






一水 发自 凹非寺
量子位 | 公众号 QbitAI
起猛了,GPT-4o被谷歌新模型超越了!
历时一周,超1,2000人匿名投票,Gemini 1.5 Pro(0801)代表谷歌首次夺得lmsys竞技场第一。(中文任务也第一)
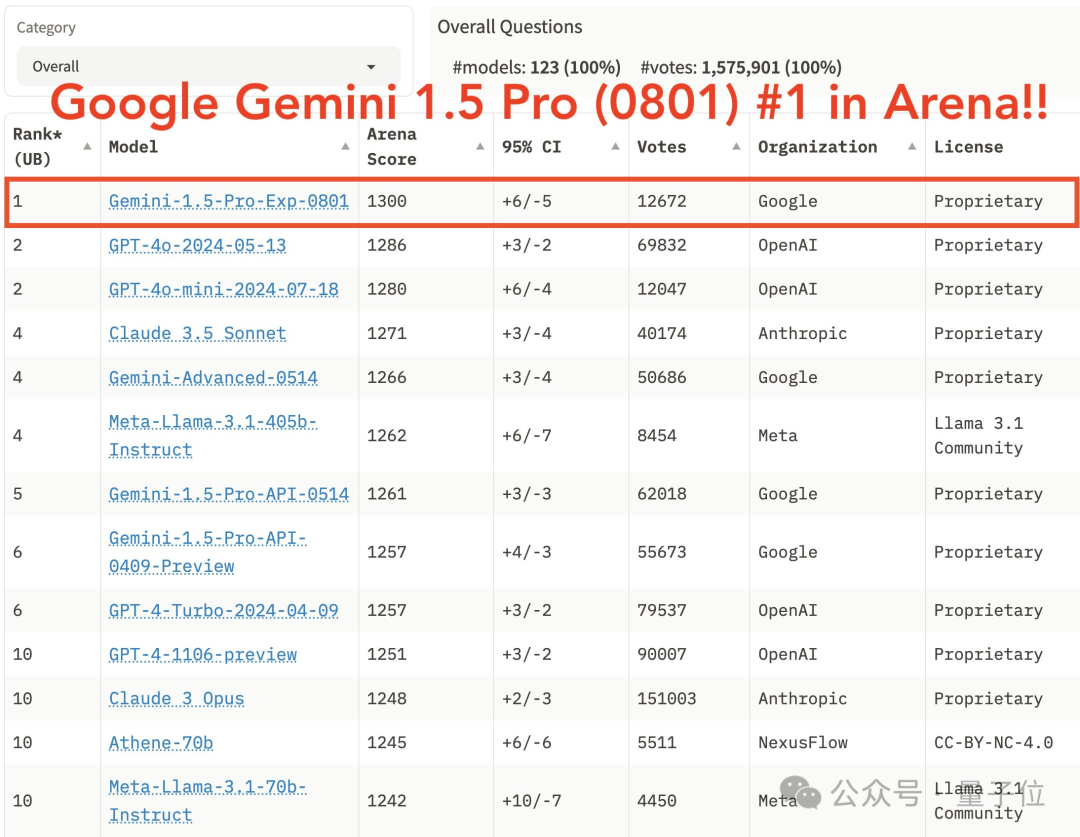
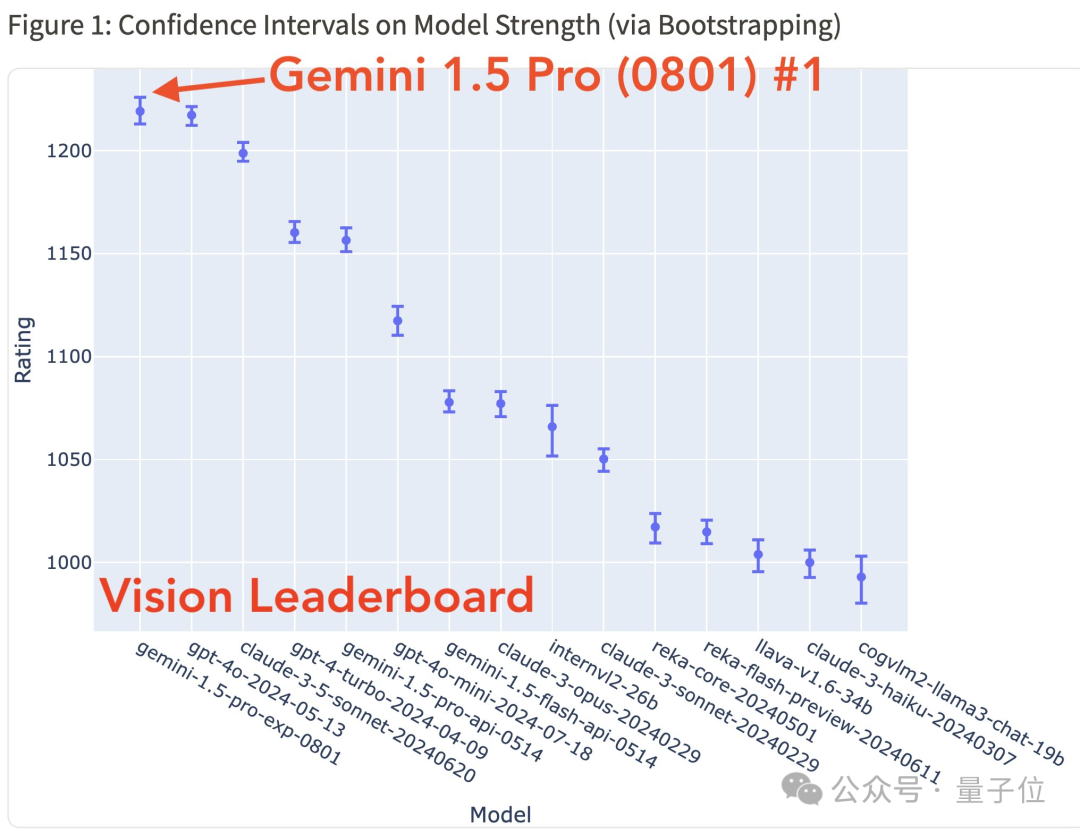
而且这次还是双冠王,除了总榜(唯一分数上1300),在视觉排行榜上也是第一。
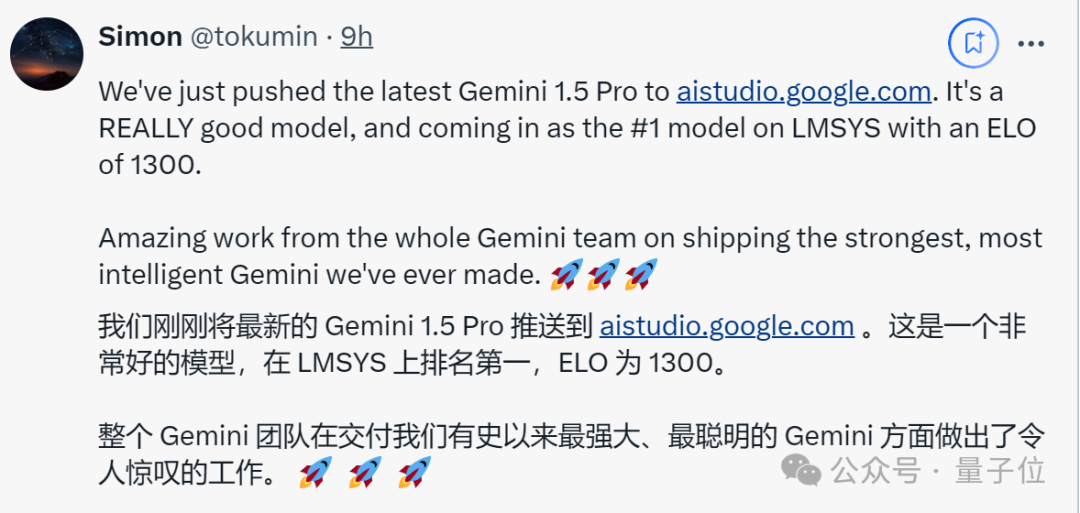
