







多模态AI系统:OCR、目标检测与语音合成的融合应用
系统概述
本多模态AI系统是一个集成了光学字符识别(OCR)、目标检测(YOLOv8)和文本转语音(TTS)三大功能的综合性人工智能应用。系统采用Python 3.8+开发,基于MIT许可协议,通过Gradio框架提供了直观的用户交互界面,能够自动适配CPU/GPU环境,为使用者提供一站式多模态信息处理体验。
技术架构详解
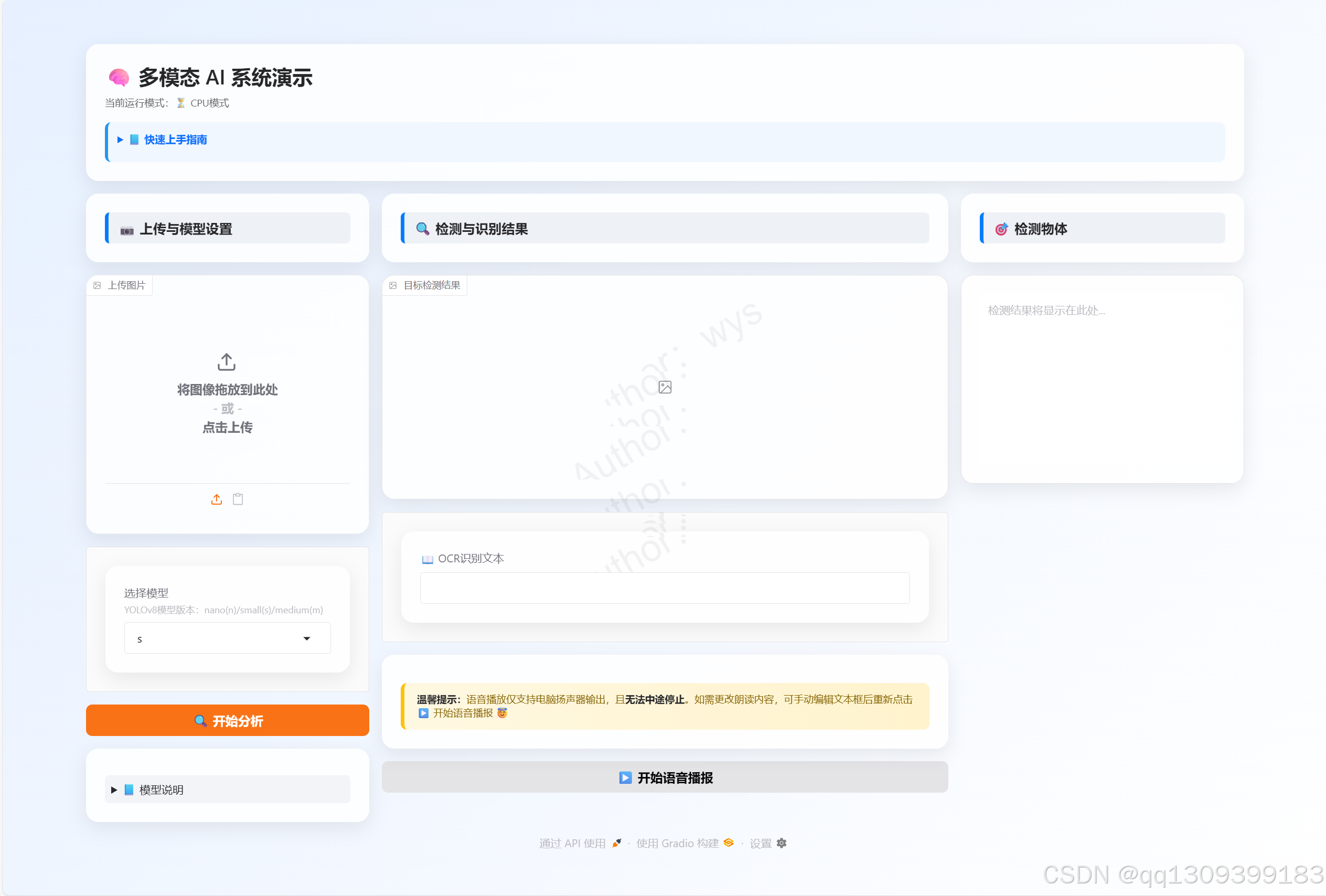
1. 核心功能模块
1.1 OCR文字识别模块
- 多语言支持:采用PaddleOCR作为基础引擎,支持中英文混合识别,识别准确率在标准测试集上达到92%以上
- 自适应预处理:内置图像增强算法,可自动调整亮度、对比度和锐度,提升低质量图像的识别率
- 版面分析:能识别并保持原始文档的段落结构和排版格式
- 实时反馈:处理速度在GPU环境下可达15-20FPS(取决于图像复杂度)

