









一. 处理中文分词 以及 ik分词器的应用
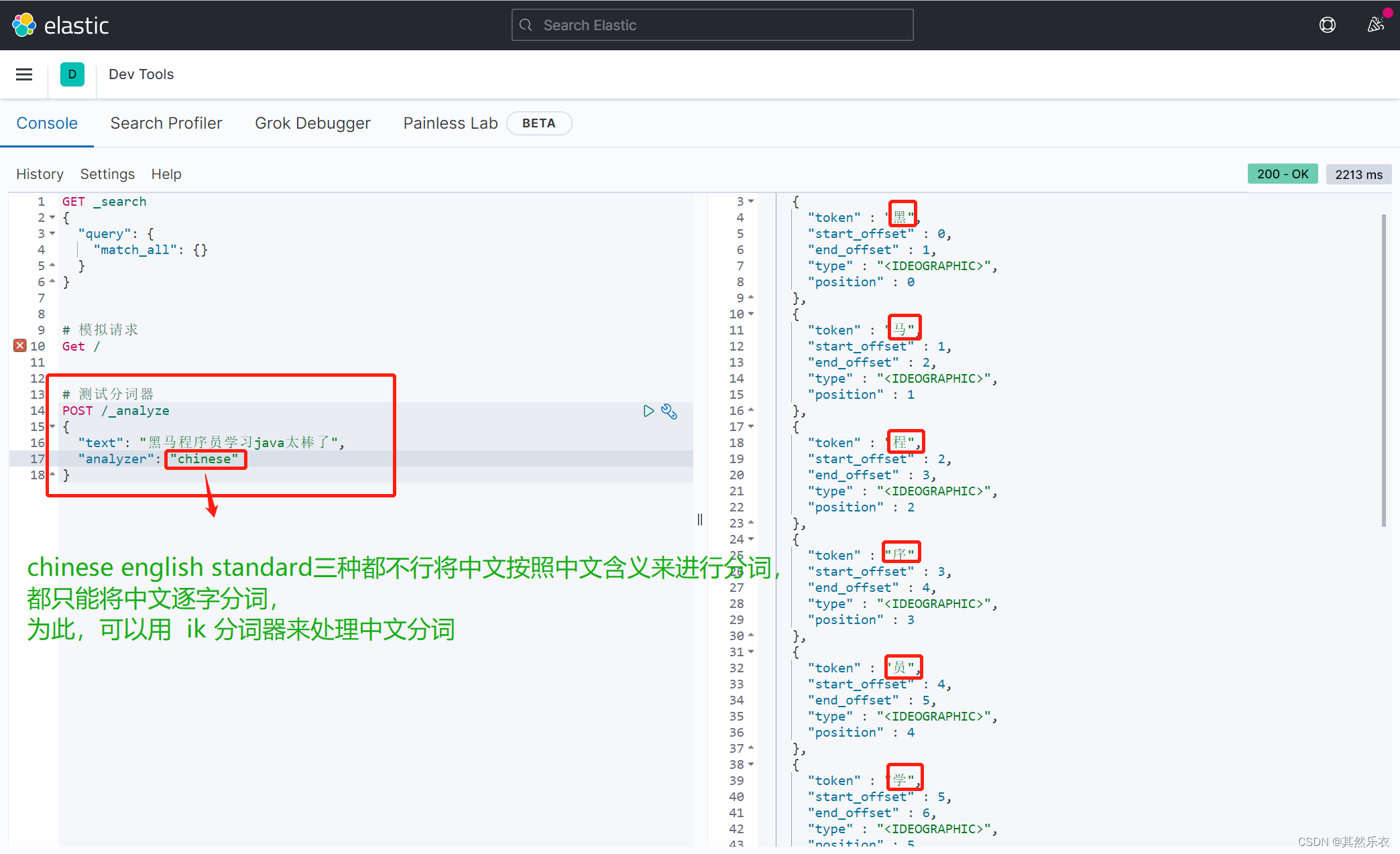
解决:
1. 在es-plugins中添加安装 ik分词器
IK分词器包含两种模式:
-
ik_smart:最少切分
-
ik_max_word:最细切分