Gemini团队的关键人物Simon Tokumine发文庆祝称:
(这一新模型)是我们制作过的最强大、最聪明的Gemini。
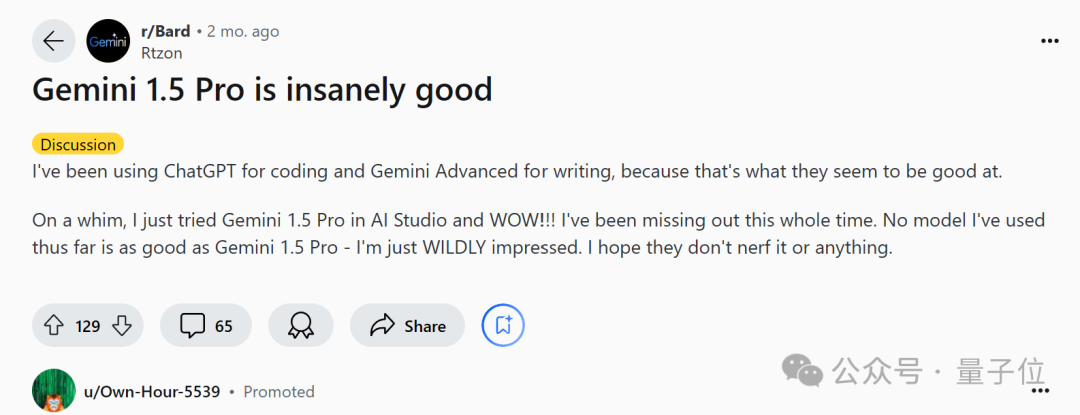
一位Reddit用户也称该模型“非常好”,并表示希望其功能不会被缩减。
更多网友兴奋表示,OpenAI终于受到挑战,要发布新版本来反击了!
ChatGPT官方账号也出来暗示着什么。
一片热闹之际,谷歌AI Studio产品负责人宣布该模型进入免费测试阶段:
可在AI studio免费使用
网友:谷歌终于来了!
严格来说,Gemini 1.5 Pro(0801)其实不算新模型。
