






1、sequence的设置:
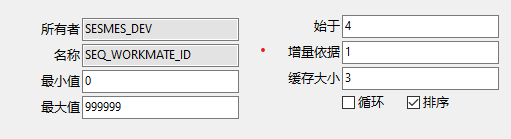
最小值设置为0,
2、游标的使用
%rowtype 只能接收整行数据,%Type适合接收一个字段
declare
cursor vrows is
select RESULTS from table;
vrow table.RESULTS%type;
begin
open vrows;
loop
fetch vrows
into vrow;
exit when vrows%notfound;
dbms_output.put_line(vrow);
end loop;
close vrows;
end;
declare
cursor vrows is
select RESULTS, VOLTAGE from table;
vrow table.RESULTS%type;
vnew table.VOLTAGE%type;
begin
open vrows;
loop
fetch vrows
into vrow, vnew;
exit when vrows%notfound;
dbms_output.put_line(vrow || vnew);
end loop;
close vrows;
end;
declare
cursor vrows is
select * from table;
vrow table%rowtype;
begin
open vrows;
loop
fetch vrows
into vrow;
exit when vrows%notfound;
dbms_output.put_line(vrow.CELLCODE);
end loop;
end;
- 无变量的游标

- 有变量的游标

3、系统游标

4、for循环遍历游标

5、系统异常

6、自定义异常


7、case中使用%
SELECT
a,
CASE WHEN A LIKE ‘300%’ THEN b ELSE -b END AS b
FROM ZZZTEST WHERE (A LIKE ‘300%’ OR A LIKE ‘400%’);
8、查询库中的表名和表中记录数:
SELECT T.TABLE_NAME, T.NUM_ROWS FROM USER_TABLES T;
9、查询库中记录总数:
SELECT SUM(A.NUM_ROWS)
FROM (SELECT T.TABLE_NAME, T.NUM_ROWS FROM USER_TABLES T) A;
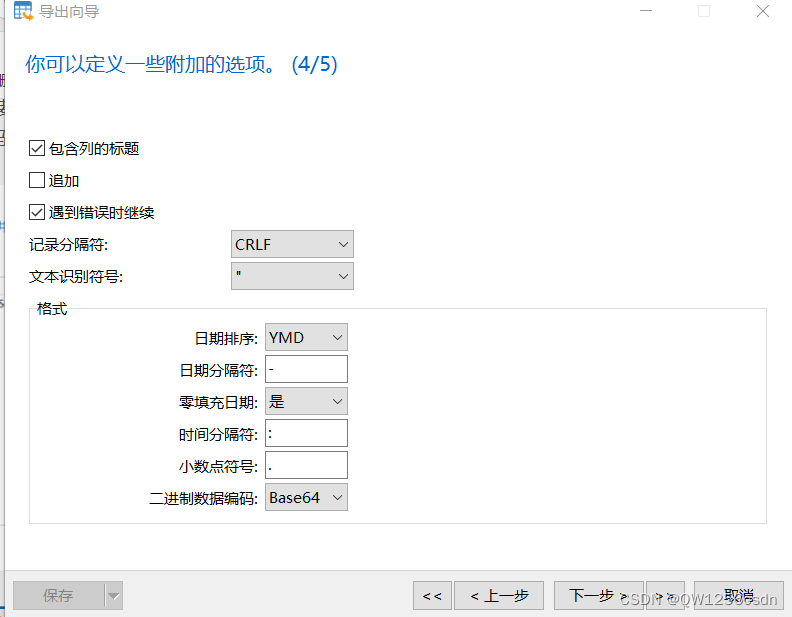
10、Navicat导出数据
导大批量数据使用navicat要比PL/SQL快很多很多;
不过在导出时需要注意几个问题:
-
防止中文乱码;
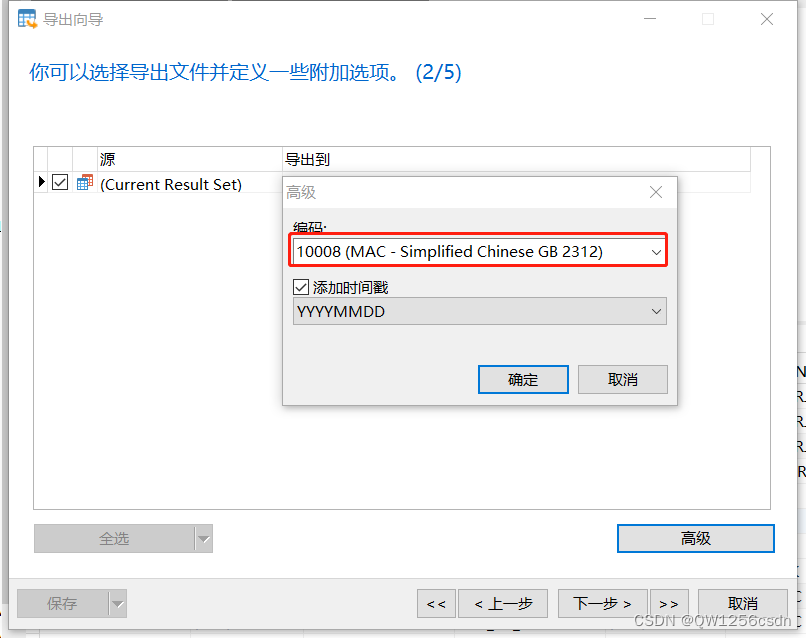
-
防止时间格式错误
11、oracle中日期被误存为varchar2类型,如何转为date
varchar2类型的日期 19-NOV-21 06.11.01.000000000 PM转为date
to_date( to_char(TO_TIMESTAMP(t1.start_time, 'dd-MON-yy hh.mi.ss.ff PM', 'NLS_DATE_LANGUAGE = english'), 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')
12、数据库中锁表
- 查看oracle数据库中表是否被锁
select b.owner TABLEOWNER,b.object_name TABLENAME,c.OSUSER LOCKBY,c.USERNAME LOGINID, c.sid SID, c.SERIAL# SERIAL from v$locked_object a,dba_objects b,v$session c where b.object_id = a.object_id AND a.SESSION_ID =c.sid;
- 通过SID, SERIAL解锁
alter system kill session 'SID, SERIAL';
- 查看锁表进程SQL语句
select sess.sid,
sess.serial#,
lo.oracle_username,
lo.os_user_name,
ao.object_name,
lo.locked_mode
from v$locked_object lo,
dba_objects ao,
v$session sess
where ao.object_id = lo.object_id and lo.session_id = sess.sid;
- 杀掉锁表进程:
alter system kill session '50,63547' immediate;
- 批量生成语句
