连续内存空间
L.data = (ElemType *) malloc(sizeof(ElemType) * InitSize);
C++ – new、delete 关键字
实例:
#define InitSize 10 //顺序表的初始长度
typedef struct{
int *data; //指示动态分配数组的指针
int MaxSize; //顺序表的最大容量
int length; //顺序表的当前长度
}SeqList; // 顺序表的类型定义(动态分配方式)
//基本操作- 初始化一个顺序表
void InitList(SeqList &L){
//用malloc 函数申请一片连续的存储空间
L.data=(int*)malloc(InitSize*sizeof(int));
L.length=0;
L.MaxSize=InitSize;
}
//动态增加数组的长度--数组扩容只能通过新建一个扩容长度的数组拷贝元数据的方式。
void IncreaseSize(SeqList &L,int len){
int *p=L.data;
L.data=(int*)malloc((L.MaxSize+len)*sizeof(int));
for(int i=0;i<L.length;i++){
L.data[i]=p[i]; //将数据复制到新区域
}
L.MaxSize=L.MaxSize+len; //顺序表最大长度增加len
free(p); //释放原来的内存空间
}
int main(){
SeqList L; //声明一个顺序表
InitList(L) //初始化顺序表
//。。。。。后续操作
IncreaseSize(L,5) //增加5个长度
return 0;
}
2.3.1.3 顺序表的特点
① 随机访问,既可以在O(1)时间内找到第i个元素。
ElemType = data[i-1]
② 存储密度高,每个节点只存储数据元素
③扩展容量不方便(即便采用动态分配的方式实现,扩展长度的时间复杂度也比较高)
④插入、删除操作不方便,需要移动大量元素。
2.3.1.4 基本操作的实现
