






论文(设计)题目:基于大数据出租房交易市场数据分析及可视化
问题的提出:
自从网络爬虫研究出现以来,大部分传统网络爬虫都是首先设定一个或者若干个入口 URL,在抓取网页的过程中,按照抓取的策略,从当前页面上提取出新的 URL放入队列,以便获取 URL 对应的网页内容,将网页内容保存到本地,然后,再提取有效地址作为下一次的入口 URL,直到爬行完毕。但是,传统的网络爬虫无论采用哪种策略,随着网页数量的剧增,大量的无关网页会被下载。鉴于以上的缺点,本文的网络爬虫采用的是基于 API 的数据抓取,与传统的网络爬虫相比,API 接口为网络爬虫程序高效获取天气数据提供了保障。 搜索引擎是一个实用性很强的研究领域,而网络爬虫又是作为搜索引擎的重要的组成部分,因此,网络爬虫是值得我们去了解和研究,其重要性非比寻常!而针对与日常生活息息相关的出租房的房源数据特定网络爬虫,更值得我们去深入了解和研究。
课题研究的目的和意义:
搜索引擎是运用特定的计算机应用程序,能够自动的从网络上进行数据信息的搜集,并采用了一定的策略和手段,对搜集到的数据进行适当的整理,然后,以供用户进行信息检索的系统。它如果要进行追溯的话,搜索引擎的发展历史要比万维网还要悠久的多,针对搜索引擎进行数据的爬取,将爬取的数据进行大数据手段以及可视化方式呈现,可实现数据的价值。
网络爬虫程序采用有效的算法及策略,对58网API接口内的数据,进行分析、识别、抓取等操作。最后,网络爬虫程序通过结构化网络数据抽取的方式,将房源数据保存到数据库中,以便日后用于数据挖掘,以及对某个或某些城市,房源信息进行研究。
课题研究的主要内容和解决的方法:
本系统所采用的数据来源于58同城网(https://hrb.58.com/chuzu),首先在 HTML 文件中,当某个超链接被选择后,被链接的那个 HTML 文件就会执行深度优先搜索,在搜索其他的超链接的结果以前,必须完整地进行搜索单独的一条链接。 深度优先搜索将会沿着 HTML 文件上的超链接不断的进行,进行到不能再深入为止。 返回到某个 HTML 文件,再继续选择这个 HTML 文件中的其他的超链接,不断循环。当没有其他的超链接可供选择时,说明到了叶子结点,无法继续再进行下去了,即该搜索操作已经结束,其次针对数据清洗以及数据存储。
本课题基于webmagic爬虫分析情况,做如下功能的大数据分析:
各区域租房平均单价数据分析
房屋面积与租金数据分析
房屋租金支付方式数据分析
房屋地区数据分析
房屋类型数据分析
租房面基房源数据分析
基于Spark-ML或者协同过滤算法进行房屋数据推荐(用户端)
针对以上需求,解决方案设计如下:
