









之前讲过(这里),当Scrapy正常运行时,下载器是瓶颈。在这种情况下,你会看到调度器中有一些请求,下载器中的并发请求数目已经达到最大值,而scraper(爬虫和pipeline)的负载比较轻,正在处理的Response对象数目也不会一直增长。
主要有三个设置项来控制下载器的容量:CONCURRENT_REQUESTS,CONCURRENT_REQUESTS_PER_DOMAIN和
CONCURRENT_REQUESTS_PER_IP。第一个设置项提供了一个粗略的控制,无论如何不会有超过CONCURRENT_REQUESTS数目的请求被并发下载。在另一方面,如果你的目标域名只是一个或者少数的几个,那么CONCURRENT_REQUESTS_PER_DOMAIN可能就会提供对并发请求数目的更进一步的限制。不过如果你设置了CONCURRENT_REQUESTS_PER_IP,那么CONCURRENT_REQUESTS_PER_DOMAIN就会被忽略,这时的限制会是针对每个IP的。在很多域名都反射一个服务器的时候,这会帮你避免过度地访问远程服务器。
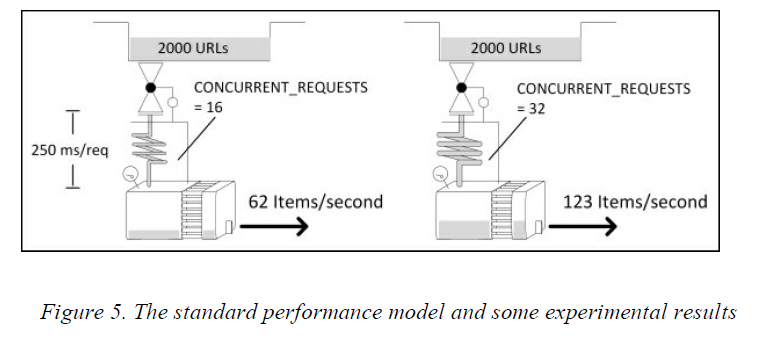
为了使我们的分析工作简单一点,我们把CONCURRENT_REQUESTS_PER_IP保持为默认值(0),这样就禁用了对每个IP的限制,并且把CONCURRENT_REQUESTS_PER_DOMAIN设置成一个很大的值(1000000) 。这样的设置实际上就是禁用了这些限制,这样下载器的并发请求数目就只由CONCURRENT_REQUESTS来控制了。
我们希望系统的吞吐量决定于它下载一个页面所花费的平均时间,包括远程服务器响应的时间和我们自己的系统(Linux,Twisted/Python)的延迟时间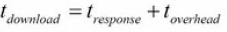
Response对象的时间与它的Item从pipeline中处理完毕的时间之差,以及程序启动后到得到第一个Response对象之间的延迟。
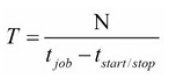
总的来说,如果你需要完成一个共有N个请求的作业,并且爬虫已经被调整好了,那么程序就可能在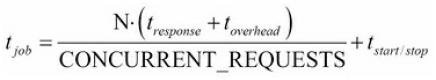
对于上面公式的大多数参数我们都没法控制它们,我们可能通过使用一个性能比较好的服务器来稍稍控制一下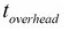
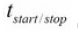
CONCURRENT_REQUESTS的值,这个主要取决于我们要多频繁地访问远程服务器。如果我们把它设置成一个很大的值,那么在某个时候,我们的服务器的CPU和远程服务器的承受能力都会达到一个饱和状态,也就是说,那个时候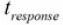
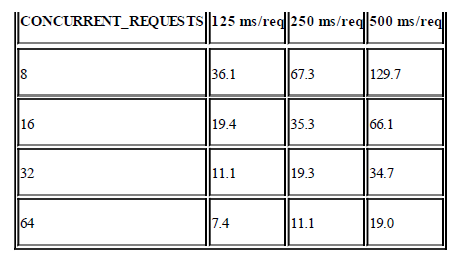
下面运行一个实验。我们分别使用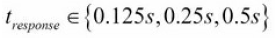
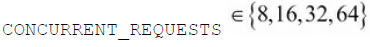
$ for delay in 0.125 0.25 0.50; do for concurrent in 8 16 32 64; do
time scrapy crawl speed -s SPEED_TOTAL_ITEMS=2000 -s CONCURRENT_REQUESTS=$concurrent -s SPEED_T_RESPONSE=$delay
done; done下面是结果:
组织一下上面的那个方程,可以得到一个简单的形式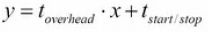
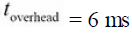
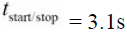
















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