SELECT 'alter system kill session '''||sess.sid || ',' || sess.serial#||''' immediate;'
from v$locked_object lo,
dba_objects ao,
v$session sess
where ao.object_id = lo.object_id and lo.session_id = sess.sid;
13、批量插入多行已知行数的sql
1、 执行行数返回-1,不完美
string sql ="begin "+ string.Format("insert into T_PRE_HE_TEST_OK_QTY t1 (t1.id, t1.line_Code, t1.ok_qty, t1.flag, t1.created_Time, t1.last_updated_time)" +
"values('{0}', '{1}', '{2}', '{3}', to_date('{4}', 'yyyy-MM-dd HH24:mi:ss'),to_date('{5}', 'yyyy-MM-dd HH24:mi:ss')) ", Guid.NewGuid().ToString(), lineCode_191, qty_191, 1, now, now);
sql = sql + " ;" + string.Format("insert into T_PRE_HE_TEST_OK_QTY t1 (t1.id, t1.line_Code, t1.ok_qty, t1.flag, t1.created_Time, t1.last_updated_time)" +
"values('{0}', '{1}', '{2}', '{3}', to_date('{4}', 'yyyy-MM-dd HH24:mi:ss'),to_date('{5}', 'yyyy-MM-dd HH24:mi:ss')) ", Guid.NewGuid().ToString(), lineCode_192, qty_192, 1, now, now);
sql = sql + " ;" + string.Format("insert into T_PRE_HE_TEST_OK_QTY t1 (t1.id, t1.line_Code, t1.ok_qty, t1.flag, t1.created_Time, t1.last_updated_time)" +
"values('{0}', '{1}', '{2}', '{3}', to_date('{4}', 'yyyy-MM-dd HH24:mi:ss'),to_date('{5}', 'yyyy-MM-dd HH24:mi:ss')) ", Guid.NewGuid().ToString(), lineCode_193, qty_193, 1, now, now);
sql = sql + " ; " + "end;";
begin
insert into table1 t1 (t1.id, t1.line_Code, t1.ok_qty, t1.flag, t1.created_Time, t1.last_updated_time)
values ('0fd728b4-1f51-4b2d-9031-593a01804f45', '19Q-ZZ-191', '12', '1',
to_date('2023-03-16 19:10:10', 'yyyy-MM-dd HH24:mi:ss'),
to_date('2023-03-16 19:10:10', 'yyyy-MM-dd HH24:mi:ss'));
insert into table1 t1 (t1.id, t1.line_Code, t1.ok_qty, t1.flag, t1.created_Time, t1.last_updated_time)
values ('613b54c9-eec5-4fd7-80a4-2ecfde8fbdc7', '19Q-ZZ-192', '222', '1',
to_date('2023-03-16 19:10:10', 'yyyy-MM-dd HH24:mi:ss'),
to_date('2023-03-16 19:10:10', 'yyyy-MM-dd HH24:mi:ss'));
insert into table1 t1 (t1.id, t1.line_Code, t1.ok_qty, t1.flag, t1.created_Time, t1.last_updated_time)
values ('fbc9040b-2f45-4f68-ae6a-ee8db13828a9', '19Q-ZZ-193', '11', '1',
to_date('2023-03-16 19:10:10', 'yyyy-MM-dd HH24:mi:ss'),
