






QHT 投稿
量子位 | 公众号 QbitAI
大模型应用开卷,连一向保守的苹果,都已释放出发展端侧大模型的信号。
问题是,大语言模型(LLM)卓越的表现取决于“力大砖飞”,如何在资源有限的环境中部署大模型并保障性能,仍然颇具挑战。
以对大模型进行量化+LoRA的路线为例,有研究表明,现有方法会导致量化的LLM严重退化,甚至无法从LoRA微调中受益。
为了解决这一问题,来自苏黎世联邦理工学院、北京航空航天大学和字节跳动的研究人员,最新提出了一种信息引导的量化后LLM微调新算法IR-QLoRA。论文已入选ICML 2024 Oral论文。

论文介绍,IR-QLoRA能有效改善量化导致的大模型性能退化。在LLaMA和LLaMA 2系列中,用该方法微调的2位模型,相比于16位模型仅有0.9%的精度差异。
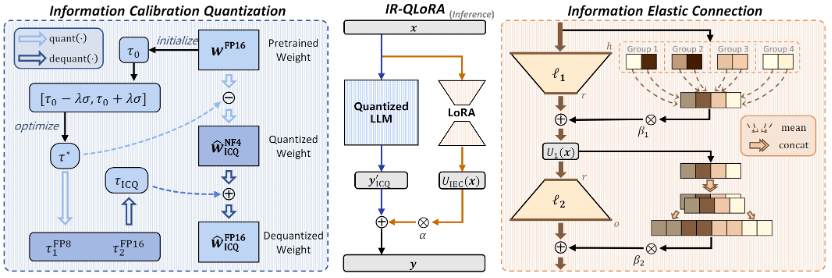
△IR-QLoRA框架图
该方法的核心思想,是通过信息保留来使LoRA微调量化的大语言模型实现精度提升。
包含从统一信息角度衍生的两种技术:信息校准量化和信息弹性连接。
信息校准量化