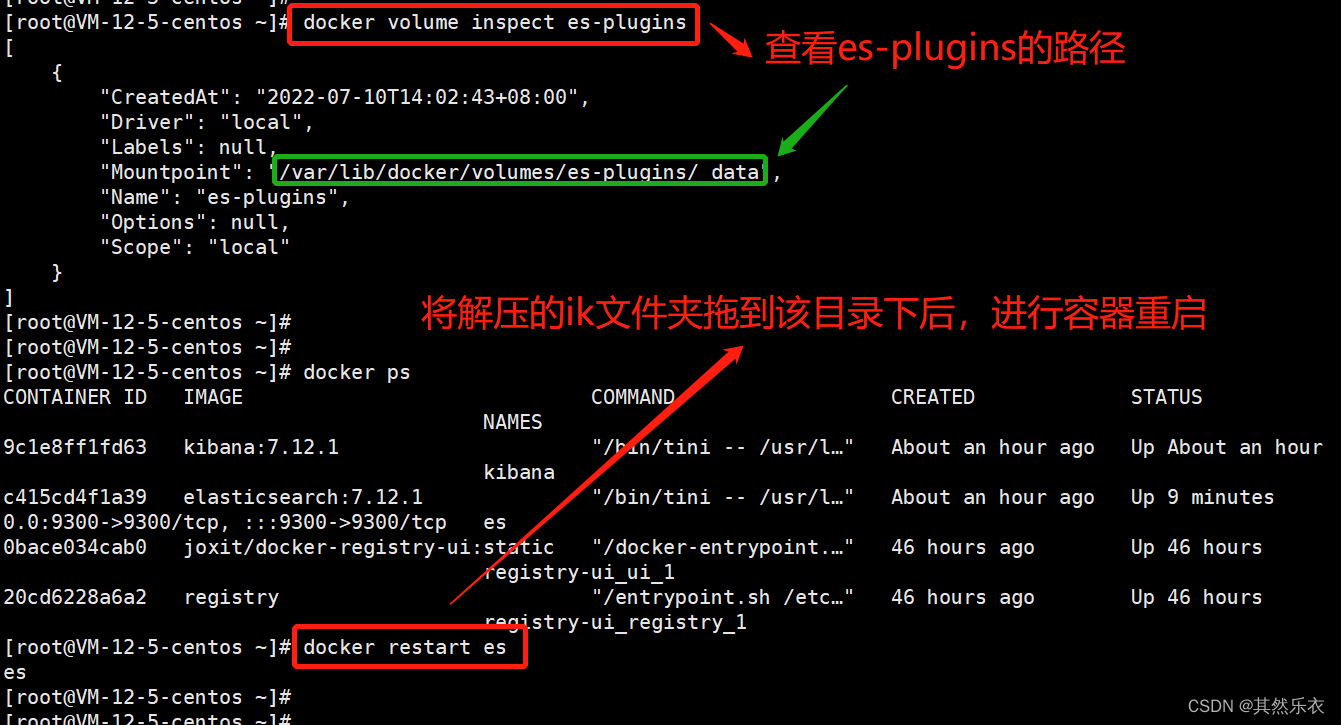
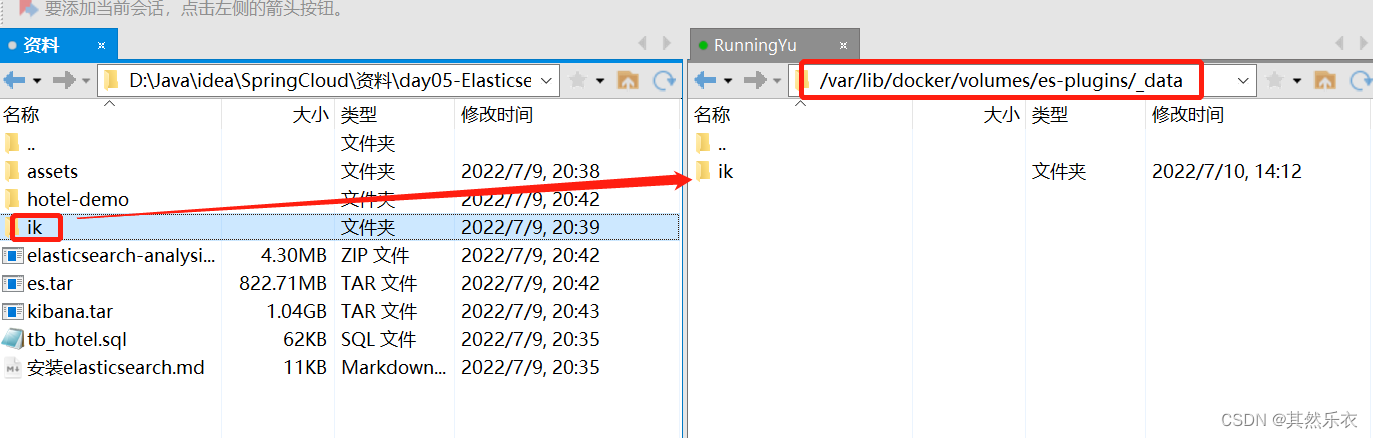
2. 容器es重启(命令:docker restart es)后,
进行ik_smart 或 ik_max_word分词器的运用便可以将中文按照中文含义进行分词了