to_date('2023-03-16 19:10:10', 'yyyy-MM-dd HH24:mi:ss'));
end;
2、执行行数返回正确
string sql =string.Format("insert all into table1 (id, line_Code, ok_qty, flag, created_Time, last_updated_time) " +
"values('{0}', '{1}', '{2}', '{3}', to_date('{4}', 'yyyy-MM-dd HH24:mi:ss'),to_date('{5}', 'yyyy-MM-dd HH24:mi:ss')) ", Guid.NewGuid().ToString(), lineCode_191, qty_191, 1, now, now);
sql = sql + string.Format(" into table1 (id, line_Code, ok_qty, flag, created_Time, last_updated_time)" +
"values('{0}', '{1}', '{2}', '{3}', to_date('{4}', 'yyyy-MM-dd HH24:mi:ss'),to_date('{5}', 'yyyy-MM-dd HH24:mi:ss')) ", Guid.NewGuid().ToString(), lineCode_192, qty_192, 1, now, now);
sql = sql + string.Format(" into table1 (id, line_Code, ok_qty, flag, created_Time, last_updated_time)" +
"values('{0}', '{1}', '{2}', '{3}', to_date('{4}', 'yyyy-MM-dd HH24:mi:ss'),to_date('{5}', 'yyyy-MM-dd HH24:mi:ss')) ", Guid.NewGuid().ToString(), lineCode_193, qty_193, 1, now, now);
sql += " select 1 from dual";
insert all into table1 (id, line_Code, ok_qty, flag, created_Time, last_updated_time)
values ('01c334c4-1bfa-4183-afd1-9fc2d71a0e0b', '19Q-ZZ-191', '1222', '1',
to_date('2023-03-16 19:17:18', 'yyyy-MM-dd HH24:mi:ss'),
to_date('2023-03-16 19:17:18', 'yyyy-MM-dd HH24:mi:ss'))
into table1 (id, line_Code, ok_qty, flag, created_Time, last_updated_time)
values ('dac5d0d5-2ba7-4c0e-af87-8657e42b9581', '19Q-ZZ-192', '111', '1',
to_date('2023-03-16 19:17:18', 'yyyy-MM-dd HH24:mi:ss'),
to_date('2023-03-16 19:17:18', 'yyyy-MM-dd HH24:mi:ss'))
into table1 (id, line_Code, ok_qty, flag, created_Time, last_updated_time)
values ('2695136c-2d9c-45c6-92a2-79202bd373ea', '19Q-ZZ-193', '11', '1',
to_date('2023-03-16 19:17:18', 'yyyy-MM-dd HH24:mi:ss'),
to_date('2023-03-16 19:17:18', 'yyyy-MM-dd HH24:mi:ss'))
select 1 from dual
14、在分区表的分区字段创建索引可能会导致查询出错,解决方法是删除索引。
15、读取数据库的blob的方法
1)通过substr不断的截取blob字段,注意截取后的邠可能会出现重复,因此最好检查每一段的结尾是否是整个blob的结尾
注意:
(1)如果每一段中含有多个逗号,因以大括号开始,小括号结尾,否则读出到csv文件会自动按照逗号分成多个值
(2)ABCD主要是用于后面程序识别并处理方便
concat(concat('{ABCD',substr(t1.REQUEST_PARAMETER,0,4000)),'ABCD}') A1,
concat(concat('{ABCD',substr(t1.REQUEST_PARAMETER,4001,8000)),'ABCD}') A2,