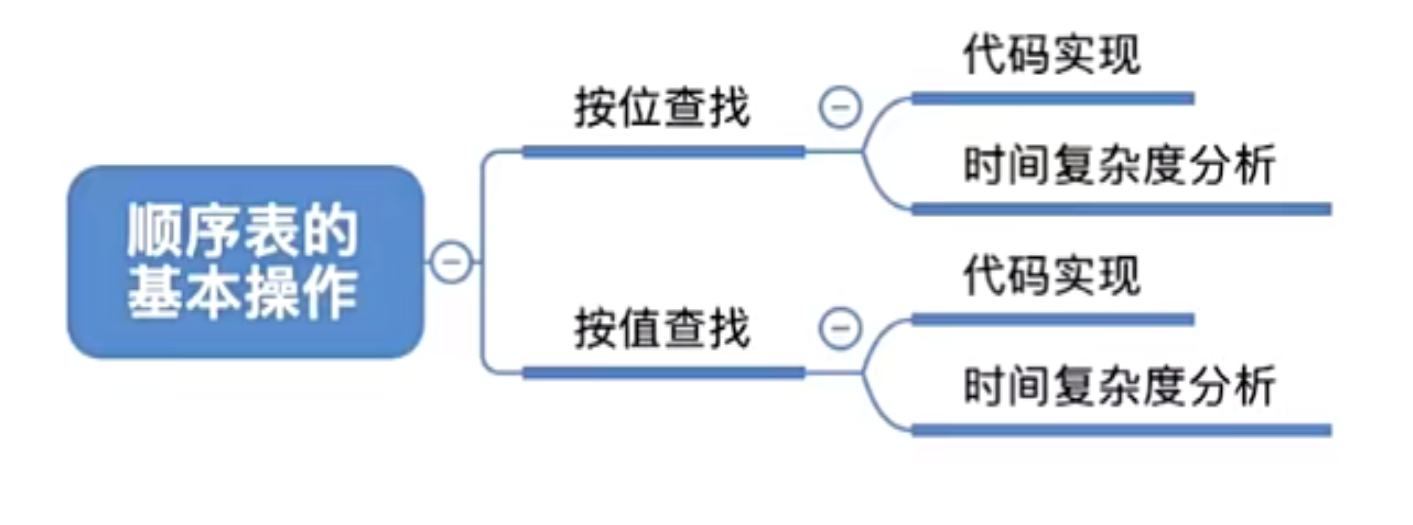
2.3.1.4.1 顺序表的基本操作
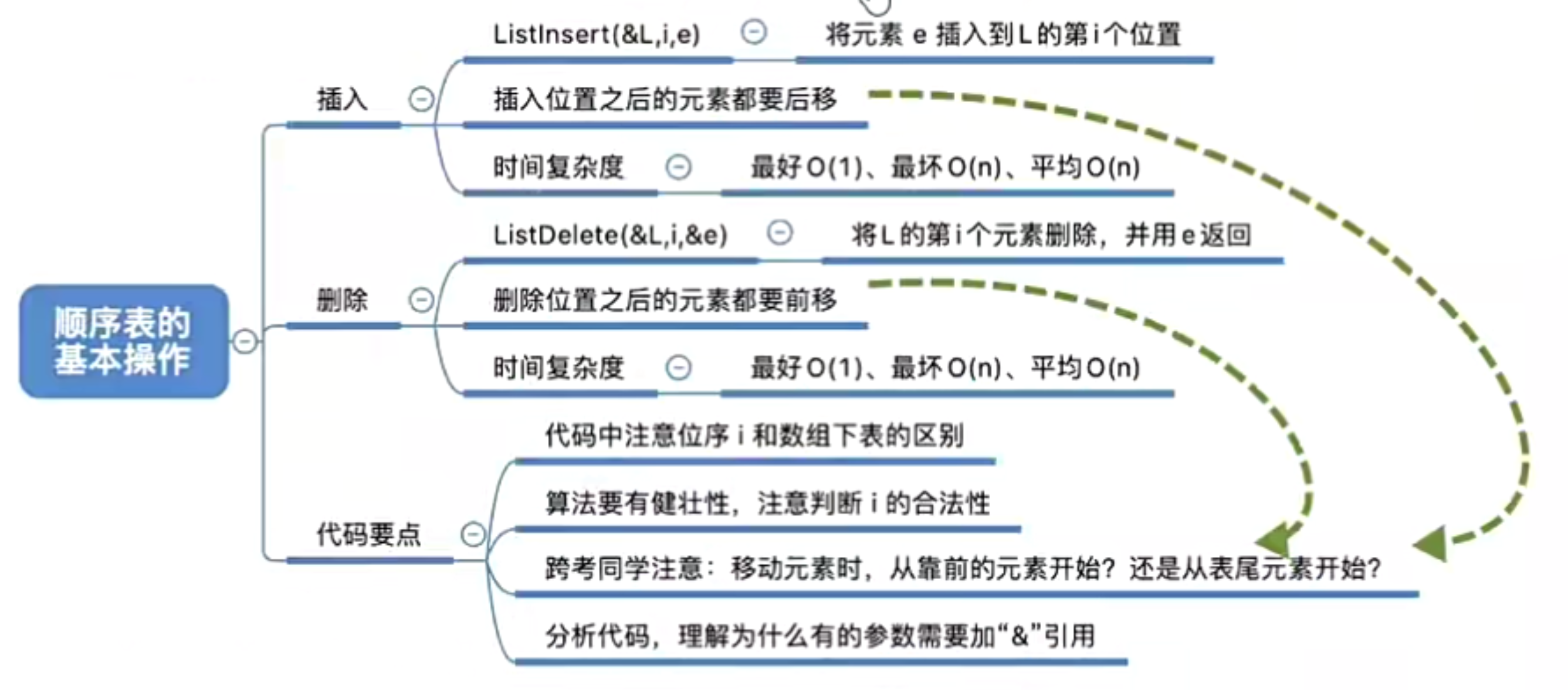
2.3.1.4.1.1 顺序表-插入
逻辑结构:


ListInsert(&L,i,e) : 插入操作。在表L的第i个位置上插入指定元素e。
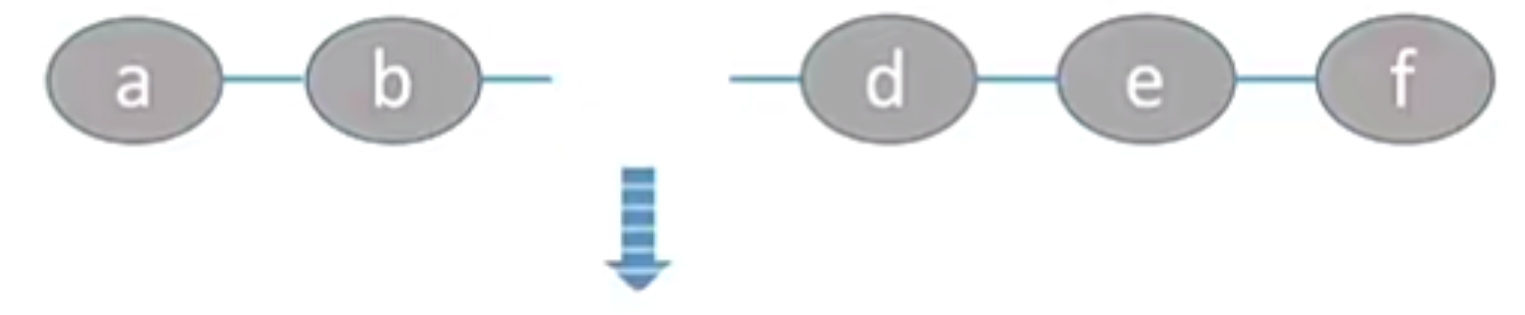
插入C元素时,d,e,f必须依次往后移动。
** 顺序表-插入代码实现 **
#define MaxSize 10 //定义最大长度
typedef struct{
ElemType data[MaxSize]; //用静态的‘数组’存放数据元素
int length; //顺序表的当前长度
}SqList; //顺序表的类型定义(静态分配方式)
/**
* SqList &L : 线性表
* int i : 需要插入的位置
* int e : 需要插入的元素
*/
bool ListInsert(SqList &L,int i,int e){
if(i<1||i>L.length+1){ //判断i的范围是否有效
return false;
}
if(L.length>=MaxSize){ //判断存储空间已满,不能插入
return false;
}
for(int j=L.length;j>=i;j--){ //将第i个元素之后的元素一次后移
L.data[j]=L.data[j-1];
}
L.data[i-1]=e; //在位置i处放入e
L.length++; // 长度加1
}
int main(){
SqList L; //声明一个顺序表
InitList(L); //初始化顺序表
//....
ListInsert(L,3,3);
return 0;
}
** 顺序表-插入时间复杂度 **

最好情况:新元素插入到表尾,不需要移动元素
i=length+1,循环0次:
最好时间复杂度=O(1)
最坏情况:新元素插入到表头,需要将原有的n个元素全部像后移动