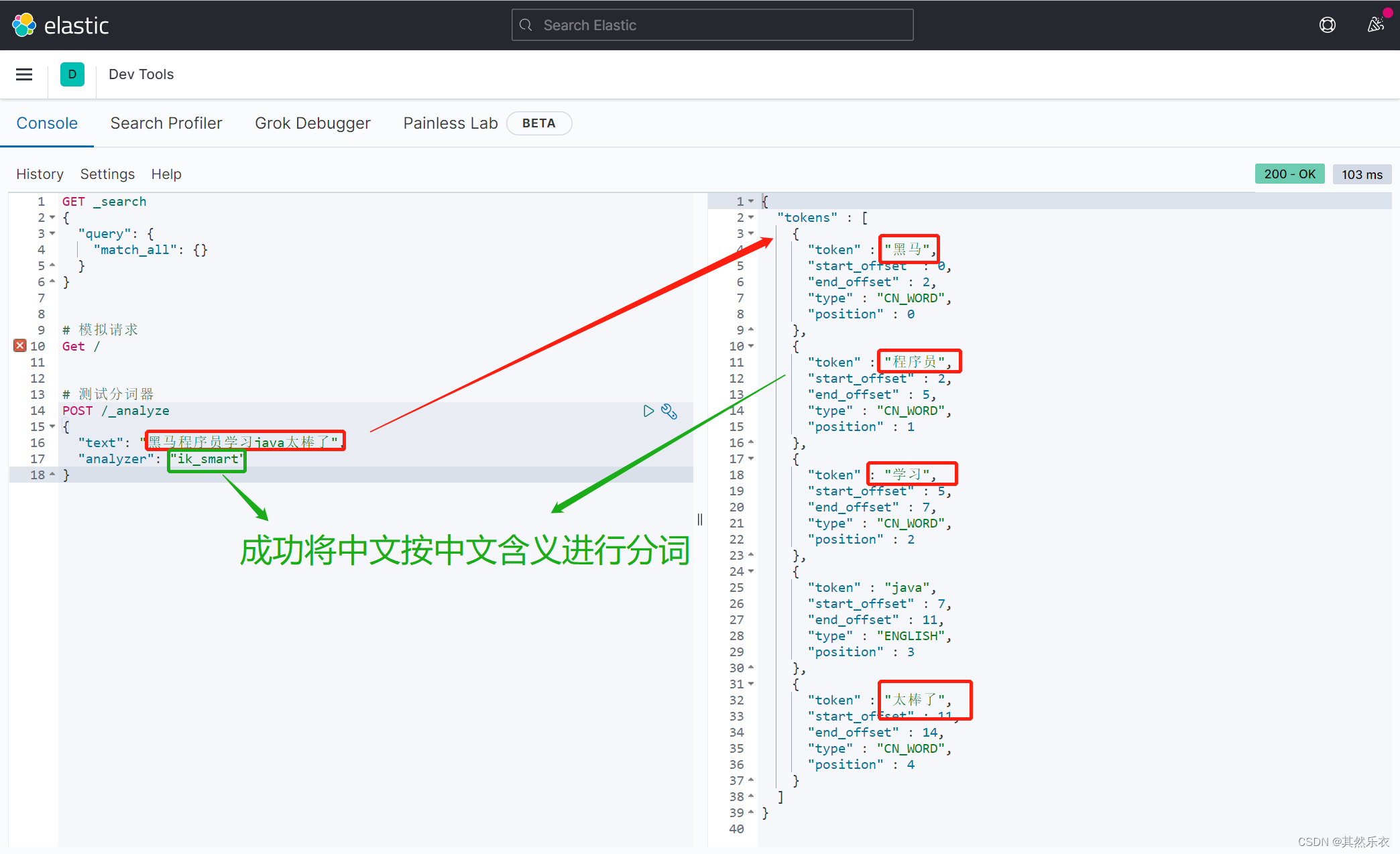
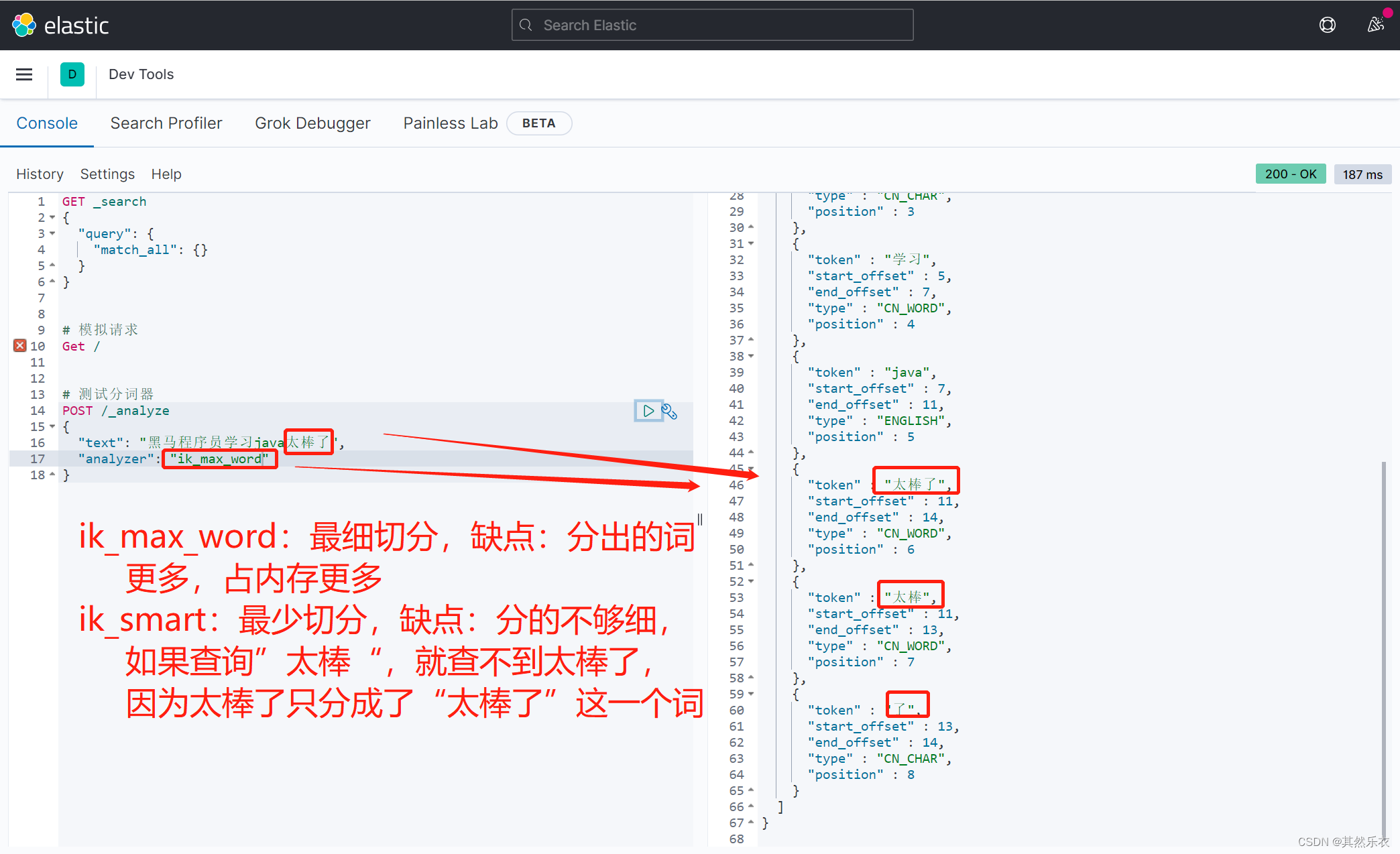
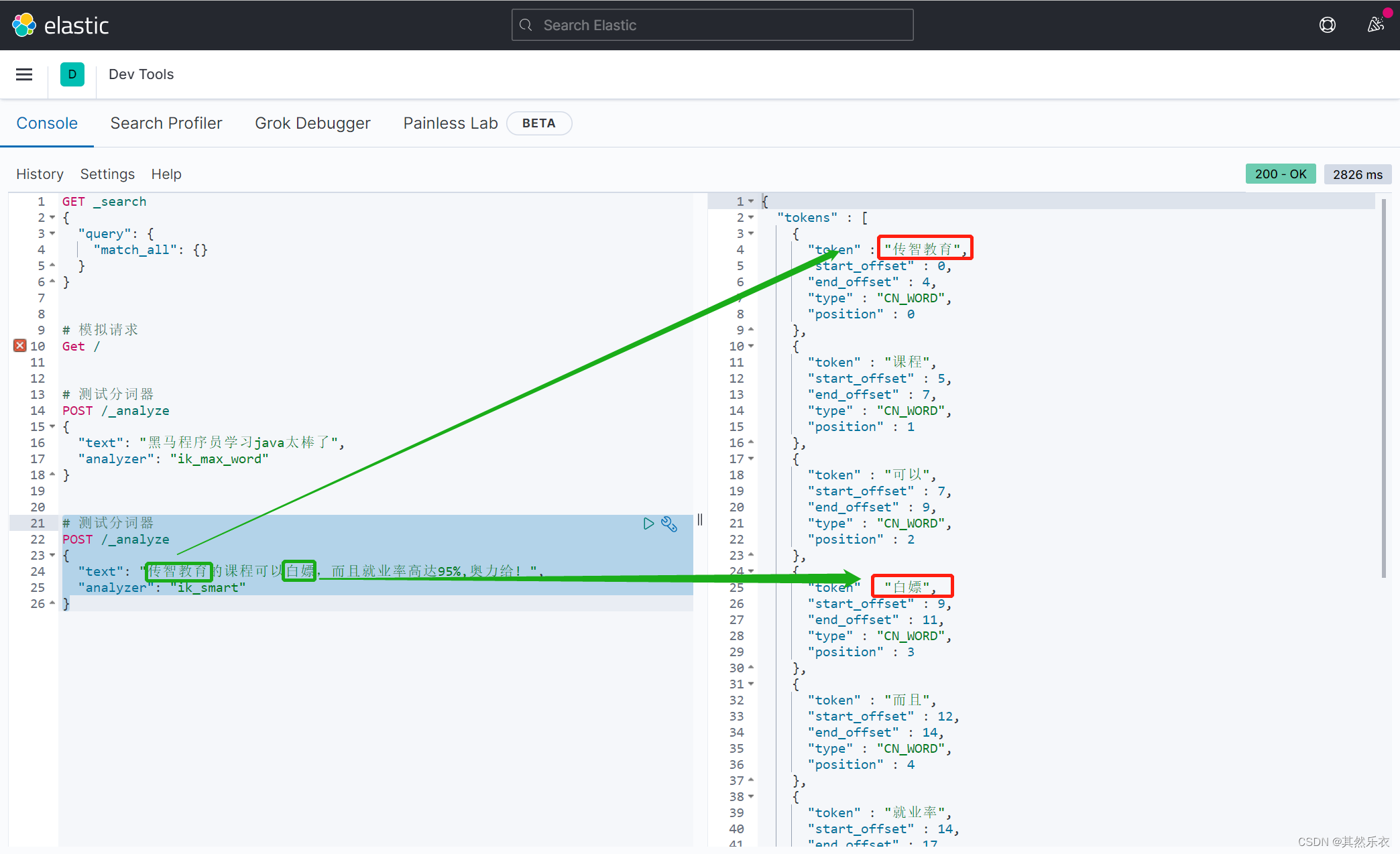
测试例子:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "黑马程序员学习java太棒了"
}结果:
{
"tokens" : [
{
"token" : "黑马",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "程序",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "学习",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 5
},
{
"token" : "太棒了",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "太棒",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "了",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 8
}
]
}二. 拓展字典 和 停止字典 的应用
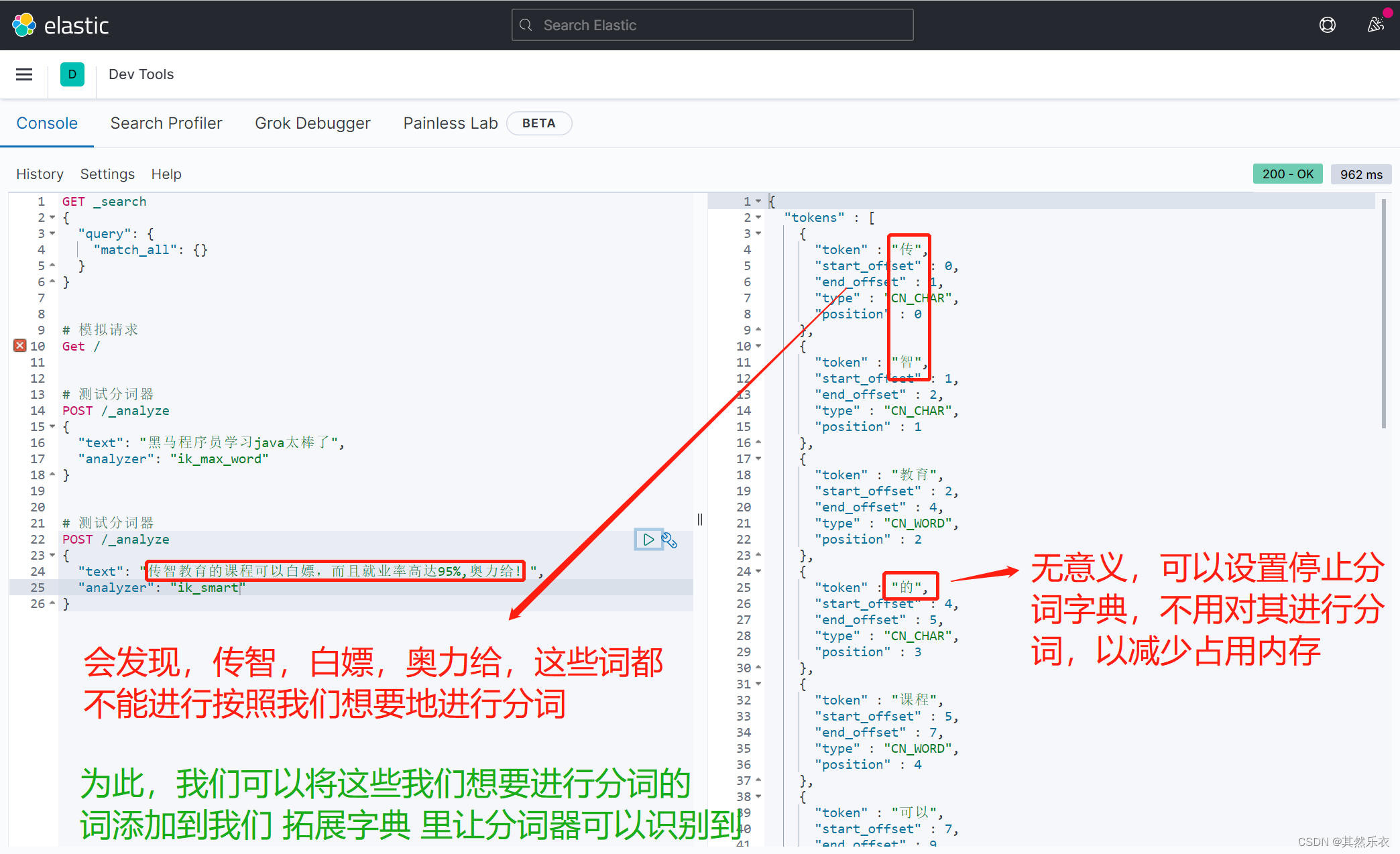
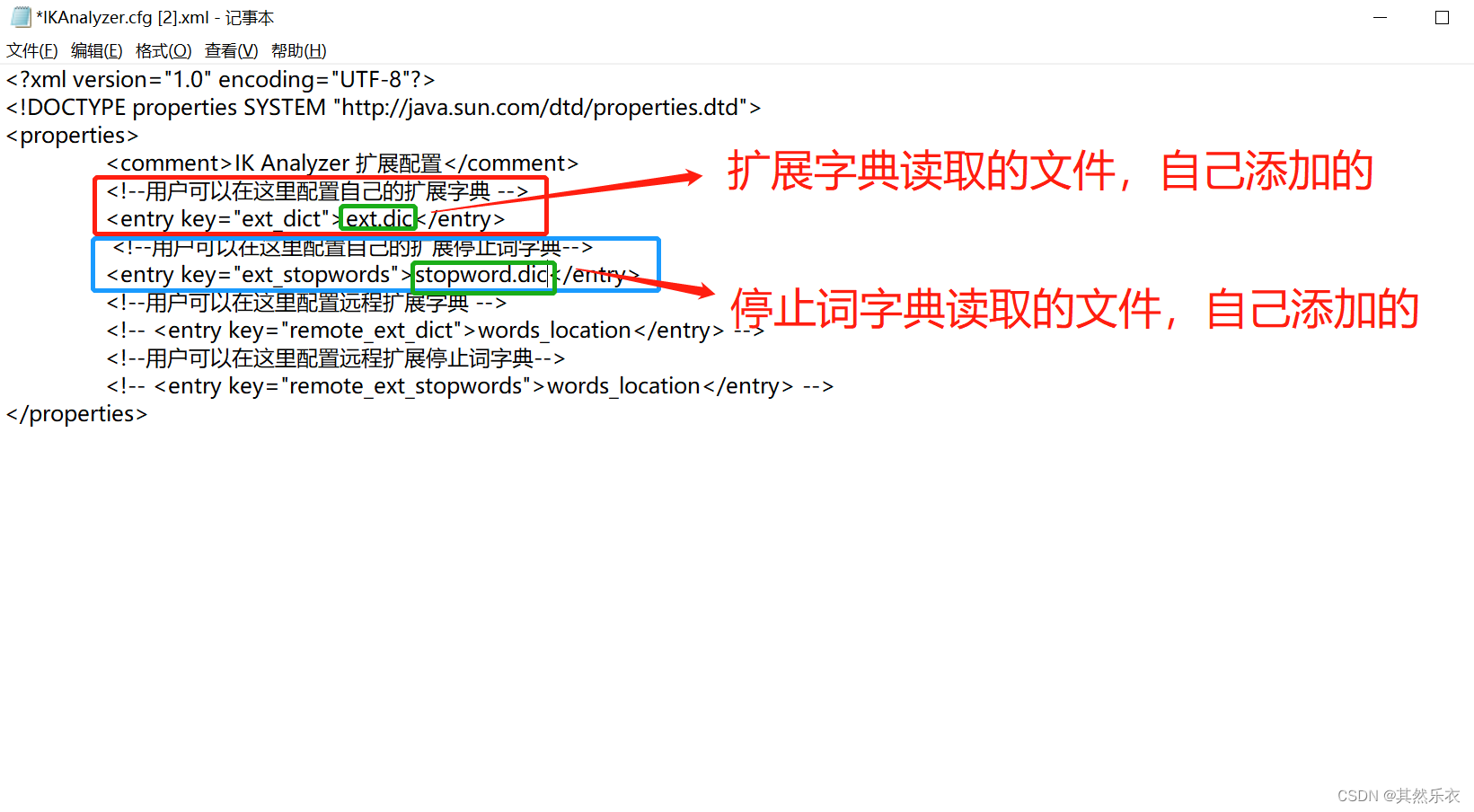
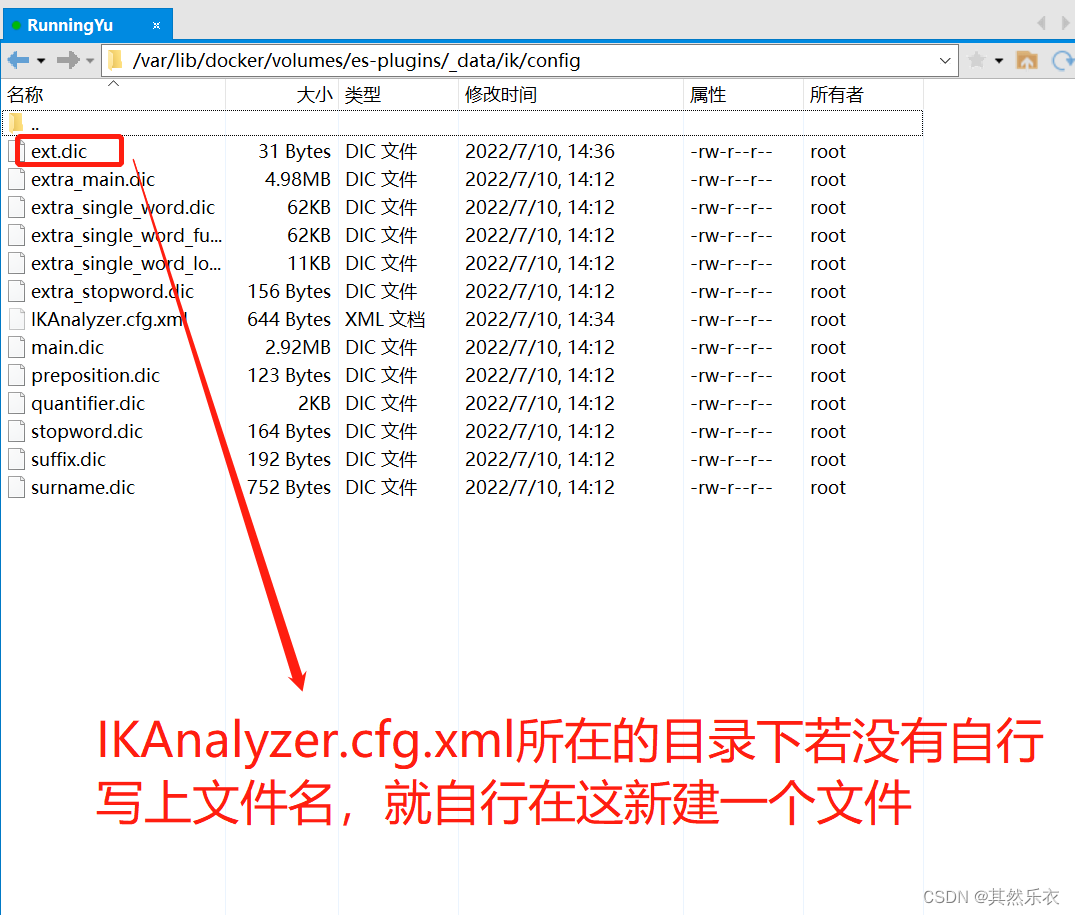
添加 拓展分词 和 停止分词