该实验性版本建立在谷歌2月发布的Gemini 1.5 Pro基础之上,后来1.5系列将上下文窗口扩展到了200万。
随着模型更新,这命名也是越来越长了,也引起人们一片吐槽。
这不,一位OpenAI员工祝贺之余不忘阴阳怪气一把:
当然了,虽然名字难记,但Gemini 1.5 Pro(0801)这次在竞技场官方评测中表现亮眼。
总体胜率热图显示,它比GPT-4o胜出54%,比Claude 3.5 Sonnet胜出59%。
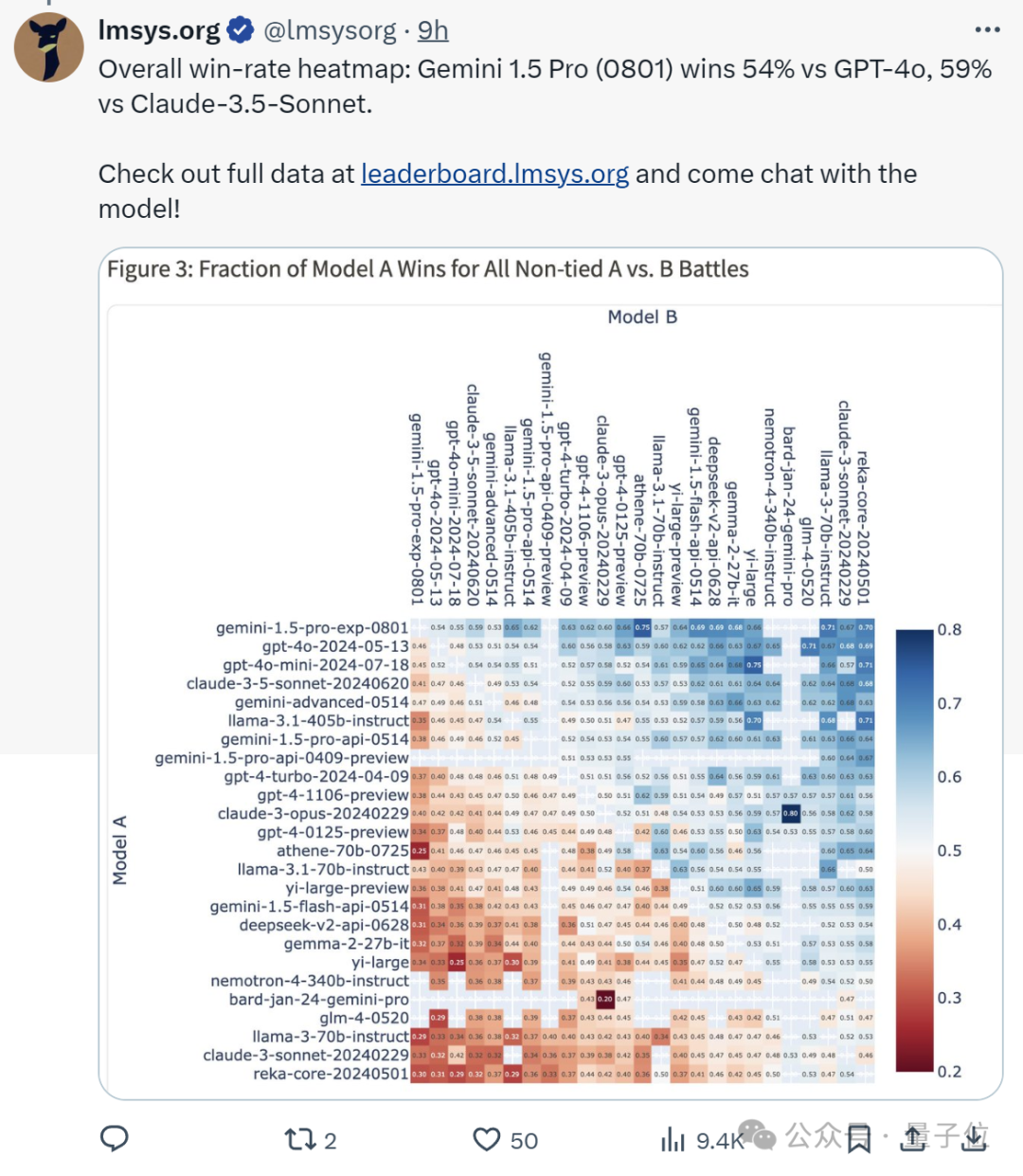
在多语言能力基准测试中,它在中文、日语、德语、俄语均排名第一。