i=1,循环n次;
最坏时间复杂度=O(n);
平均情况:假设新元素插入到任何一个位置的概论相同,
即i=1,2,3,…,length+1的概率都是p= 1 n + 1 \frac{1}{n+1} n+11
i=1,循环n次:
i=2,循环n-1次
i=3,循环n-2次
…
i=n+1,循环0次
平均循环次数 = np + (n-1)p + (n-2)p + … + 1p = n ( n + 1 ) 2 \frac{n(n+1)}{2} 2n(n+1) 1 n + 1 \frac{1}{n+1} n+11 = n 2 \frac{n}{2} 2n
平均时间复杂度=O(n)
2.3.1.4.1.2 顺序表-删除
逻辑结构:


ListDelete(&Li,&e):删除操作。删除表L中第i个位置的元素并用e返回删除元系的值。
如果要删除一个元素,需要这个元素后面的元素依次前移一位,同时length-1。
** 顺序表-删除代码实现**
bool ListDelete(SqList &L,int i,int &e){
if(i<1||i>L.length){ //判断i的范围是否有效
return false;
}
e=L.data[i-1]; //将被删除的元素赋值给e
for(int j=i;j<L.length;j++){//将第i个位置后的元素前移
L.data[j-1]=L.data[j];
}
L.length--;//线性表长度减1
return true;
}
int main(){
SqList L; //声明一个顺序表
InitList(L); //初始化顺序表
//TODO
int e = -1; //用变量e把删除的元素带回来
if(ListDelete(L,3,3)){
printf("已删除第3个元素,删除元素的值为=%d\n",e)
} else {
printf("位序i不合法,删除失败\n");
}
}
** 顺序表-删除时间复杂度 **

最好情况:删除表尾元素,不需要移动其他元素
i=n,循环0次:
最好时间复杂度=O(1)
最坏情况:删除表头元素,需要后续的n-1个元素全部向前移动