LLM的量化权重被期望反映原始对应方所携带的信息,但比特宽度的减小严重限制了表示能力。从信息的角度来看,量化LLM和原始LLM的权重之间的相关性表示为互信息。
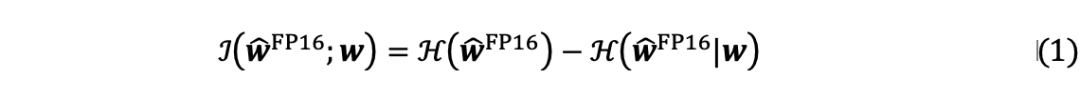
在LLM量化后,由于比特宽度的显著减小导致表示能力的降低,量化权重的熵远小于原始权重的熵。因此,优先考虑低比特权重内的信息恢复对于增强量化LLM至关重要。
首先从数学上定义信息校准的优化目标。校准过程可以看为向量化器引入一个校准常数  以最大化信息,量化过程可以表述如下:
以最大化信息,量化过程可以表述如下:
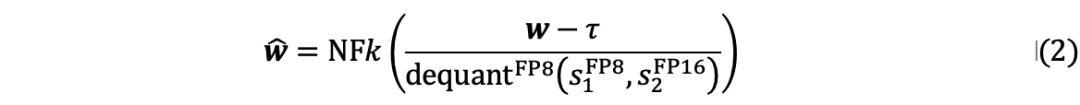
由于原始权重  是固定的,公式(1)中的优化目标可以表示为:
是固定的,公式(1)中的优化目标可以表示为:
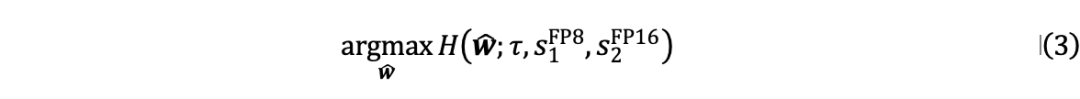
由于直接求解公式(3)中的目标非常耗时,作者提出了一种分块校准量化器信息的两步策略:
第一步是初始化校准常数  。基于神经网络权重正态分布的常见假设,将每个权重量化块的常数初始化为中值