concat(concat('{ABCD',substr(t1.REQUEST_PARAMETER,8001,12000)),'ABCD}') A3,
concat(concat('{ABCD',substr(t1.REQUEST_PARAMETER,12001,16000)),'ABCD}') A4,
2)从数据库导出为csv文件
3)程序读取csv文件,同时处理csv文件恢复原来的样子
还可以通过数据库读取
16、使用DDL语句给现有表增加字段
ALTER TABLE A ADD EDIT_TIMESTAMP TIMESTAMP; --新增字段
ALTER TABLE A MODIFY EDIT_TIMESTAMP DEFAULT CURRENT_TIMESTAMP; --添加默认值
comment on column A.EDIT_TIMESTAMP is '时间' --增加注释
17、常用的sql语句
- 将t2表的字段C更新到t1表的B列中
update t1 set B = (select C from t2 where t1.A = t2.A);
- 根据t1表中的值将t2表中的某些值减去一个固定值
update t2 set t2.B=t2.b-8 where t2.a in (select t1.a from t1)
- 根据学号更新表中成绩等级
update 成绩 t1
set grade=(
select grade
from (select cNo,
case
when score >= 90 then '优秀'
when score >= 80 then '良好'
when score >= 70 then '中等'
when score >= 60 then '及格'
else '不及格' end grade
from 成绩) t2
where t1.cNO = t2.cNo
)
- T1表中有a,b,c三个字段,T2表中有a,b,c三个字段,找到T1中C和T2中C相同的值,然后用T2中的a、b更新T1中的a、b字段
update t1
set a=(select a from t2 where t1.c = t2.c),
b=(select b from t2 where t1.c = t2.c)
where t1.c in (select c from t1)
- 列转行
select t1."product_Name",sum(decode (t1.MONTH,1,t1.QTY,0)) 一季度,
sum(decode (t1.MONTH,2,t1.QTY,0)) 二季度,
sum(decode (t1.MONTH,3,t1.QTY,0)) 三季度,
sum(decode (t1.MONTH,4,t1.QTY,0)) 四季度
from "Product_Sale" t1 group by t1."product_Name"
- 行转列
在Oracle中,行转列通常指的是将行数据转化为列数据,这种操作在数据库中称为透视(pivot)。在Oracle 11g及以上版本中,可以使用PIVOT操作来实现行转列的转换。
以下是一个基本的PIVOT用法示例:
假设你有一个名为sales的表,其结构如下:
year | product | amount
-----|---------|-------
2018 | A | 100
2018 | B | 150
2019 | A | 200
2019 | B | 240
你想要按年份将产品的销售额转换成列,即将product行转为列,可以使用以下SQL语句:
SELECT *
FROM (
SELECT year, product, amount
FROM sales
)
PIVOT (
SUM(amount)
FOR product IN ('A' AS product_a, 'B' AS product_b)
);
结果将是这样的:
year | product_a | product_b
-----|-----------|----------
2018 | 100 | 150
2019 | 200 | 240
在这个PIVOT子句中,SUM(amount)是要在转换后的列上执行的聚合函数,FOR product IN定义了要转换成列的行值,以及这些列的新名称。
如果你想对多个值进行行转列,可以在IN子句中包含更多的值:
FOR product IN ('A' AS product_a, 'B' AS product_b, 'C' AS product_c)
这样就会为产品A、B和C都生成相应的列。
如果你的版本低于Oracle 11g,或者你希望执行更复杂的行转列操作,可能需要使用DECODE或CASE语句与聚合函数结合来模拟PIVOT功能。这通常涉及到一些比PIVOT操作更复杂的SQL编写。
-
union 里面不能使用order by。
least 取所有值的最小值,greatest 取所有值的最大值 -
coalesce的使用