i=1,循环n-1次;
最坏时间复杂度=O(n);
平均情况:假设删除任何一个元素的概率相同,
即i=1,2,3,…,length的概率都是p= 1 n \frac{1}{n} n1
i=1,循环n-1次:
i=2,循环n-2次
i=3,循环n-3次
…
i=n,循环0次
平均循环次数 = (n-1)p + (n-2)p + … + 1p = n ( n + 1 ) 2 \frac{n(n+1)}{2} 2n(n+1) 1 n \frac{1}{n} n1 = n − 1 2 \frac{n-1}{2} 2n−1
平均时间复杂度=O(n)
2.3.1.4.1.3 顺序表-按位查找
2.3.1.4.1.4 顺序表-按值查找
2.3.2 链表(链式存储)
3 栈和队列
4 串、数组和广义表
5 树和二叉树
6 图
6.1 图的定义和基本术语
定义:
图是由一组结点和一组连接这些结点的边组成的非线性结构。图可以用于表示各种实际问题,如网络、地图、社交关系等。在图中,结点被称为顶点,边被称为边或弧。图可以用以下方式定义:
图G是一个二元组G=(V,E),其中V是顶点集合,E是边集合。每条边连接两个不同的顶点。边可以是有向或无向的。如果边是有向的,则称之为有向图。如果边是无向的,则称之为无向图。如果图中有环,则称之为有向环或无向环。如果图中不存在环,则称之为无环图或森林。
简单说图是由节点(顶点)和边组成的一种数据结构,用于描述不同事物之间的关系和连接。
基本术语:
- 节点/顶点:表示图中的一个元素,比如人、物品、地点等。
- 边/弧:表示节点之间的连接,可以带有权重(权值)表示两个节点之间的距离、耗费等。
- 无向图:每条边都是双向的,比如交通路网中的道路。
- 有向图:每条边都是单向的,比如流程图中的箭头。
- 权重图:边带有权重(也叫边权),表示两个节点之间的距离、耗费等。
- 完全图:任意两个节点之间都有边相连的图。
- 子图:一个图的一部分,同样也是一个图。
- 连通图:图中每个节点都能通过边连接到其他节点,没有孤立的节点。
- 带权最短路径:在权重图中,两个节点之间距离最短的路径。