。基于神经网络权重正态分布的常见假设,将每个权重量化块的常数初始化为中值 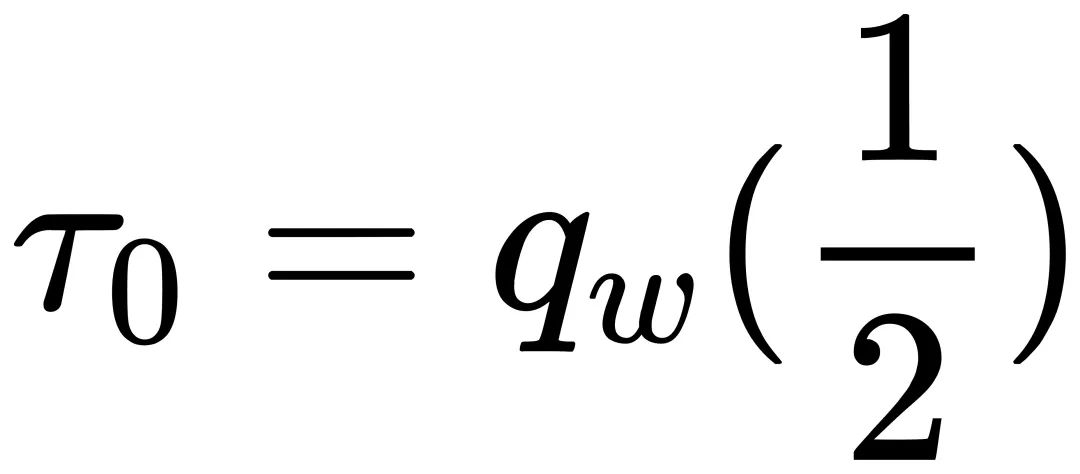 。由于正态分布中靠近对称轴的区域的概率密度较高,因此该初始化旨在更大程度地利用量化器的间隔。应用位置相关中值来初始化
。由于正态分布中靠近对称轴的区域的概率密度较高,因此该初始化旨在更大程度地利用量化器的间隔。应用位置相关中值来初始化  ,以减轻异常值的影响。
,以减轻异常值的影响。
第二步是优化校准常数  、量化尺度
、量化尺度 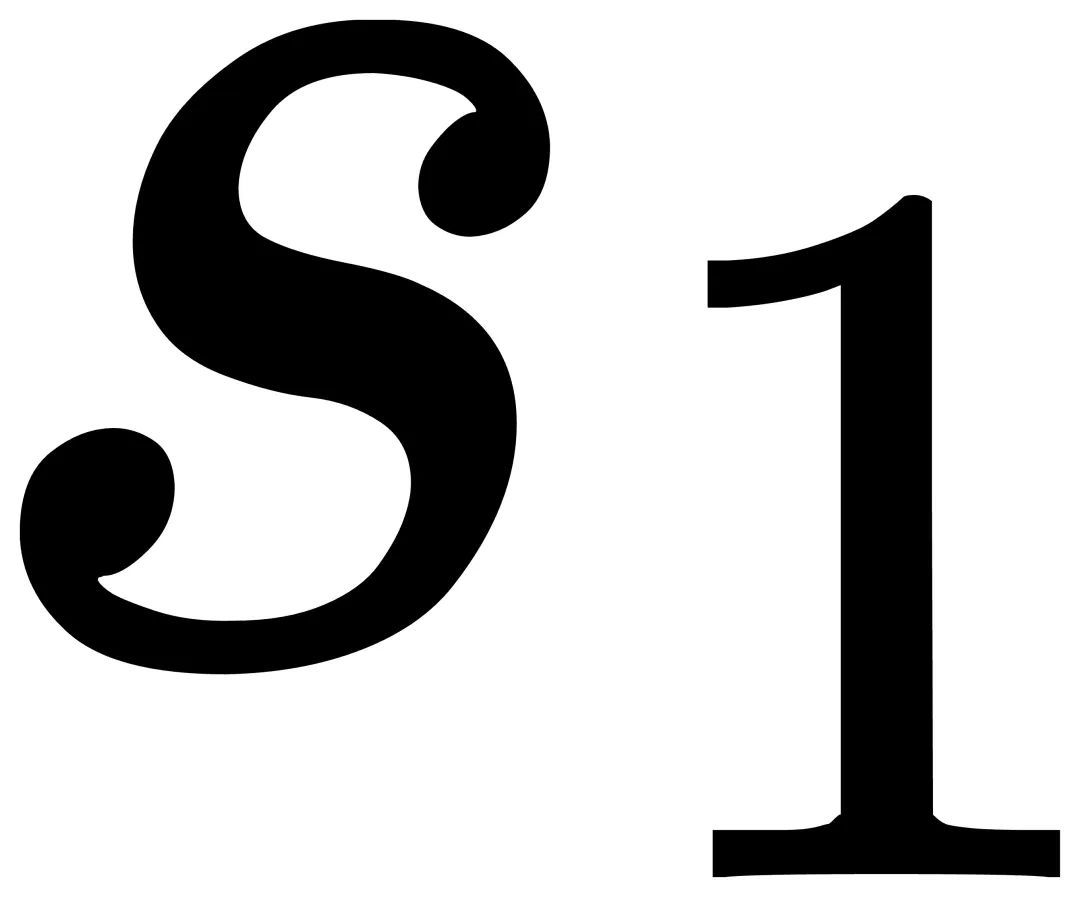 、双量化尺度
、双量化尺度 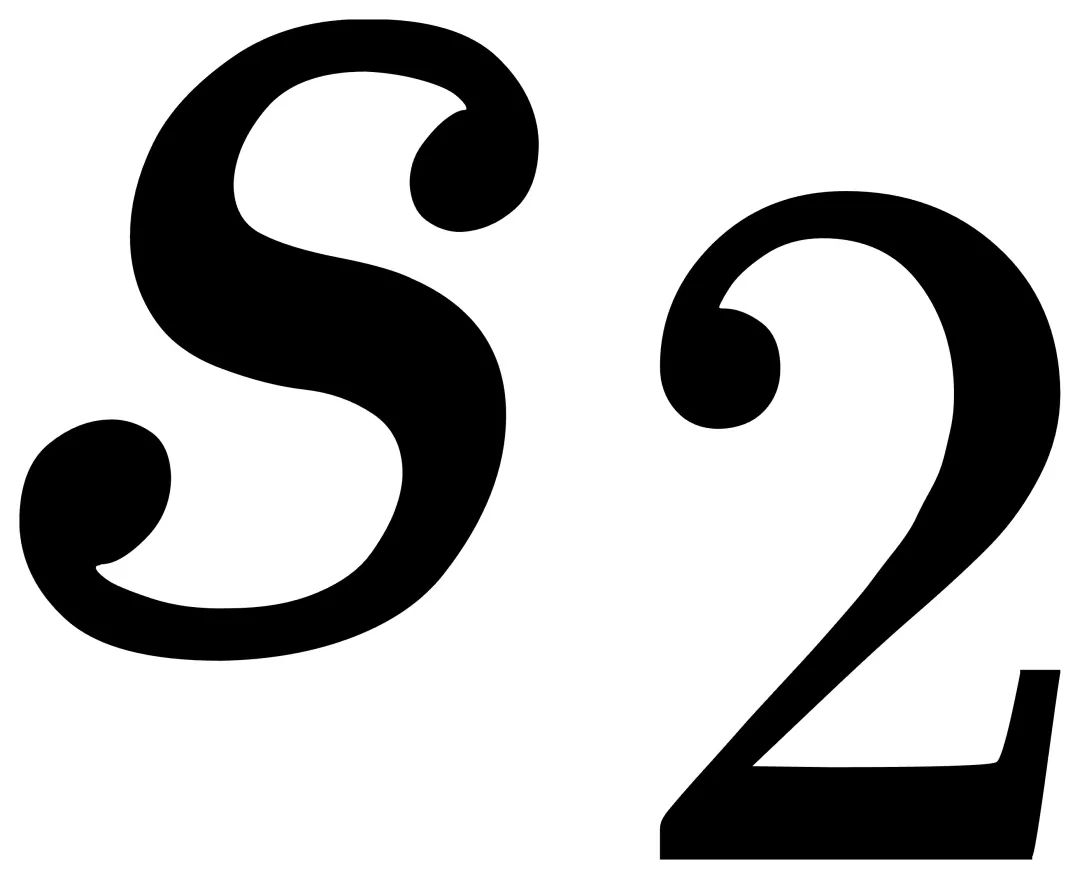 。使用信息熵作为度量,并进行基于搜索的优化以获得
。使用信息熵作为度量,并进行基于搜索的优化以获得  。通过将
。通过将 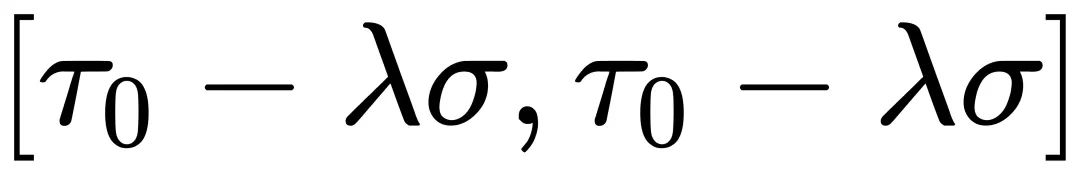 线性划分为n个候选来创建
线性划分为n个候选来创建  的搜索空间,其中
的搜索空间,其中  是标准差,