--当success_cnt不为null,那么无论period是否为null,都将返回success_cnt的真实值(因为success_cnt是第一个参数),当success_cnt为null,而period不为null的时候,返回period的真实值。只有当success_cnt和period均为null的时候,将返回1
select coalesce(success_cnt,period,1) from tableA
- 查询每个表有多少列?
select t.TABLE_NAME ,count(t.COLUMN_NAME) from user_tab_columns t group by t.TABLE_NAME;
- 排序
row_number 序号不重复,1,2,3,4
rank 序号可以重复,数字不连续,1,2,2,4
dense_rank 序号可以重复,数字连续,1,2,2,3
-- dense_rank 排序,1,2,2,3,根据order by的字段排序,字段相同,则序号相同,后面的序号连续
select t1.id ,t1.SALARY, dense_rank() over (order by t1.SALARY desc) from EMPLOYEE t1 ;
-- rank 排序,1,2,2,4,根据order by的字段排序,字段相同,则序号相同,但是后面的序号不连续
select t1.id ,t1.SALARY, rank() over (order by t1.SALARY ) from EMPLOYEE t1 ;
-- row_number排序,1,2,3,4,根据order by的字段排序,字段相同,则序号不同同,但是后面的序号连续
select t1.id ,t1.SALARY, row_number() over( order by t1.SALARY desc)from EMPLOYEE t1 ;
- 查询数据库表的结构
select t1.TABLE_NAME 表名,t2.COLUMN_NAME 列名,t3.DATA_TYPE 数据类型,t3.DATA_LENGTH 数据长度,t3.NULLABLE 是否为空, t2.COMMENTS 注释
from user_tables t1 LEFT join USER_COL_COMMENTS t2 on t1.TABLE_NAME=t2.TABLE_NAME
LEFT join USER_TAB_COLS t3 on t2.COLUMN_NAME=t3.COLUMN_NAME and t2.TABLE_NAME=t3.TABLE_NAME
where t1.TABLE_NAME='T_STATUS_TEMP';
- 判断是否是数值
-- 判断是否是数值
select case when regexp_like(trim('123.24'),'^([\-]?[0-9]+\.[0-9]+)$|^([\-]?[0-9])+$|^([\-]?[0-9]{1}\.[0-9]+E[\-]?[0-9])+$') then round('123.24',1) else 0 end from DUAL;
- translate
SELECT TRANSLATE('Hello World', 'H', 'Jw') FROM dual; --输出 Jello World
SELECT TRANSLATE('Hello World', '12', 'Jt') FROM dual; --输出 Hello World
SELECT TRANSLATE('Hello World', 'HW', 'J1') FROM dual; --输出 Jello 1orld
- 排序时,排序字段值包含null
-- CREATED_TIME 降序排列,如果CREATED_TIME有null,则把null的排到前面
select * from table1 t order by t.CREATED_TIME desc nulls first ;
-- CREATED_TIME 降序排列,如果CREATED_TIME有null,则把null的排到后面
select * from table1 t order by t.CREATED_TIME desc nulls last;
- 排序–当满足A条件时,以B字段排序;当满足C条件时,以D字段排序;(注意B和D的字段类型应该一致)
select t.ID, CONTAINER_NAME, PID, CREATED_TIME, EDIT_TIMESTAMP, case when t.CREATED_TIME is null then t.ID else t.pid end iddd from table1 t
order by iddd;
- 查看数据库的DBlink以及使用
--查看DBlink名
