






Vary团队 投稿 凹非寺
量子位 | 公众号 QbitAI
在AI-2.0时代,OCR模型的研究难道到头了吗!?
(OCR:一种将图像中的文字转换为可编辑和可搜索文本的技术)
Vary作者团队开源了第一个迈向OCR-2.0的通用端到端模型GOT。
用实验结果向人们证明:No~No~No~
GOT模型效果如何?
话不多说,直接上效果图:

△ 最常用的PDF image转markdown能力

△ 双栏文本感知能力

△ 自然场景以及细粒度OCR能力

△ 动态分辨率OCR能力

△ 多页OCR能力
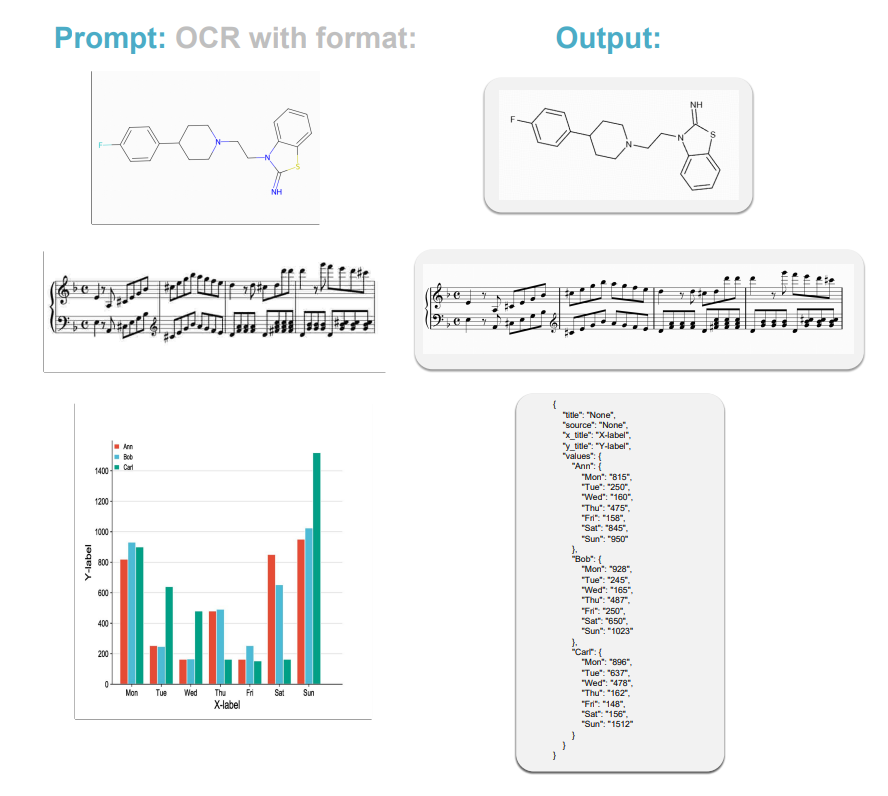
△ 更多符号的OCR能力
研究团队称,尽管GOT模型表现不错,但也存在一些局限,如更多的语言支持,更复杂的几何图,chart上的OCR性能。
他们说OCR-2.0的研究还远的很,GOT也还有不小提升空间(该项目在数据和算力资源上都是非常受限的)。
正是因为深知GOT以及OCR-2.0的潜力,我们希望通过开源GOT吸引更多的人,放弃VQA,再次投向强感知。都说纯OCR容易背锅,但也正好说明做的不够work,不是吗?
GOT: Towards OCR-2.0
通用OCR模型须要够通用,体现在输入输出都要通用上。
GOT的通用具体表现为:在输入方面,模型支持Scene Text OCR、Document OCR、Fine-grained OCR、More General OCR等任务。
△ 通用OCR模型须“通用”
输出方面,模型同时支持plain texts输出以及可读性强、可编辑的formatted文本输出,如markdown等。
模型的结构和训练方法,采用vision encoder+input embedding layer+decoder的pipeline。
Encoder主体采用带local attention的VITDet架构,不会让CLIP方案的全程global attention在高分辨率下激活太大,炸显存。
Encoder后两层采用Vary的双卷积设计方案。整个Encoder将1024×1024×3的图像压缩为256×1024的image tokens,足以做好A4纸级别的dense OCR。
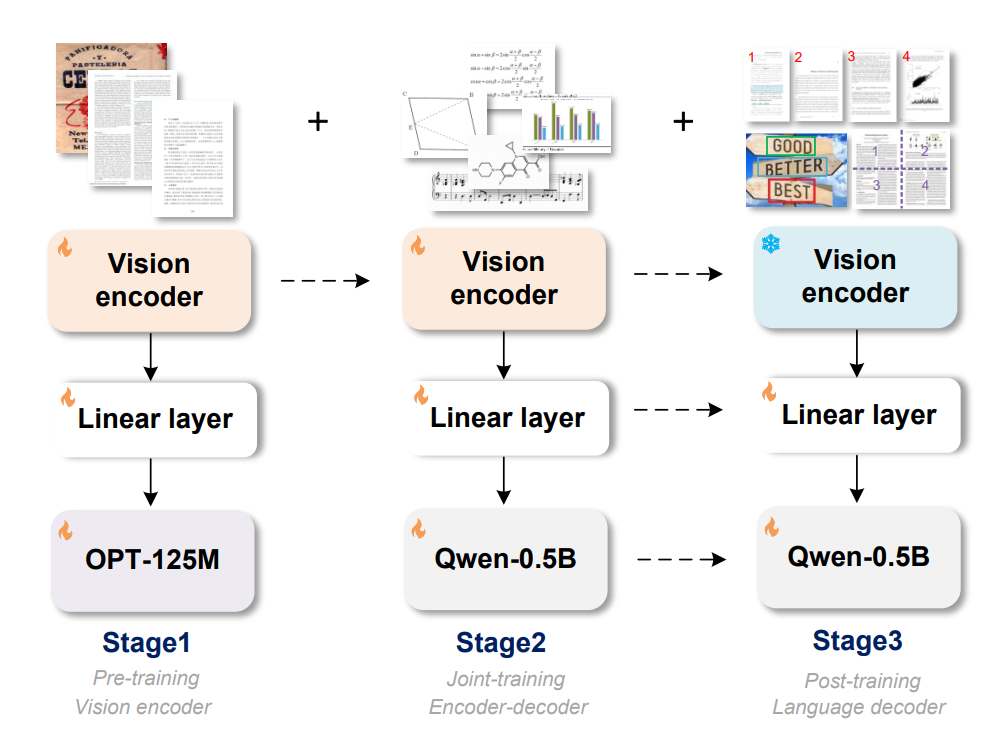
△ GOT结构与训练流程图
研究团队将整个训练过程分为三个步骤,没有一个阶段锁LLM,过程中没有存在图像到文本的对齐阶段,进而导致损害image token的文字压缩率。
三个训练阶段分别为:
第一阶段:高效预训练encoder,GOT在整个训练过程中,没有A100级别的卡,为了节省资源,该阶段使用小型OPT-125M作为decoder为encoder提供优化方向,快速灌入大量数据。
第二阶段:联合训练encoder-decoder,该阶段GOT的基本结构搭建完成,为上一阶段预训练好的encoder,以及Qwen团队预训练好的Qwen0.5B。
研究团队稍稍加大了decoder的大小,因为该阶段需要喂入大量OCR-2.0的知识,而不少数据(如化学式的OCR)其实也是带点reasoning的,不过更小的decoder他们未敢尝试。
第三阶段:锁住encoder,加强decoder以适配更多的OCR应用场景,如支持坐标或者颜色引导的细粒度OCR(点读笔可能会用到),支持动态分辨率OCR技术(超大分辨率图可能会用到),多页OCR技术。
该feature主要是为了后续follower能更好地训练Arxiv这种数据,我们的设想是多页PDF直接训练,无须再对.tex断页而苦恼!
面对整个GOT模型设计中最困难的数据工程环节。研究团队为了构造各种各样的数据,还学习了众多数据渲染工具,包括Latex,Mathpix-markdown-it,Matplotlib,Tikz,Verovio, Pyecharts等等。