1.数据生产:使用Spark对数据进行清洗,采集数据包含如下内容:
分析数据要求:
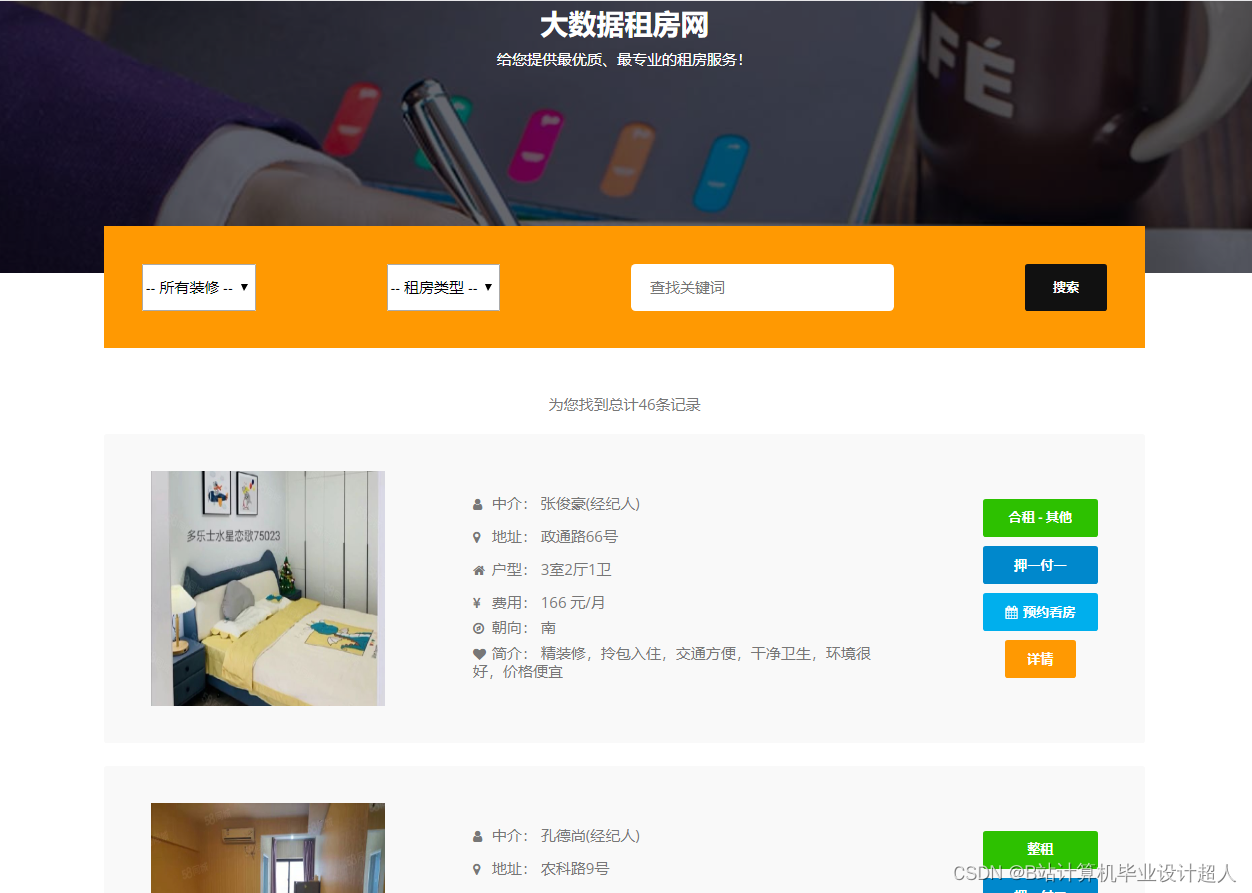
房屋标题、房屋租金、租金支付方式、租赁方式、房屋类型、房屋大小、房屋装修、房屋朝向、房屋楼层、房屋高度、所在小区、所属区域、详细地址、房屋图片、房屋最近发布时间、房屋所属、房屋配置、房屋亮点、房屋描述、详情页地址等信息。
数据加工处理
使用大数据技术对原始数据进行加工处理,得到用于分析和可视化展示的目标数据。
数据加工处理包括:
数据清洗处理
分两次过滤:
对“脏”数据、不符合要求数据、空瘪数据进行集中过滤;
过滤选择重复数据相关内容;只保留数据内容丰富的数据集。
在json数据中,删除重复值,指定数据类型,对‘house_type’进行分列。在MySQL中创建数据库并导入数据,对于房屋类型为空的数据进行删除或者格式化。
数据格式化处理
该过程包括:
统一数据结构编码
统一数据类型
统一数字计量单位
格式化时间,北京时间(YYYY-MM-DD 24HH:MI:SS)
为每条数据计算唯一标识
数据关联补齐处理
该过程包括:
为数据增加属性信息:更新时间、ID等信息的补齐
为数据增加指代信息:数据为空或者异常可指代为暂无信息等
数据聚类、归并处理
该过程包括:
针对数据存在重复都情况、或相似数据进行集中归并处理
针对数据是零散分布,为满足不同分析功能,将相同维度数据进行聚类
数据水平、垂直分解
为满足不同的分析功能,webmagic爬虫采集的数据按照不同进行拆解,如时间区间,特定数据维度的拆解
数据多源输出
能够向不同的数据存储服务输出数据,包括:
日志平台Log4j本地日志
业务数据库,MySQL
本地文件系统,CSV表格
实时查看webmagic爬虫相关信息执行情况
3.数据仓库
使用MySQL存储各功能数据集
对原始数据、各功能数据集管理的功能
支持系统查看、下载、删除服务器数据、各数据集
4.展示内容包含不限于以下
对原始数据展示,包含房屋标题、房屋租金、租金支付方式、租赁方式、房屋类型、房屋大小、房屋装修、房屋朝向、房屋楼层、房屋高度、所在小区、所属区域、详细地址、房屋图片、房屋最近发布时间、房屋所属、房屋配置、房屋亮点、房屋描述、详情页地址等内容。
b.各区域租房平均单价数据分析
c.房屋面积与租金数据分析
d.房屋租金支付方式数据分析
e.房屋地区数据分析
f.房屋类型数据分析
g.租房面基房源数据分析
h.基于Spark-ML或者协同过滤算法进行房屋数据推荐(用户端)
7. 房源数据分析和结论