- 点度:指节点的度数,即与该节点相连的边数。
- 图的遍历:按照一定规则依次访问图中的所有节点,以便了解图的信息和结构。常见的遍历算法有深度优先搜索和广度优先搜索。
6.2 图的存储结构
图(Graph)是一种非常常见的数据结构,用于表示对象之间的关系。有两种主要的图的存储结构:邻接矩阵和邻接表。
-
邻接矩阵(Adjacency Matrix): 邻接矩阵是用二维数组来表示图的连接关系的数据结构。如果图中有n个顶点,那么邻接矩阵是一个大小为n x n的矩阵。矩阵的行和列分别代表图中的顶点,矩阵中的值表示两个顶点之间是否有边或权重。如果两个顶点之间有边相连,则矩阵中对应的元素为1或表示边的权重值。这种表示方法对于稠密图比较有效,但对于稀疏图可能会造成空间浪费。
-
邻接表(Adjacency List): 邻接表是用链表或数组来表示图的连接关系的数据结构。对于每个顶点,邻接表会存储与其相邻的顶点列表。在链表实现中,每个顶点有一个链表,链表中的节点表示与该顶点相邻的顶点。在数组实现中,数组的每个元素是一个列表,列表中存储了与对应顶点相邻的顶点。邻接表的存储方式适用于表示稀疏图,节省了空间。
除了邻接矩阵和邻接表外,还有其他的图存储结构,如邻接多重表、十字链表、边集数组等。不同的存储结构适用于不同类型的图,选择合适的存储结构可以提高图的存储和操作效率。
选择哪种存储结构取决于图的特性以及具体的应用需求。邻接矩阵适合表示稠密图和静态图,而邻接表适合表示稀疏图和动态图。在选择存储结构时需要考虑空间复杂度和时间复杂度的权衡。
6.2.1 邻接矩阵
6.2.2 邻接表
3.2.3 十字链表法
6.2.4 邻接表多重表
7 查找
7.1 线性表的查找
7.1.1 顺序查找
7.1.2 折半查找
7.1.3 分块查找
7.2树表的查找
7.2.1 二叉排序树
7.2.2 平衡二叉树
8 排序
8.1 基本概念和排序方法的概述
1.排序(Sorting)是按关键字的 非递减 或 非递增顺序对一组记录重新进行排列的操作。
2.排序的稳定性:待排序序列中存在两个或两个以上关键字相等的记录时,排序所得结果唯一,则排序稳定。
