







量子位智库 发自 凹非寺
量子位 | 公众号 QbitAI
当DeepSeek引发业界震动时,元始智能创始人彭博正专注于一个更宏大的愿景。
在他看来,某个模型的爆火只是AI进化的一个普通节点,真正的技术革命才刚刚开始。
作为RWKV架构的缔造者,他的目光已经投向未来的芯片底层革命。
目前在产业界,已有海外独角兽企业开始将RWKV应用于商业实践。
这个故事要从Transformer说起,一个正在被不断挑战的AI铁王座……
以下为量子位与元始智能彭博的对话实录整理:
本对谈主体发生于2025年1月R1发布前,星标部分为2025年2月补充。
△彭博的github主页
重写游戏规则
量子位:能不能先给大家介绍一下RWKV是一个什么样的模型?
元始智能彭博:要了解RWKV,得先从Transformer说起。目前主流大模型包括GPT、Llama这些,都是用的Transformer架构。
Transformer包含两个主要部分:随序列长度增加而变慢的attention机制,和速度显存恒定的FFN全连接网络。
Transformer的attention机制就像考试时候开卷查资料,每写一个字都要翻一遍书,KV cache越来越大,效率自然就上不去。这种方式确实适合做翻译这类需要明确对应的任务。
但是RWKV的思路就更像口试了——模型不能随意重读前文——必须用一个固定大小的state来存储和更新信息。口试的方式难度更大,但它迫使模型更去真正理解,而不是简单地查找匹配。
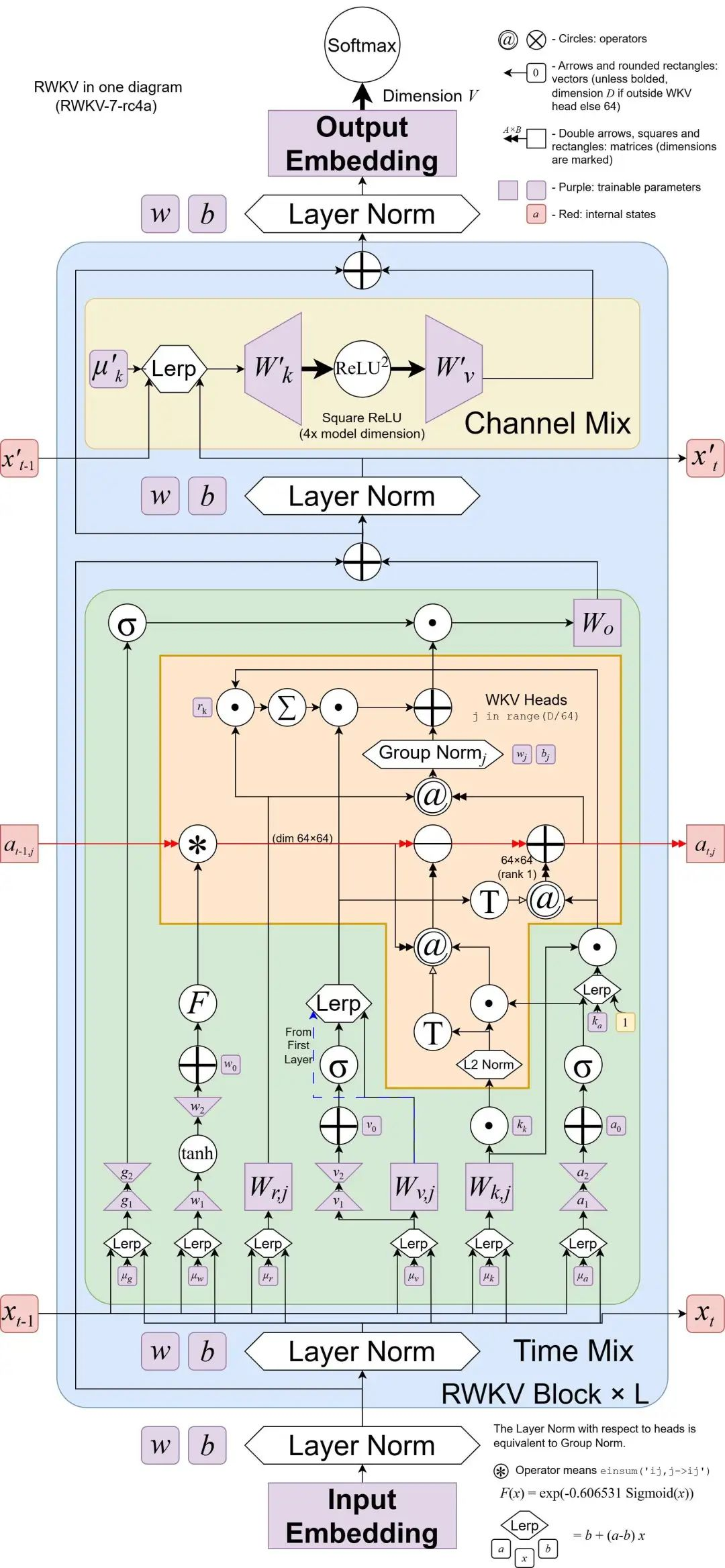
△RWKV-7模型架构图
量子位:Transformer架构能够取得行业主流地位,这里面有多大偶然性和必然性?