基于以上分析结果,分析房源的描述内容,根据数据做出各模块统计图
基于以上分析结果,向用户推荐优质房源
基于以上分析结果,分析做出大屏统计图
5. 可视化呈现
通过大数据的手段对原始数据进行清洗、聚类分析、将分析后的结果采用可视化的图表进行展示。可视化可采用Vue框架进行Web界面搭建,后台采用SpringBoot+SparkSQL做数据分析,实时展示出分析后的结果,将结果通过Http协议发送给Web端。交互形式采用Post/Get请求,服务端采用Flask框架对项目搭建。对于敏感数据采用PostgreSQL/MySQL/Oracle等数据库实时存储,采用云服务器,如阿里云服务器对项目继承部署,线上交互,实时动态分析,通过可视化的图表直观的展示出分析结果。达到”一图胜千言”的目的。其分析结果展示样例如下:
(1)郑州地区各户型房屋数量;
(2)郑州市各区房源情况;
房屋面积与租金数据分析
6. 系统性能要求
具有实时数据展示和动态更新的能力、查询无异常的情况喜爱等待的时间不会超过3秒、可视化的页面配置,和响应时间不会超过2秒,同时我们业务展示时用户页面,基本上等待延迟不会超过3秒,可通过线上服务器部署,如线上服务器需要对程序进行监控,如Supervisor对系统进程监控,Java开发可采用jar包部署项目,通过Nginx做负载均衡,可保证7*24小时连续稳定工作,每月的故障率不超过3次。
7. 接口规范
系统各个模块功能实现之后需要对其进行功能测试,主要的方法是通过数据增、删、改、查的方式进行测试。另外为输出数据进行主要测试,我们在代码开发过程中,添加了API标准接口输出规范,当数据正确定且合理的情况下,输出“success”,当数据接口异常的时候输出“fail”。
附:该数据集进行网络爬虫,各字段含义如下:
house_title:房屋标题
house_pay:房屋租金
house_pay_way:租金支付方式
rent_way:租赁方式
house_type:房屋类型
house_area:房屋大小
house_decora:房屋装修
toward:房屋朝向
floor:房屋楼层
floor_height:房屋高度
house_estate:所在小区
area:所属区域
address:详细地址
pic:房屋图片
time:房屋最近发布时间
agent_name:房屋所属
house_disposal:房屋配置
house_spot:房屋亮点
house_desc:房屋描述








核心算法代码如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