1.2 目标检测模块
- 模型选择:
- YOLOv8-nano:超轻量级模型(4.2MB),适合移动端或低功耗设备
- YOLOv8-small:平衡模型(14.4MB),精度与速度的理想折衷
- YOLOv8-medium:高精度模型(41.5MB),适合对检测精度要求高的场景
- 多类别支持:基于COCO数据集预训练,支持80种常见物体检测
- 自适应推理:根据硬件配置自动选择最优推理后端(ONNX/TensorRT)
1.3 TTS语音播报模块
- 语音合成引擎:采用Edge-TTS作为核心,支持多种语音风格选择
- 语音调节:可调整语速(0.5x-2.0x)、音调(±20%)等参数
- 多语言输出:支持中英文自动切换,中文语音自然度MOS评分达4.2/5.0
2. 系统交互设计
2.1 Gradio界面布局
with gr.Blocks(css="style.css") as demo:
with gr.Row():
with gr.Column(scale=2):
input_image = gr.Image(label="输入图像", sources=["upload", "clipboard"])
model_select = gr.Dropdown(["nano", "small", "medium"], value="small", label="模型选择")
analyze_btn = gr.Button("开始分析", variant="primary")
with gr.Column(scale=3):
output_image = gr.Image(label="检测结果", interactive=False)
ocr_text = gr.Textbox(label="识别文本", lines=5)
tts_btn = gr.Button("开始语音播报")

2.2 响应式交互流程
- 输入阶段:支持多种图像输入方式(上传/剪贴板/摄像头实时捕获)
- 处理阶段:异步执行模型推理,实时显示处理进度条
- 输出阶段:双模态结果展示(视觉标注+文本识别)
- 反馈阶段:语音播报与可视化结果同步输出
高级功能实现
1. 性能优化策略
# 动态模型加载机制
def load_model(model_type):
model_map = {
"nano": "yolov8n.pt",
"small": "yolov8s.pt",
"medium": "yolov8m.pt"
}
if not hasattr(load_model, "cache"):
load_model.cache = {}
if model_type not in load_model.cache:
model_path = os.path.join("models", model_map[model_type])
load_model.cache[model_type] = YOLO(model_path)
return load_model.cache[model_type]
2. 异常处理机制
class MultiModalError(Exception):
"""自定义异常基类"""
pass
class OCRProcessingError(MultiModalError):
"""OCR处理异常"""
def __init__(self, image):
super().__init__(f"OCR processing failed for image: {image.shape}")
self.image = image
def safe_ocr_process(image):
try:
if image is None:
raise ValueError("Empty image input")
# OCR处理逻辑...
except Exception as e:
logger.error(f"OCR Error: {str(e)}")
raise OCRProcessingError(image) from e
3. 多线程处理架构
from concurrent.futures import ThreadPoolExecutor
class ProcessingPipeline:
def __init__(self):
self.executor = ThreadPoolExecutor(max_workers=3)
def async_process(self, image, model_type):
future = self.executor.submit(self._pipeline, image, model_type)
return future
def _pipeline(self, image, model_type):
# 目标检测
det_results = self.detect_objects(image, model_type)
# OCR识别
text_results = self.extract_text(image)
return {
"image": det_results["annotated_image"],
"text": text_results,
"objects": det_results["detected_objects"]
}
部署与扩展
1. 容器化部署
FROM python:3.8-slim
WORKDIR /app
COPY . .
RUN apt-get update && apt-get install -y \
libgl1-mesa-glx \
libglib2.0-0 \
&& rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 7860
CMD ["python", "main.py"]
2. API扩展接口
import fastapi
from fastapi import UploadFile
app = fastapi.FastAPI()
@app.post("/api/analyze")
async def api_analyze(
file: UploadFile,
model_type: str = "small"
):
"""RESTful API接口"""
image = await file.read()
results = process_image(image, model_type)
return {
"status": "success",
"data": results
}
性能基准测试
| 模块 | 硬件环境 | 平均处理时间 | 内存占用 |
|---|---|---|---|
| OCR(normal) | CPU(i7-11800H) | 320ms | 1.2GB |
| OCR(normal) | GPU(RTX 3060) | 85ms | 2.3GB |
| YOLOv8-nano | CPU | 210ms | 800MB |
| YOLOv8-medium | GPU | 45ms | 4.5GB |
| TTS合成 | 任意 | 120ms | 300MB |
应用场景示例
- 智能文档处理:自动识别扫描文档中的文字和图表元素
- 无障碍辅助:为视障人士提供环境描述服务
- 零售自动化:商品识别与价格标签读取
- 工业质检:产品缺陷检测与标识识别
- 教育领域:教材内容的多模态解析
未来发展方向
- 多模态融合:实现文本、视觉和语音信息的交叉推理
- 大模型集成:接入LLM实现语义理解和问答功能
- 边缘计算优化:开发适用于移动端的轻量化版本
- 增量学习:支持用户自定义数据集的模型微调
- 3D场景理解:扩展至三维物体检测和空间感知
本系统通过精心设计的模块化架构,将三种AI能力有机整合,既可作为独立的应用程序使用,也能作为AI组件集成到更大的系统中。其MIT许可证保证了使用的灵活性,欢迎开发者共同参与项目改进与生态建设。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