但是,在Coding、Hard Prompt Arena中,它还是打不过Claude 3.5 Sonnet、GPT-4o、Llama 405B等对手。
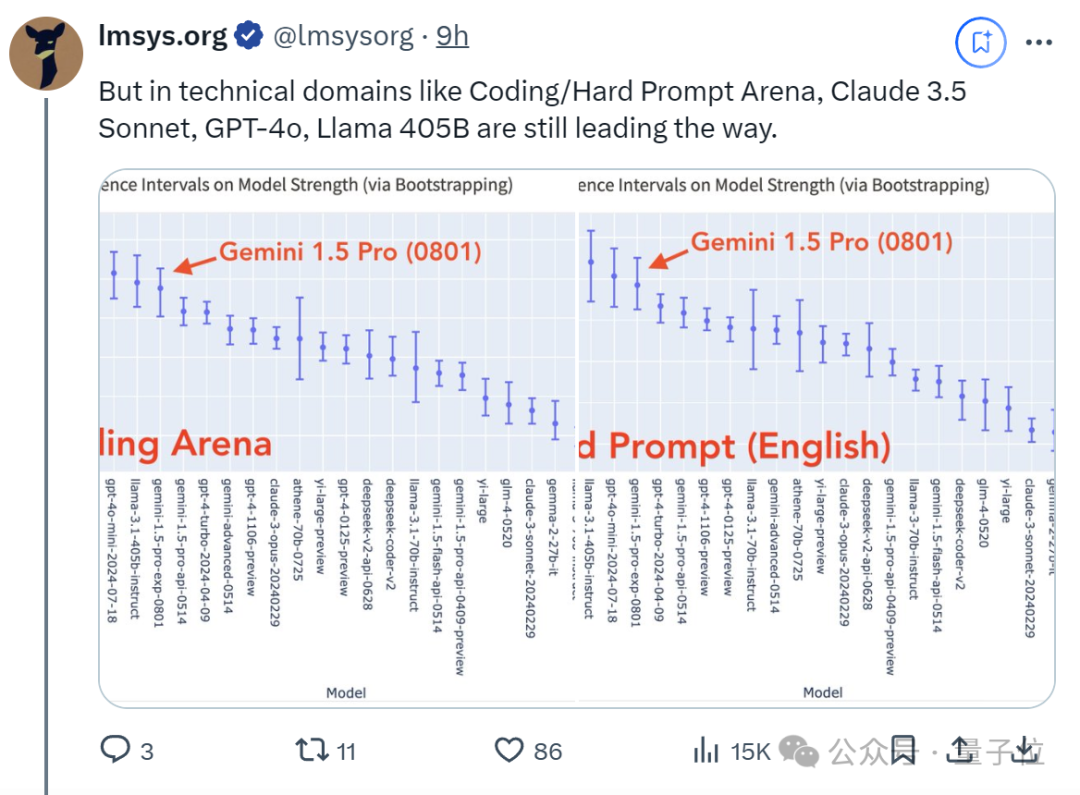
这一点也遭到网友诟病,转译过来就是:
编码才是最重要的,但它在这上面表现不佳。
不过也有人出来安利Gemini 1.5 Pro(0801)的图像和PDF提取功能。
DAIR.AI联合创始人Elvis亲自在油管做了全套测试,并总结道:
视觉能力非常接近GPT-4o。

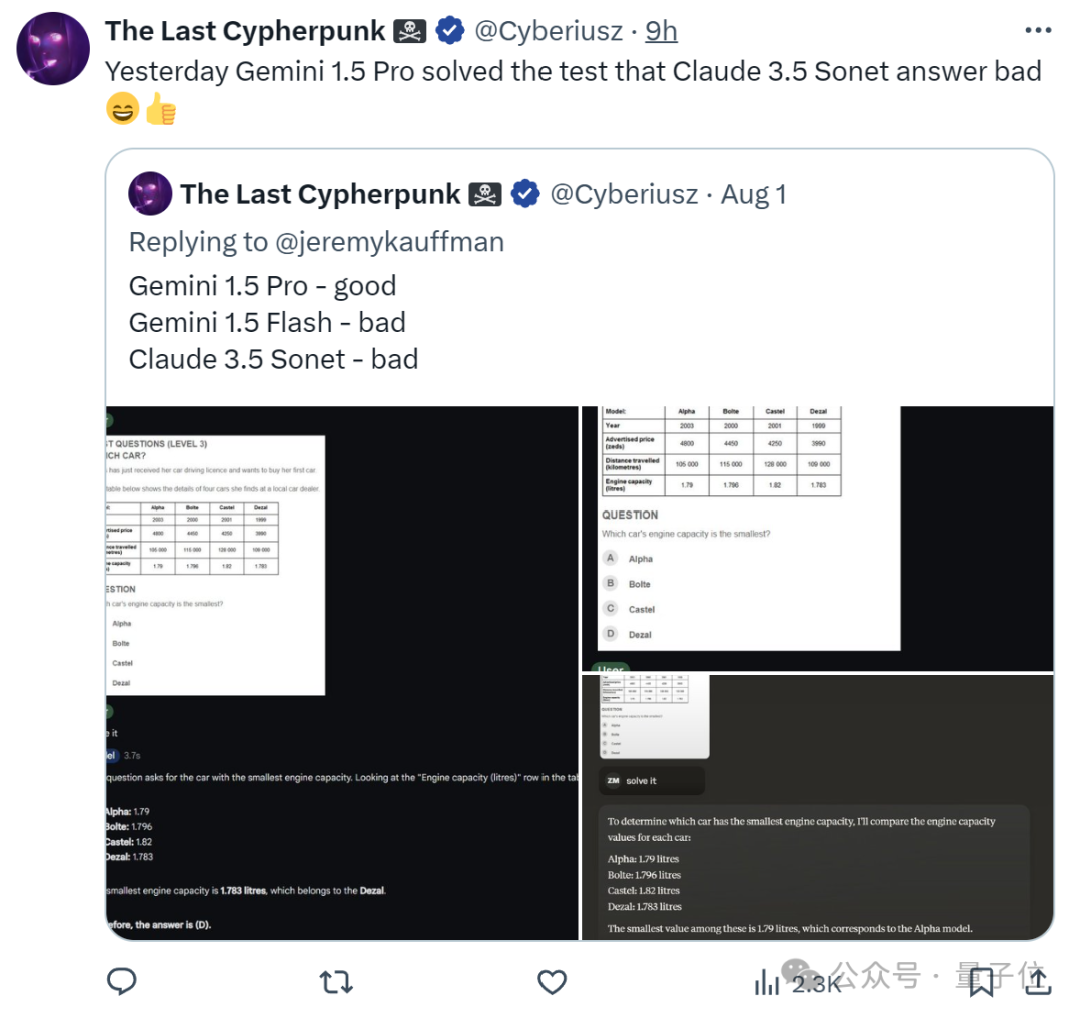