元始智能彭博:是必然的。
你看Transformer一开始是设计来做翻译的,这个思路挺不错。它在生成内容的时候不断去前文找需要的信息,这很适合翻译,也包括写文章、写代码这些需要上下文关联的任务。
但问题也很明显。前文越来越长,每生成一个token都要看一遍,速度和内存消耗肯定会越来越大。
你看我们人类,活了几十年,话说多久都不会越来越慢,为什么?因为我们会自动筛选重要信息,不会所有事都记着。
我们会把必须记住的事情记在外部记忆,例如记事本,手机电脑,等等。
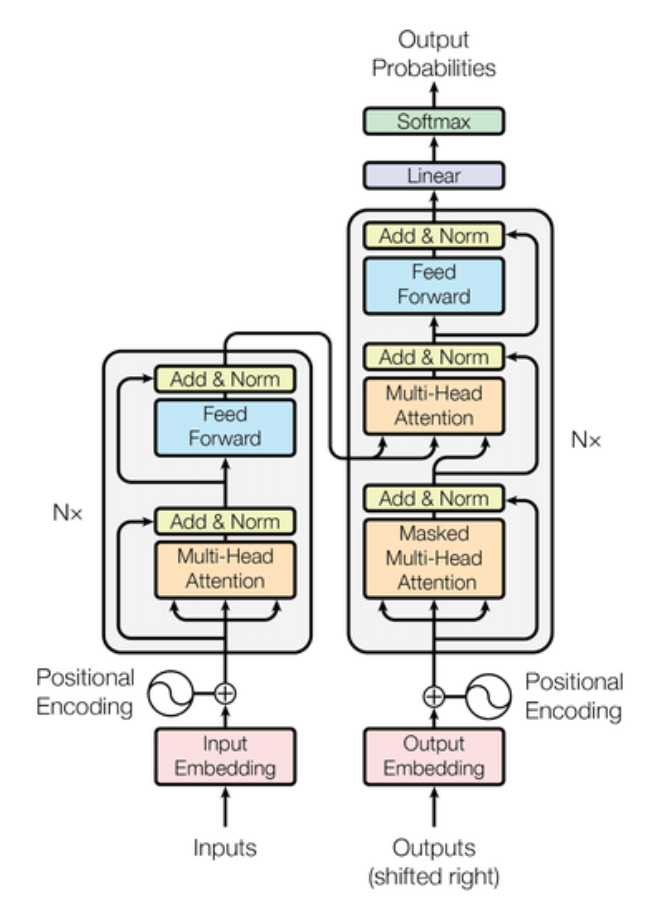
△Transformer模型架构图
量子位:有观点认为Transformer的高性能正是源于其注意力机制,你如何看待这一说法?
元始智能彭博:这么说不太准确。Transformer确实在做那些需要明确对应关系的机械性的任务时表现不错。
但是RWKV通过RL一样能做到这些,它也可以学会使用外部记忆,学会在需要的时候重新查看前文。
从前大家认为Transformer做不了System 2,现在RL+CoT就推翻了这种说法。对于RWKV也会发生类似的事情。
量子位:Transformer的发展历程中,从最初的论文到GPT系列的成功,有哪些关键节点?
元始智能彭博:这是个一步步发展的过程。从最开始做机器翻译,到BERT的突破,再到GPT系列,后来还有ViT等等多模态应用,每一步都在扩展边界。
有意思的是,在GPT-3出来的时候,大家的反应不热烈,即使它已经拥有了现在的很多能力,例如从指示生成网页的能力。
GPT-2有人关注了,GPT-3更多人关注了,但主要还是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3
3

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