SELECT t.OWNER 当前用户,t.DB_LINK DBlink名,t.USERNAME 需要连接的数据库用户名,t.HOST 需要连接的数据库信息 FROM ALL_DB_LINKS t;
--使用DBLink
select* from table1 @ DBlink名;
- 将查询返回的行插入多张表中,
insert all
when loc ='A' then insert into A(a,b,c) values(a,b,c)
when loc ='B' then insert into B(a,b,c) values(a,b,c)
else loc ='C' then insert into C(a,b,c) values(a,b,c)
select a,b,c from D
注意:insert all 和insert first 的区别
insert first 在遇到满足的条件时会结束when-then-else检查,但是insert all 会检查所有的条件,即便已经遇到了满足的条件。因此可以使用insert all将相同的数据插入多张表中
- 跳过多少行,查询后面的多少行
-- 在Oracle 12c及更高版本中,你还可以使用`FETCH FIRST`子句进行分页:这个查询会跳过前10行数据,然后返回接下来的10行。`OFFSET`关键字用于指定要跳过的行数,`FETCH NEXT`则用于指定要返回的行数。
SELECT *
FROM your_table
ORDER BY some_column
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
以下是使用ROWNUM的示例,返回第11到20行的数据:
SELECT *
FROM (SELECT t.*, ROWNUM rn
FROM (SELECT *
FROM your_table
ORDER BY some_column) t
WHERE ROWNUM <= 20)
WHERE rn > 10;
- 取出第一行的数据
1) 使用rownum 字段(注意:rownum前面不能加表名)
SELECT *
FROM (
SELECT t1.*
FROM table t1
ORDER BY t1.CREATED_TIME DESC
)
WHERE ROWNUM = 1;
2) 在Oracle 12c及以后的版本中,可以使用FETCH FIRST语法来简化这个操作
select *
from table t1
order by t1.CREATED_TIME desc FETCH FIRST 1 ROWS ONLY;
- oracle有没有方法可以一次查询出所有表的表名、字段、中文注释
SELECT
at.table_name,
atc.column_name,
acc.comments
FROM
all_tab_columns atc
JOIN all_col_comments acc ON atc.table_name = acc.table_name AND atc.column_name = acc.column_name
JOIN all_tables at ON atc.table_name = at.table_name
WHERE
atc.owner = '' -- 这里需要替换为实际的schema名
and at.table_name='' -- 这里是表名
ORDER BY
at.table_name,
atc.column_id;
- with as 嵌套
WITH CTE1 AS (
SELECT * FROM Table1
),
CTE2 AS (
SELECT * FROM CTE1 WHERE Column1 > 100
),
CTE3 AS (
SELECT * FROM CTE2 WHERE Column2 < 50
)
SELECT * FROM CTE3;
18 sqlplus 登录oracle数据库
cmd命令登录
sqlplus username/password@ip:port/sid -- 全称
19 查询表占用空间大小
- 查询每张表占用空间
select *
from (select t.SEGMENT_NAME, round(sum(bytes) / 1024 / 1024 / 1024, 4) GB
from user_segments t where segment_type = 'TABLE'
group by t.SEGMENT_NAME )
order by gb desc;
- 查询所有表占用空间
select round(sum(bytes) / 1024 / 1024 / 1024, 4) GB
from user_segments
where segment_type = 'TABLE';
















 1255
1255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