是标准差,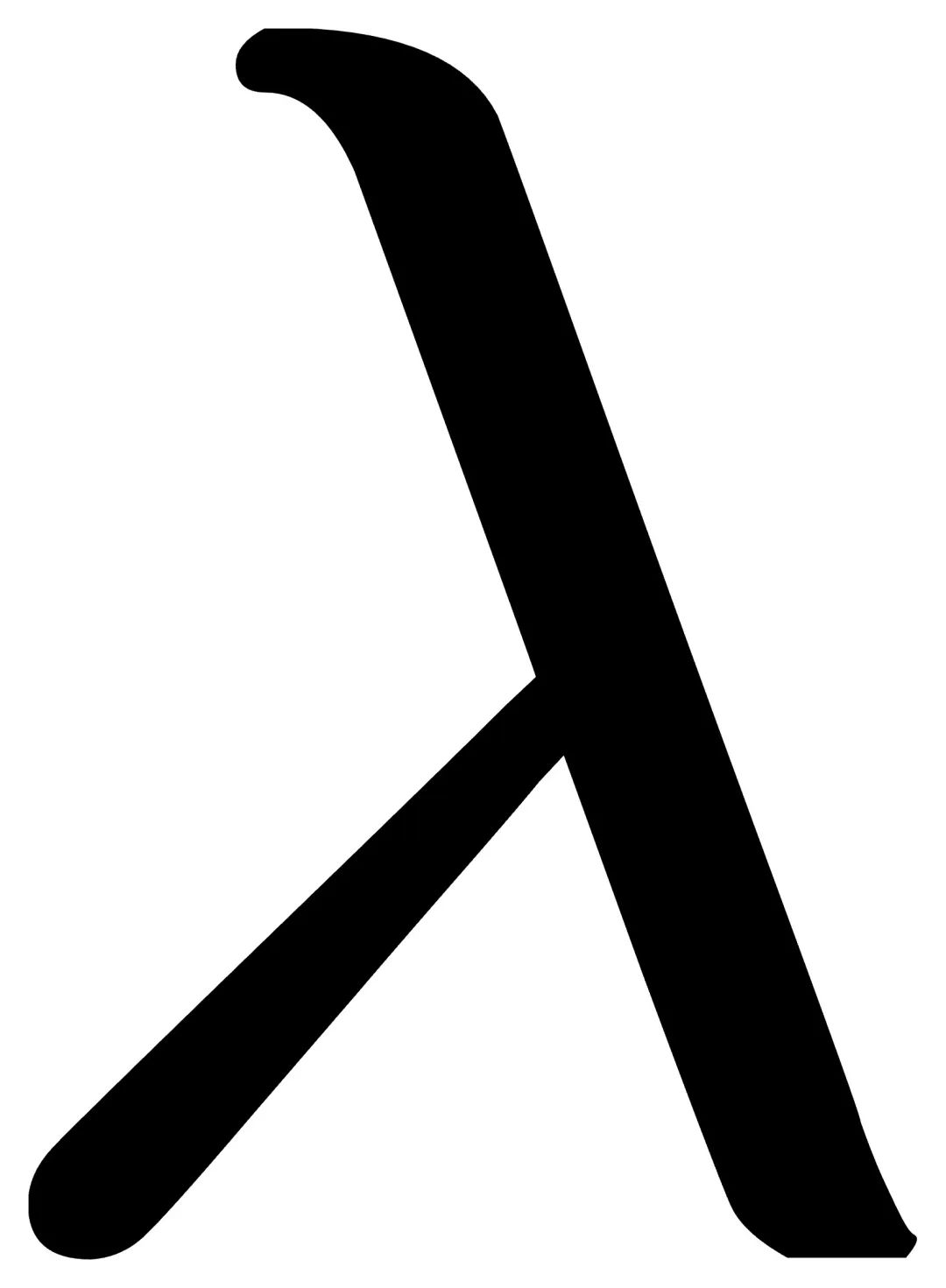 是系数。使用每个候选
是系数。使用每个候选  校准权重后,量化校准的权重并计算信息熵。获得的量化尺度与基线一致。通过
校准权重后,量化校准的权重并计算信息熵。获得的量化尺度与基线一致。通过 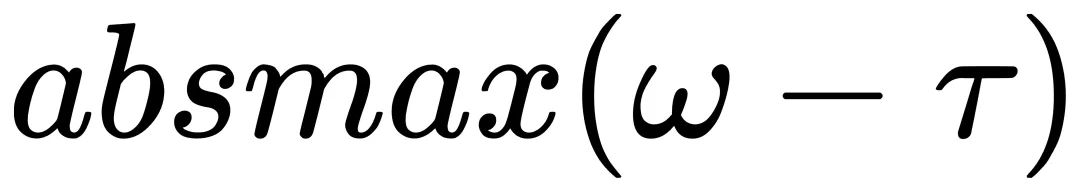 得到量化尺度
得到量化尺度  ,然后二次量化为
,然后二次量化为  和
和  。
。
对于优化后的校准常数 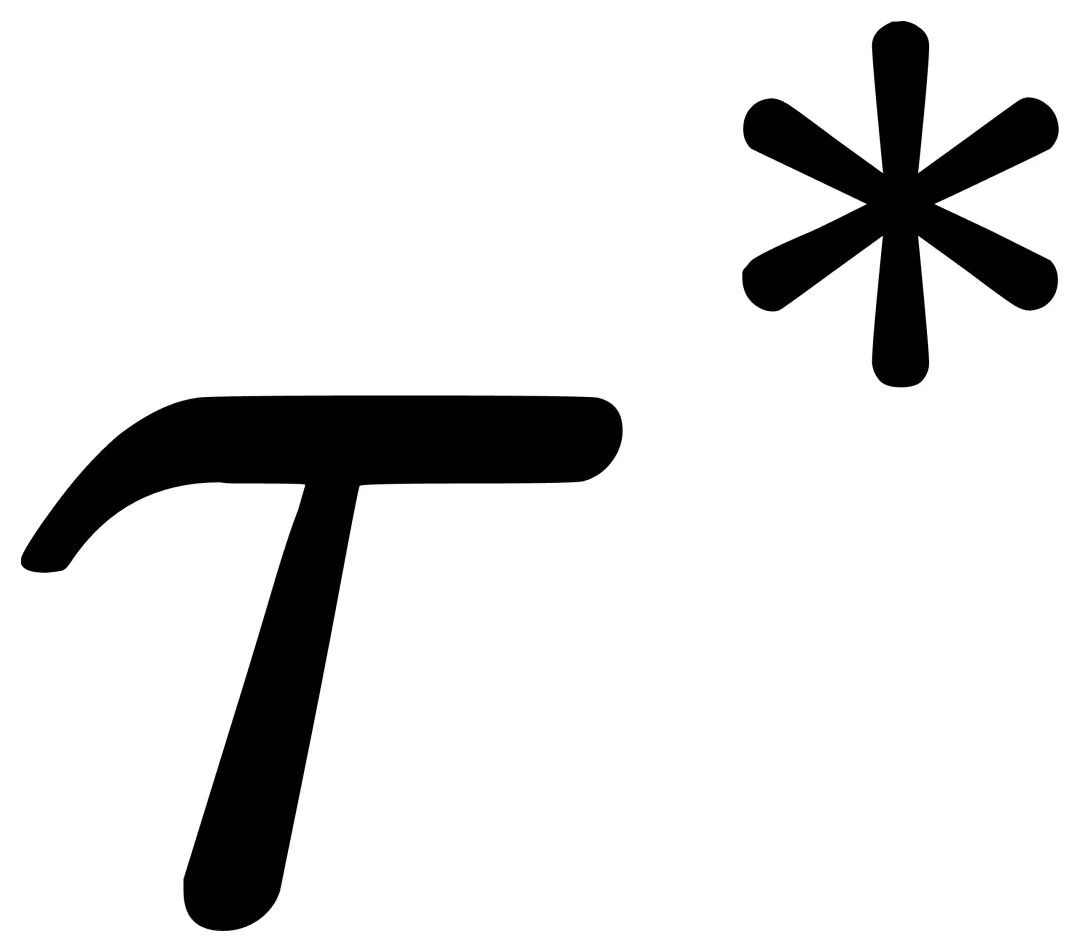 ,执行类似于尺度的双量化以节省内存,信息校准量化的量化过程可以总结为:
,执行类似于尺度的双量化以节省内存,信息校准量化的量化过程可以总结为:
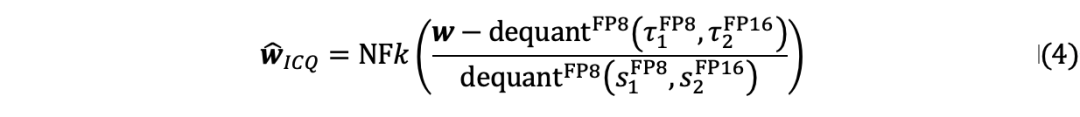
信息弹性连接
除了基线中的量化LLM之外,由低秩矩阵组成的LoRA也阻碍了信息的恢复,为了增强LoRA的表示能力,帮助恢复量化LLM的信息,同时保持其轻量级性质,作者引入了有效的信息弹性连接。该方法构建了一个强大的低秩适配器,有助于利用从量化的LLM单元导出的信息。
