







3 使用Unicode进行文字处理
Text Processing with Unicode
1 what is unicode
每个文本都有其特定的编码,例如GB2312,而在程序中操控的是unicode字符串,在文件或终端显示的内容都是有其特定编码的。
翻译成unicode的过程叫解码,unicode转化为其他编码的过程叫编码。

2 Extracting encoded text from files
path = nltk.data.find('corpora/unicode_samples/polish-lat2.txt')
此函数可以找到某个已知文件名的文件路径。
file = open(path, encoding='latin2')
open函数可以读取文件中已经编码的数据为unicode字符串,encoding指定读取或写入的文件的编码。
num = ord('ń')
nacute = hex(num)
若使用的idle或其他的编辑器支持unicode,可以在字符串中加入unicode字符。
用ord()函数查找某个字符的整数序列,再利用hex()函数可找到该整数序列的十六进制的形式。
str = '\u0144o'
print(str)
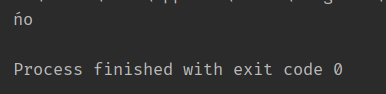
在利用上述方法得到 ‘ń’ 的十六进制。那么利用转义字符就可以定义出一个带有unicode字符的字符串。输出结果如上图。
3 Regular Expressions for Detecting Word Patterns
使用正则表达式首先需要导入re库。使用re.search(模式,字符串)
正则表达式中有几个需要注意的字符:
$ 表示匹配末尾 . 表示通配符 ^ 表示匹配开始
?表示前边字符可出现0/1次
+表示前边的内容可出现1+次
*表示前边的内容可出现0+次
{}可指定前边内容的重复次数 |表示或
()表示一个操作符的范围
4 Normalizing Text
nltk中包括可以使用的词干提取器(porter、lancaster)。这些词干提取器按照自己的规则剥离词缀,能处理的不规则情况广泛。
词干提取器用于索引文本和使搜索支持不同词汇形式,在词干提取没有特殊要求下,porter是个很好的选择。
wordNet词形归并器用于编译一些文本词汇或获取一个有效词条或中心词的列表
5 Regular Expressions for Tokenizing Text
正则表达式的符号:

使用正则表达式分词后,可用set(tokens).difference(wordlist)来评估一个分词器。其中wordlist作为一个词表相当于一个标准。该方法的结果是报告任何没有在词表中出现的标识符。
6 Segmentation
6.1 断句
分词之前要先完成断句。nltk中包含punkt句子分割器,可以用于断句。
断句方法1,
text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt')
sents = nltk.sent_tokenize(text)
6.2 分词
分词:找到将文本字符串正确分割成词汇的字位串。
因此我们需要定义一个目标函数、一个打分函数。基于词典的大小和从词典中重构源文本所需的信息量尽力优化其值。
计算目标函数:
# 合计每个词项与推导表的字符数;计算存储字典和重构源文本的成本。即计算分词质量得分
def evalute(text, segs):
# 按字位串分词
words = segment(text, segs)
# 分出来的词汇个数
text_size = len(words)
# 每个分出来的词汇,长度加1,然后求和
lexicon_size = sum(len(word) + 1 for word in set(words))
# 返回二者之和,值越小表明分词越好
return text_size + lexicon_size
7 Formatting: From Lists to Strings
当需要把列表转为字符串时,可以使用 join() 方法。join()方法只适用于一个字符串的列表。
示例如下:
silly = ['We', 'called', 'him', 'Tortoise', 'because', 'he', 'taught', 'us', '.']
# glue指定以什么字符串来连接列表中每一个元素内容
glue = ' '
# join 方法只适用于一个字符串的列表
result_1 = glue.join(silly)
print(result_1)
print输出包含变量和常量交替出现的表达式,这是不利于阅读和维护,因此使用字符串格式化表达式。例如:
fdist = nltk.FreqDist(['dog', 'cat', 'dog', 'cat', 'dog', 'snake', 'dog', 'cat'])
for word in sorted(fdist):
print('{}->{};'.format(word, fdist[word]), end=' ')
格式字符串中的替换字段可以以一个数值开始,它表示format()的位置参数。'from {} to {}‘这样的语句等同于’from {0} to {1}’,但是我们使用数字来得到非默认的顺序:
>>> 'from {1} to {0}'.format('A', 'B')
'from B to A'
占位符{}可以有任意个,但format方法中的参数个数只能多不能少,多了的忽略,少了报错。
format()函数还可以起到对齐的作用,例如:
# 指定输出宽度。数字默认右对齐
result_2 = '{:6}'.format(41)
# 加<,使得数字左对齐
result_3 = '{:<6}'.format(41)
# 字符串默认左对齐
result_4 = '{:6}'.format('dog')
# 加>,使得字符串右对齐
result_5 = '{:>6}'.format('dog')














 1913
1913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