以及,有人拿Gemini 1.5 Pro(0801)来解决Claude 3.5 Sonet之前回答不好的问题。
结果一看,它不仅表现更好,同时也干掉了自家小伙伴Gemini 1.5 Flash。
不过嘛,一些经典常识测试它还是搞不定,比如“写十个以苹果结尾的句子”。

One More Thing
与此同时,谷歌Gemma 2系列迎来了一个新的20亿参数模型。

Gemma 2(2B)开箱即用,可以在Google Colab的免费T4 GPU上运行。
在竞技场排行榜上,它超过了所有GPT-3.5模型,甚至超越了Mixtral-8x7b。
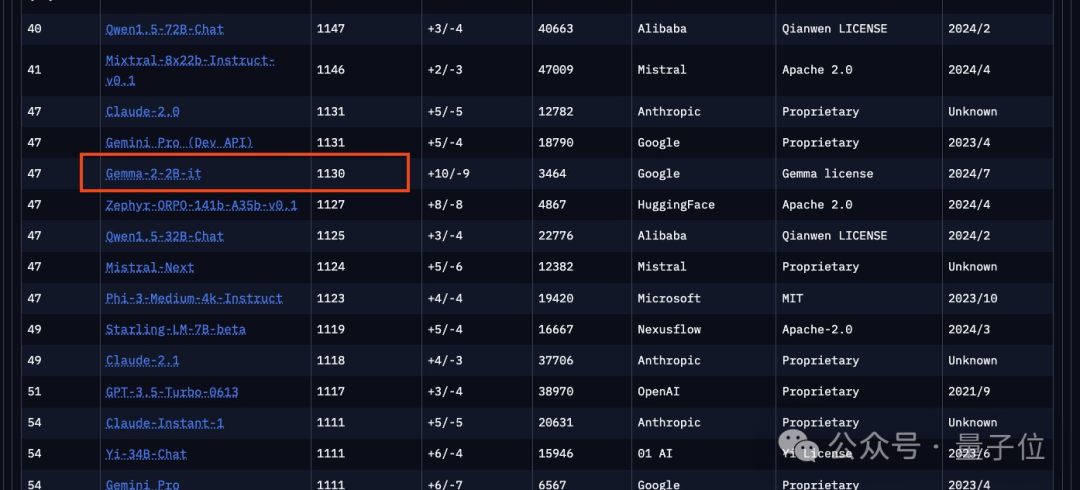