具体来说,首先根据输入和中间维度的最大公约数对原始特征进行分组和平均,并将其添加到由 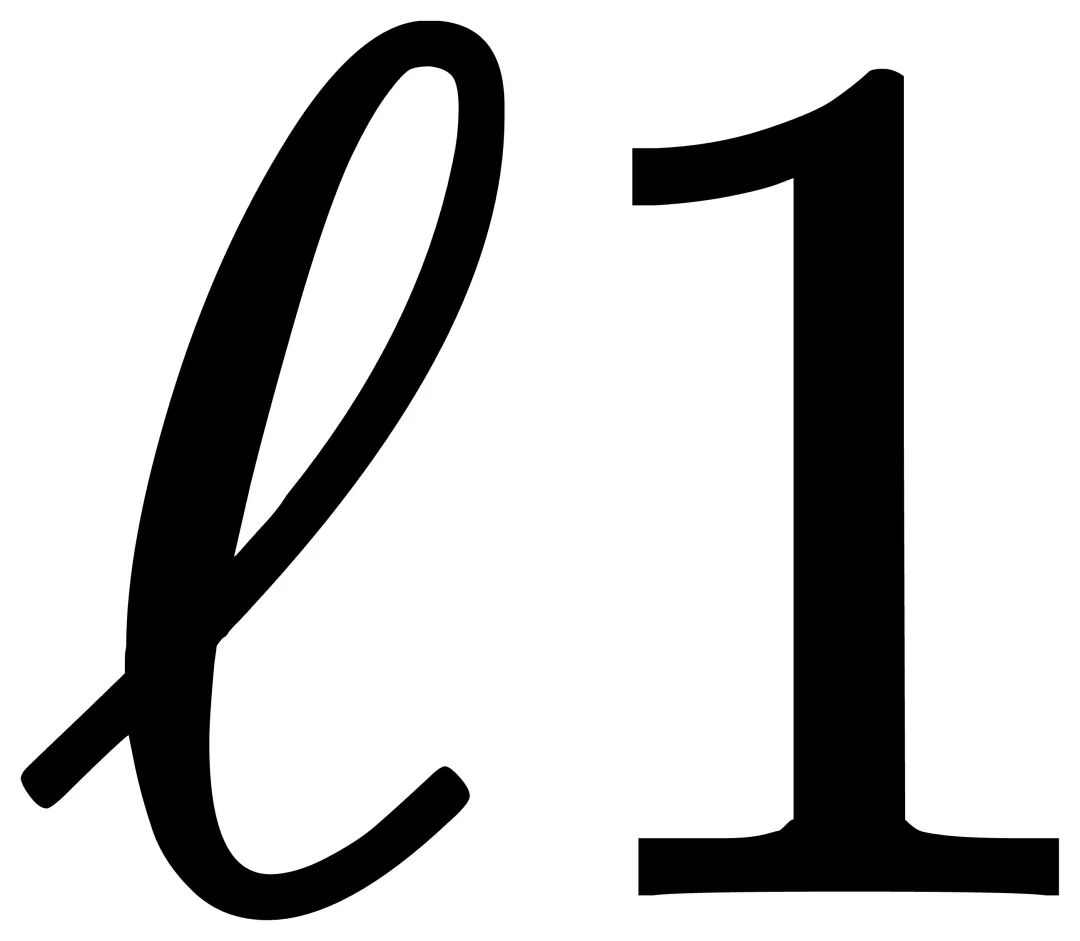 矩阵计算的输出中。增加弹性连接的LoRA的第一个子单元
矩阵计算的输出中。增加弹性连接的LoRA的第一个子单元 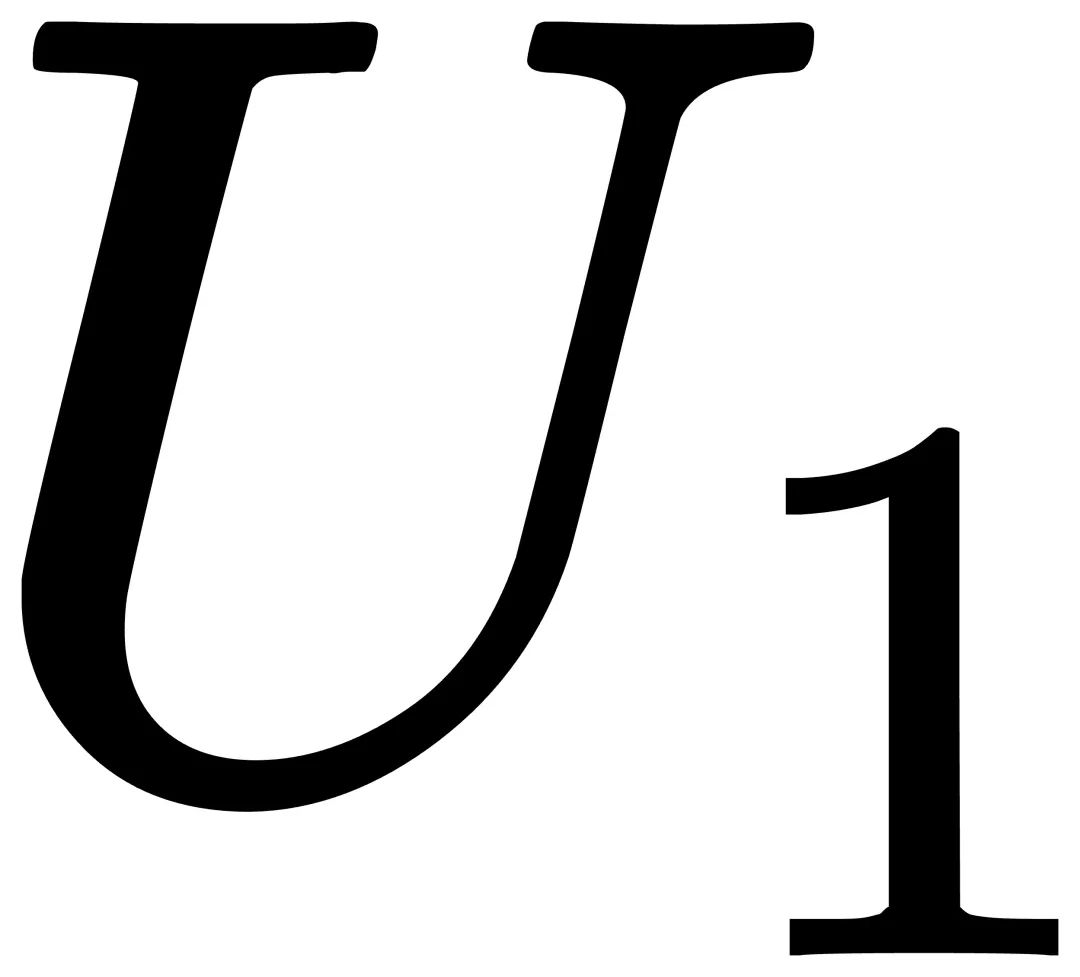 可以表示为:
可以表示为:
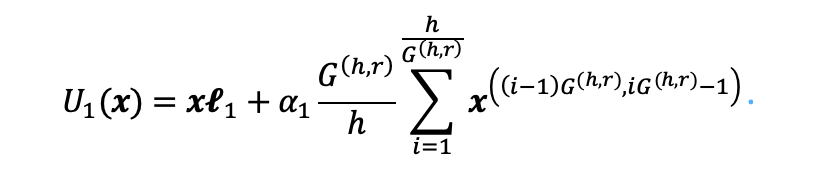
LoRA的后一个矩阵将低秩中间表示变换为输入维度,因此其伴随的无参数变换使用重复串联来增加维度。后一个子单元 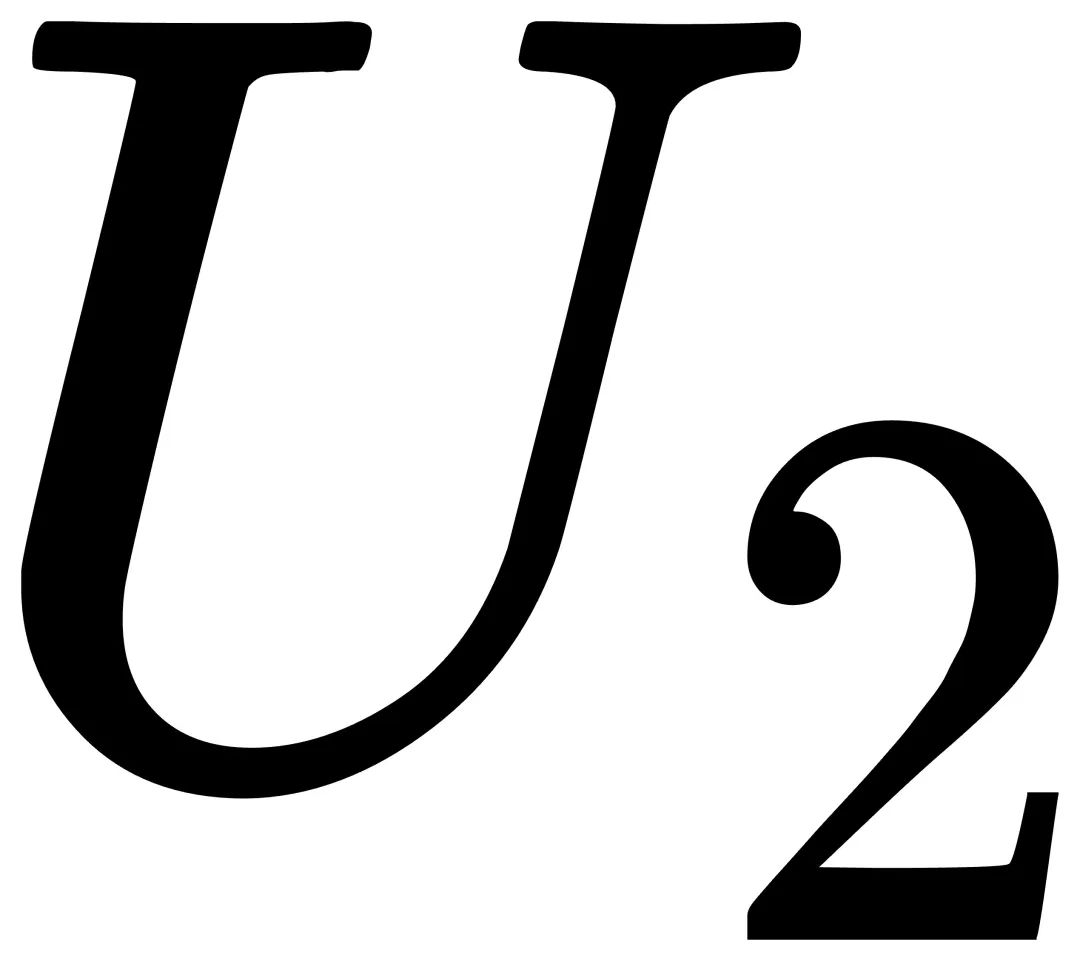 的计算过程可以表示为:
的计算过程可以表示为:
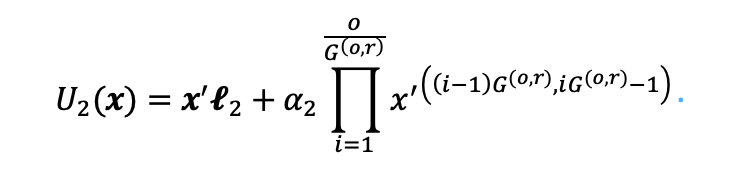
与LLM和LoRA单元中的矩阵乘法相比,无参数变换是一种多样化的变换形式,进一步增强了量化LLM的信息表示。
实验验证
