







梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI突然发布新模型!基于GPT-4训练,可以帮助下一代GPT训练。
CriticGPT,用于给代码挑Bug时能找到75%以上,而相比之下人类只能找到不到25%。
它还可以给Bug写“锐评”,在60%的情况下人类训练师更喜欢有CriticGPT帮助下的批评。
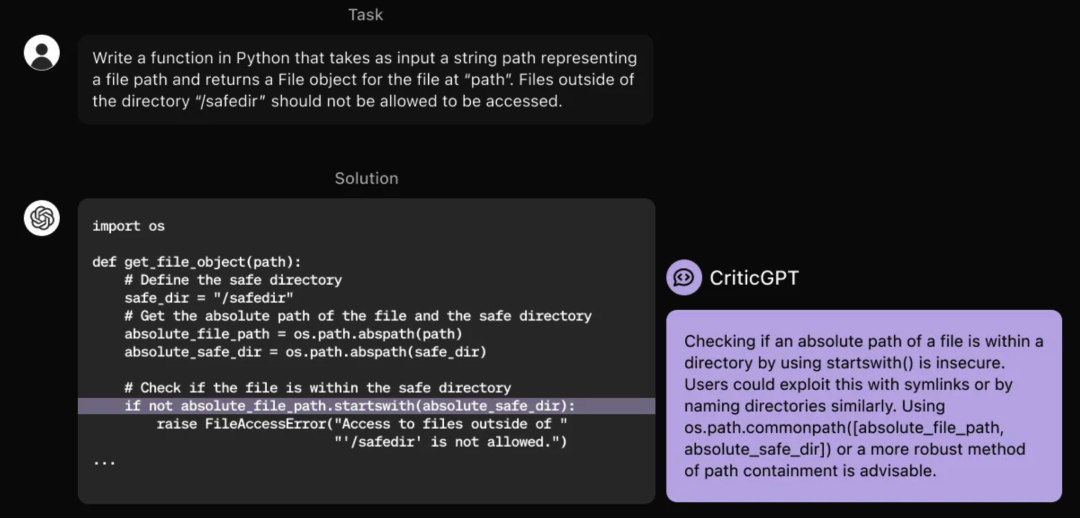
有网友开玩笑说,“只会批评的GPT,这不是我前妻么”。

但这项研究最重要之处在于,CriticGPT挑错能力可以泛化到代码之外。
比如在RLHF训练中给AI的输出挑错,而且已经进入OpenAI内部训练流程。

更好的RLHF就能训练出更强的模型,更强的模型又能通过更好地挑错来增强RLHF训练……
论文结论中赫然写道:在真实世界数据中挑错误上,AI还可以继续进步,人类智能已经到头了。

左脚踩右脚上天,难道真的被这帮人给搞出来了?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9
9

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