面对谷歌最新取得的一系列新排名,竞技场榜单权威性再次受到大家质疑。
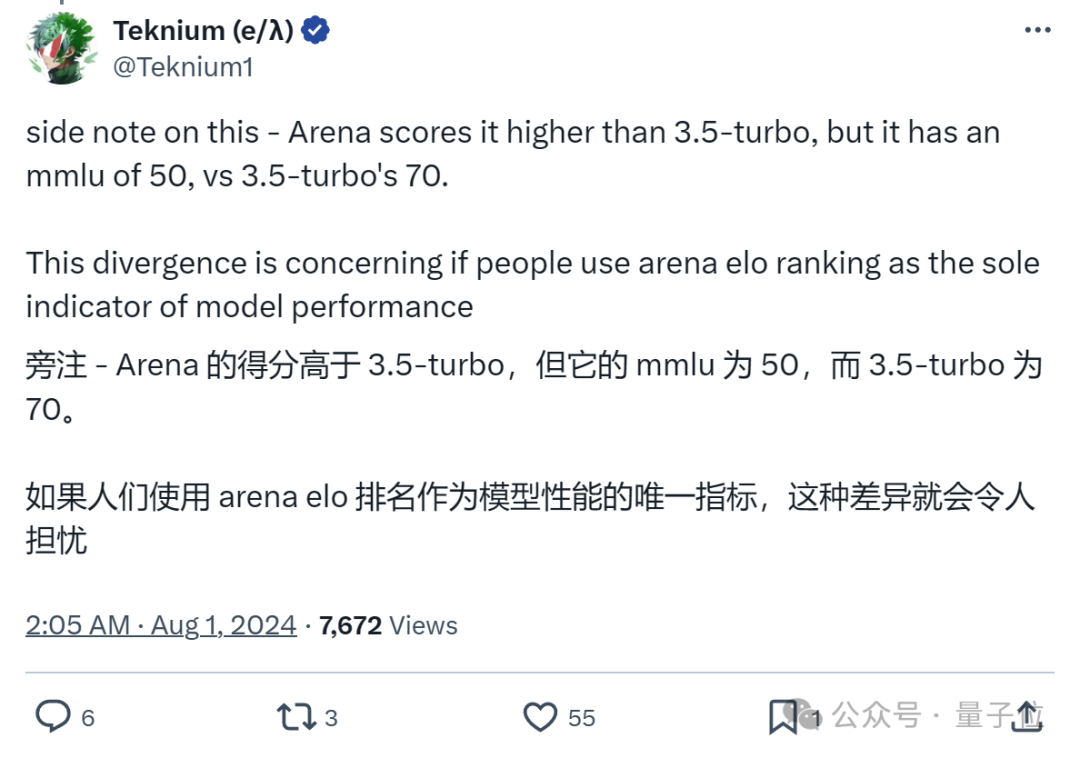
Nous Research联合创始人Teknium(微调后训练领域知名玩家)发文提醒:
虽然Gemma 2(2B)在竞技场得分高于GPT-3.5 Turbo,但它在MMLU上远低于后者。
如果人们使用竞技场排名作为模型性能的唯一指标,这种差异就会令人担忧。
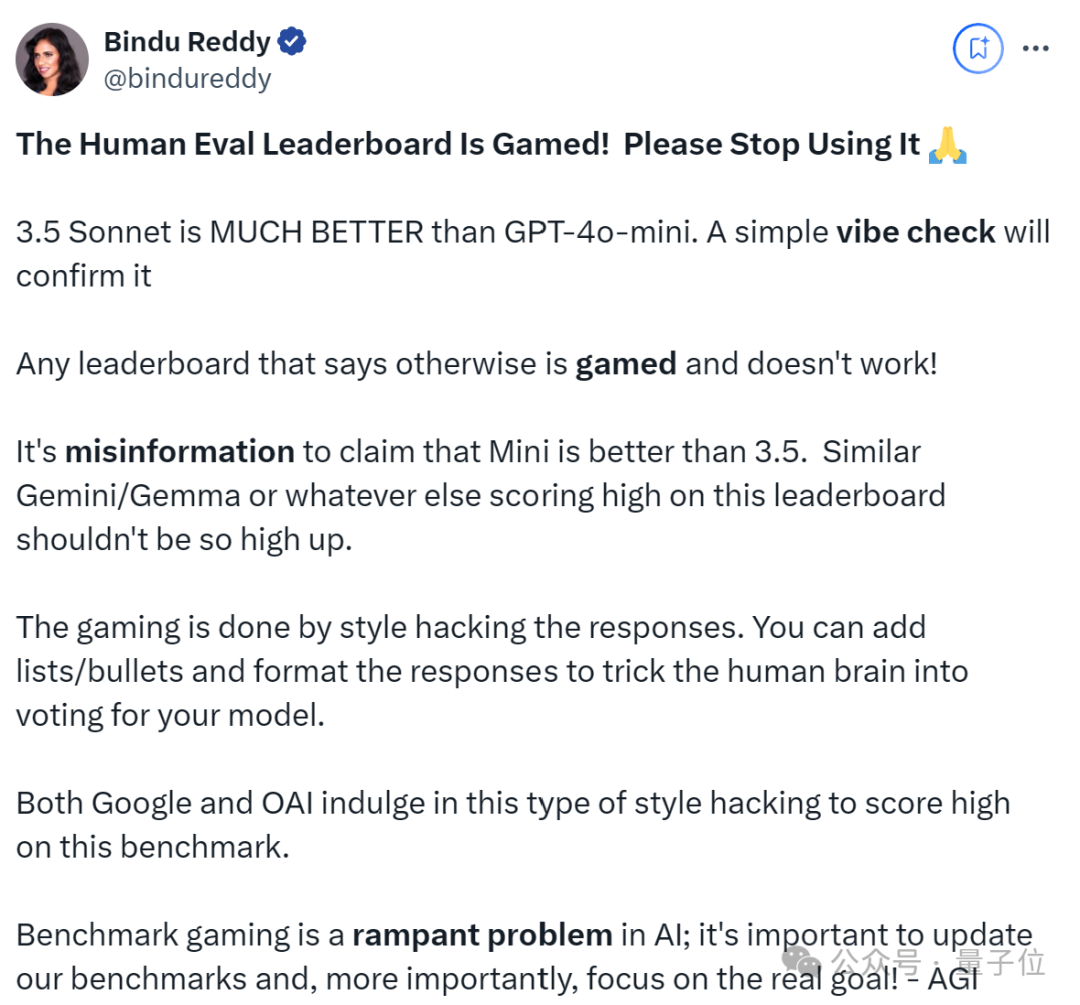
Abacus.AI首席执行官Bindu Reddy更是直接呼吁:
请立即停止使用这个人类评估排行榜!
Claude 3.5 Sonnet比GPT-4o-mini好得多。
类似的Gemini/Gemma在这个排行榜上的得分都不应该这么高。
那么,你认为这种人类匿名投票的方式还靠谱吗?(欢迎评论区讨论)
参考链接:
[1]https://x.com/lmsysorg/status/1819048821294547441
[2]https://x.com/JeffDean/status/1819121162578022849
[3]https://x.com/stevenheidel/status/1819080995062403484
[4]https://x.com/rohanpaul_ai/status/1818697538360295897
[5]https://x.com/bindureddy/status/1818738366466412601
[6]https://x.com/infwinston/status/1818718423700103526
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里👇关注我,记得标星哦~


















 2
2

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