作者广泛评估了IR-QLoRA的准确性和效率。选择LLaMA和LLaMA 2系列模型,在Alpaca和Flanv2数据集上构建参数高效的微调,使用MMLU和CommonsenseQA基准进行评估微调后量化模型的效果。
准确率
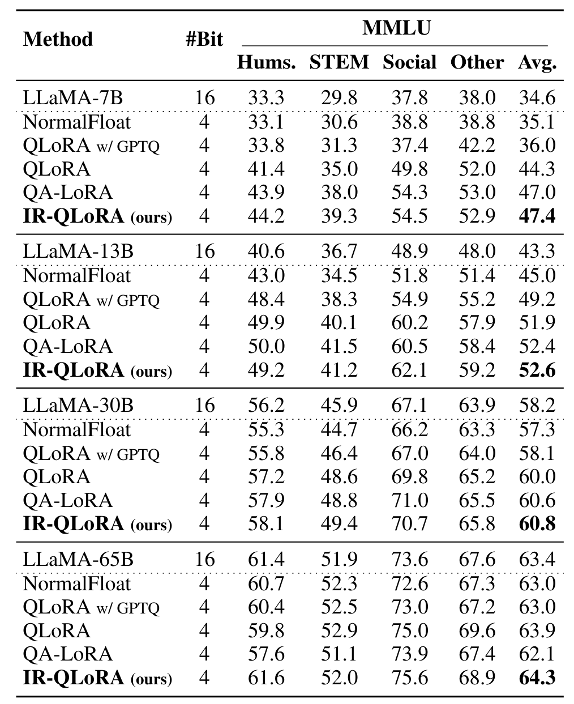
以下两张表格分别展示了在Alpaca和Flanv2数据集上微调的MMLU基准的5-shot精度结果。综合结果表明,在各种规模的LLaMA模型中,IR-QLoRA优于所有比较量化方法。
与基线方法QLoRA相比,IR-QLoRA在相同的微调管道下在MMLU基准上实现了精度的显著提高。
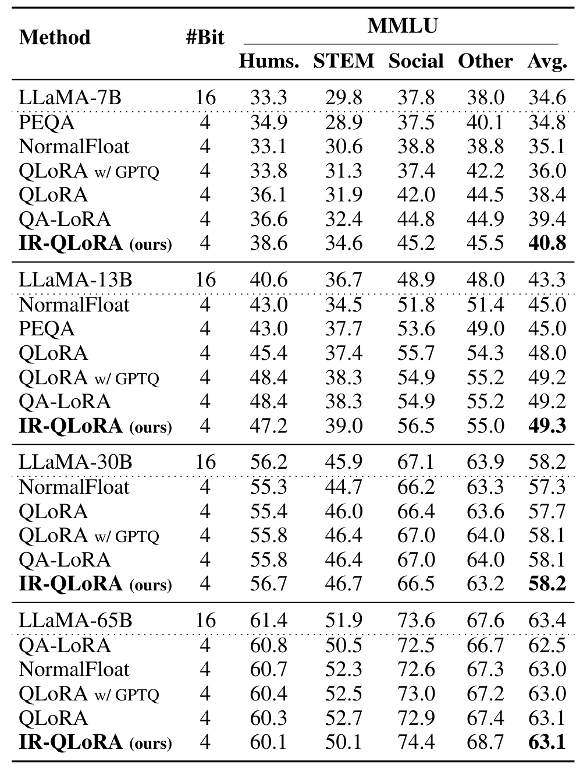
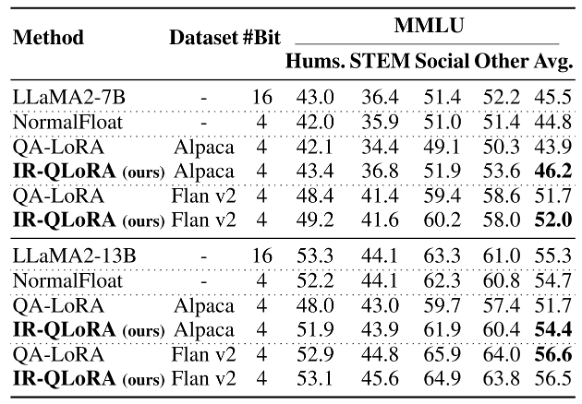
此外,在LLaMA 2上的准确性比较,证明了IR-QLoRA跨LLM系列的泛化性能。
下表中的结果表明,IR-QLoRA不仅平均实现了至少2.7%的性能改进,而且在几乎每个单独的指标上都表现出了优势。这些结果表明IR-QLoRA在不同的LLM系列中表现出很强的泛化性。