△ GOT使用到的数据渲染工具
OCR的研究才刚刚开始
关于为什么在大模型相互梭哈的时代继续研究OCR?
研究团队有他们自己的理由:
OCR一直是离落地最近的研究方向之一,是AI-1.0时代的技术结晶。
到了以LLM(LVLM)为核心的AI-2.0时代,OCR成了多模大模型的一项基本能力,各家模型甚至有梭哈之势。
多模态大模型作为通用模型,总有种降维打击OCR模型的感觉。
那么纯OCR的研究真的到头了吗?我们想说:当然没有!没准才刚刚开始。
首先盘一下AI-1.0 OCR系统和LVLM OCR的缺点:
首先是AI-1.0流水线式的OCR系统,缺点不用多说,各个模块比较独立,局部最优,维护成本也大。
最重要的是不通用,不同OCR任务需路由不同模型,不太方便。
那么多模态大模型在pure OCR任务上有什么缺陷呢?我们认为有以下两点:
1、为Reasoning让路必然导致image token数量过多,进而导致在纯OCR任务上存在bottle-neck。
Reasoning(VQA-like)能力来自LLM(decoder),要想获得更好的VQA能力(至少在刷点上),就要充分利用起LLM来,那么image token就得越像text token(至少高维上,这样就会让LLM更舒服)。
试想一下,100个text token在LLM词表上能编码多少文字?那么一页PDF的文字,又需要多少token呢?不难发现,保VQA就会导致在做OCR任务上,尤其是dense OCR任务上,模型搞得比较丑陋。
例如,一页PDF图片只有A4纸大小,很多LVLM要都需要切图做OCR,切出几千个image token。单张都要切图,拿出多页PDF拼接图,阁下又当如何应对?
我们认为对于OCR模型这么多token大可不必。
2、非常直观的一点就是模型太大,迭代困难。
要想引入新OCR feature如支持一项新语言,不是SFT一下就能训进模型的,得打开vision encoder做pre-training或者post-training,这都是相当耗资源的。
对于OCR需求来说太浪费了。
有人会说,小模型能同时做好这么多OCR任务吗?
我们的答案是肯定的,而且甚至还能更好
论文地址:https://arxiv.org/pdf/2409.01704
项目地址:https://github.com/Ucas-HaoranWei/GOT-OCR2.0
— 完 —
投稿请发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

点这里👇关注我,记得标星哦~
















 12
12

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