3.排序分类
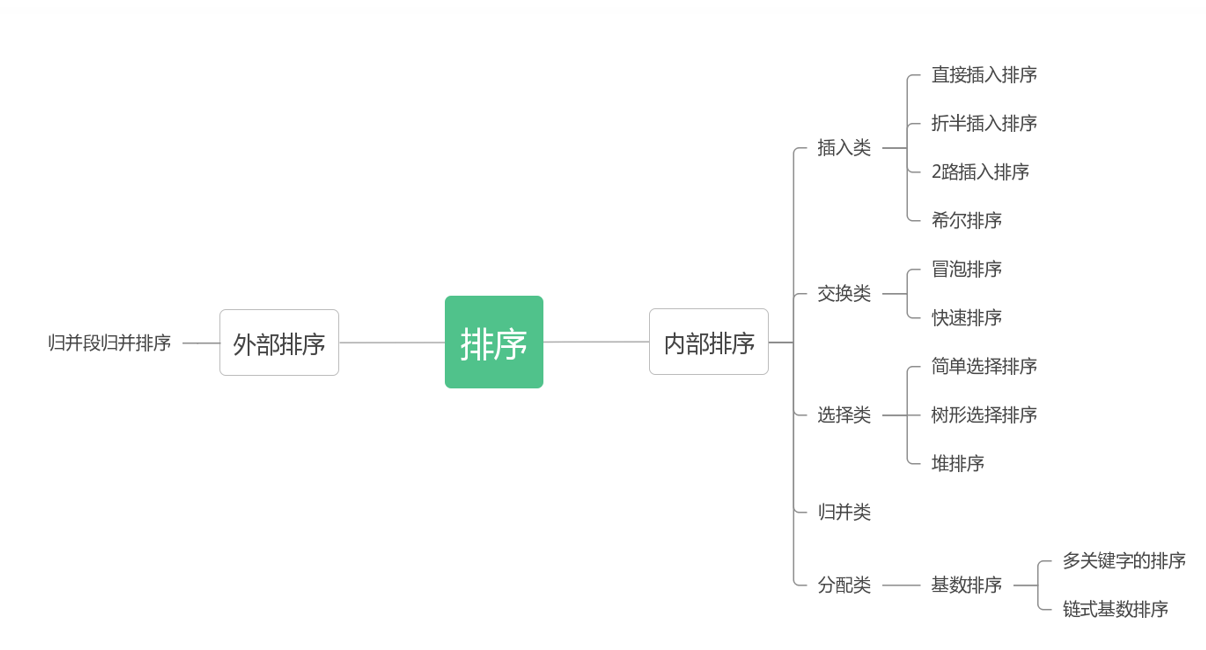
内部排序:待排序记录全部存放在计算机内存中进行排序的过程;
(1)插入类:将无序子序列中的一个或几个记录“插入”到有序序列中,从而增加记录的有序子序列的长度。
(2)交换类:通过"交换"无序序列中的记录从而得到其中关键字最小或最大的记录,并将它加入到有序子序列中,以此方法增加记录的有序子序列的长度。
(3)选择类:从记录的无序子序列中“选择”关键字最小或最大的记录,并将它加入到有序子序列中,以此方法增加记录的有序子序列的长度。
(4)归并类:通过“归并”两个或两个以上的记录有序的子序列,逐步增加记录的有序序列的长度。
(5)分配类:是唯一一类不需要进行关键字之间比较的排序方法,排序时主要利用分配和收集两种基本操作来完成。基数排序是主要的分配类排序方法。
外部排序:待排序记录的数量很大,内存依次读不完全部记录,在排序过程中尚需要对外存进行访问的排序过程。
8.2 插入排序
8.2.1 直接插入排序
8.2.2 折半插入排序
折半插入排序
折半插入排序(Binary Insertion Sort)是对插入排序算法的一种改进。采用折半查找法查找当前记录在已经排好序的序列中的插入位置。
算法思路
先用折半查找找到对应的插入位置,在移动元素。当low>high时停止折半查找,应当将[low,i-1]内的元素全部右移,并将A[0]复制到low所指位置。
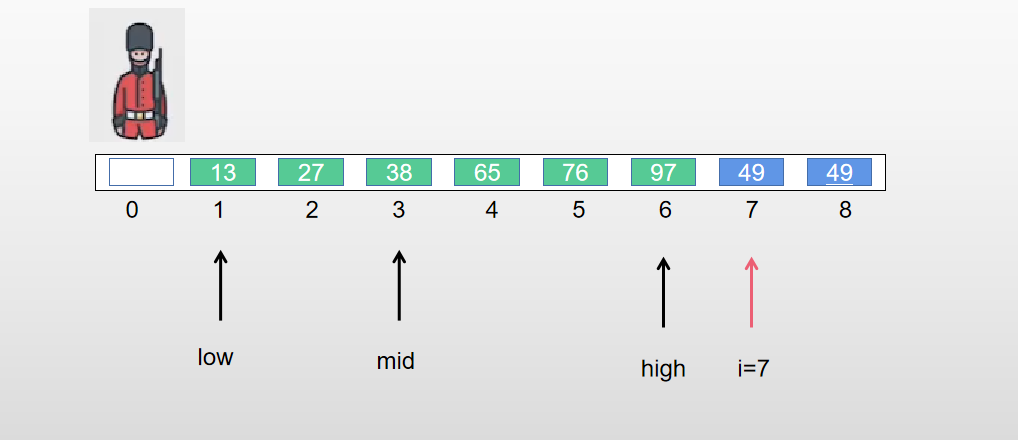
2 路插入排序 (由折半插入排序优化)
8.2.3 希尔排序
8.3 交换排序
8.3.1 冒泡排序
8.3.2 快速排序
8.4 选择排序
8.4.1简单选择排序-直接选择排序
8.4.2树形选择排序-锦标赛排序
8.4.3堆排序
8.5 归并排序
8.6 基数排序
8.7 *外部排序
文件
















 40万+
40万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