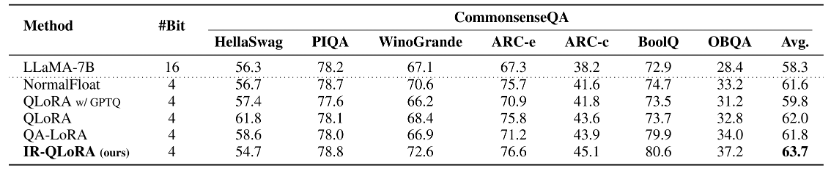
与MMLU基准上的现象类似,在CommonsenseQA基准上,与SOTA方法相比,IR-QLoRA始终保持了LLaMA-7B的最佳平均准确率,而且还显著提高了大多数子项的有效性。
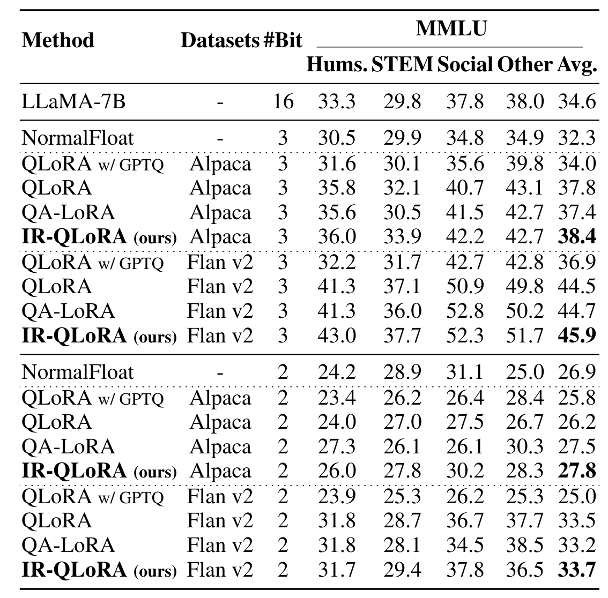
超低位宽
除了4比特以外,作者还评估了超低位宽下的IR-QLoRA建议。
具体来说,作者采用了QLoRA和LoftQ的量化方法,按照百分位量化方法构建了NF2和NF3量化。
下表显示,随着量化位宽的减小,基线QLoRA的性能急剧下降,以至于其在2位情况下的性能与随机相差无几。
相比之下,IR-QLoRA表现出更优越的性能,在Flan v2数据集上微调2位模型时,与16位模型相比仅有0.9%的精度差异。
效率
IR-QLoRA的信息校准量化和信息弹性连接并没有带来额外的存储和训练开销。
如上所示,信息校准量化增加的参数仅相当于量化的缩放因子,而且采用了双重量化以进一步减少存储。因此其带来的额外存储空间很小,在4位LLaMA-7B上仅增加了 2.04%。
校准常数的优化过程也只增加了微不足道的训练时间(例如,LLaMA-7B为 0.46%,LLaMA-13B为 0.31%)。此外,增加的时间仅用于训练过程中的初始优化,并不会导致推理时间的增加。信息弹性连接也只在每层引入了2个额外参数,在整个模型中可以忽略不计。
结论
总的来说,基于统计的信息校准量化可确保LLM的量化参数准确保留原始信息;以及基于微调的信息弹性连接可以使LoRA利用不同信息进行弹性表示转换。
广泛的实验证明,IRQLoRA在LLaMA和LLaMA 2系列中实现了令人信服的精度提升,即使是2-4位宽,耗时也仅增加了0.45%。
IR-QLoRA具有显著的多功能性,可与各种量化框架无缝集成,并且大大提高了LLM的LoRA-finetuning量化精度,有助于在资源受限的情况下进行实际部署。
论文地址:https://arxiv.org/pdf/2402.05445
代码地址:https://github.com/htqin/IR-QLoRA


















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