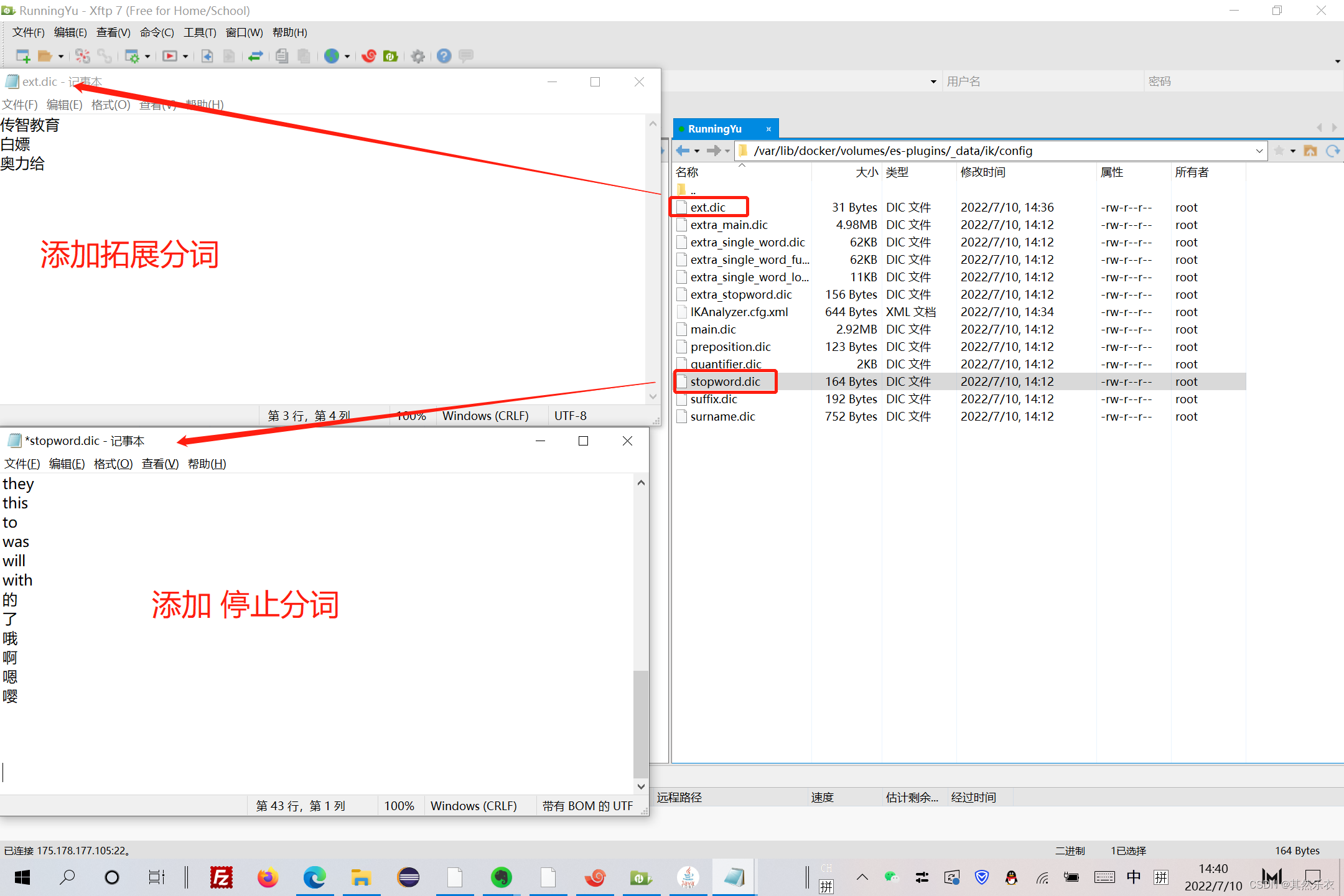
运行重启命令,重启容器es: docker restart es
之后便可以对特许设置的词进行分词或是部分词了















 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









