






白交 梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
何恺明再次开宗立派!开辟了生成模型的全新范式——
分形生成模型 Fractal Generative Models,首次使逐像素生成高分辨率图像成为可能,论文名字依旧延续以往的大道至简风格。
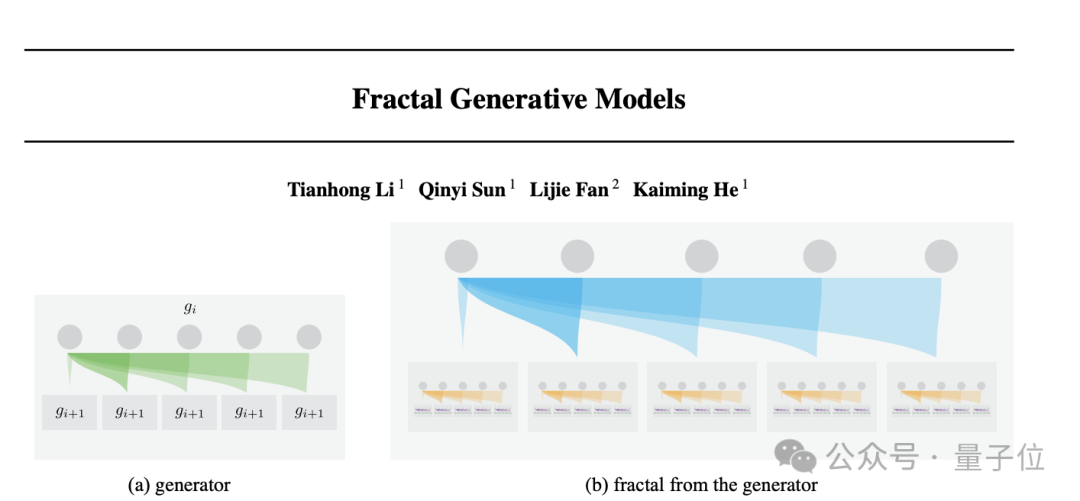
团队将生成模型本身抽象为可复用的“原子模块” 。
通过递归地在生成模型中调用这些原子生成模块,可以构建出一种自相似的分形架构。
其灵感源于数学中的分形思想。它相当于一个粗糙或零碎的几何形状分成数个部分,每一部分都(至少近似地)是整体缩小后的形状。即具有自相似的性质。
嗯,就是像俄罗斯套娃(Matryoshka)那样子。

By the way,「俄罗斯套娃」这个词已经被其他论文用过了,sad。

团队提出用参数化的神经网络作为分形生成器,从数据中学习这种递归法则,实现对高维非序列数据的建模,也可用于材料、蛋白质等。
结果在「逐像素图像生成」这一任务中表现出色。

看到这张图,不免让人想到此前何恺明的代表作之一掩码自编码器MAE。
通过对输入图像的随机区块进行掩蔽,然后重建缺失的像素。

此次团队也结合MAE的成果探索了一些可能性。目前该成果代码已开源。
逐像素生成高分辨率图像
如何使用自回归模型作为分形生成器?
首先考虑到目标是对一大组随机变量的联合分布进行建模 ,直接使用单个自回归模型的计算量令人望而却步。
团队采取的关键策略是“分而治之”,将自回归模型抽象成一个模块化单元。
由于每个级别的生成器都可以从单个输入生成多个输出,因此分形框架可以在只需要线性数量的递归级别的情况下实现生成输出的指数级增长。
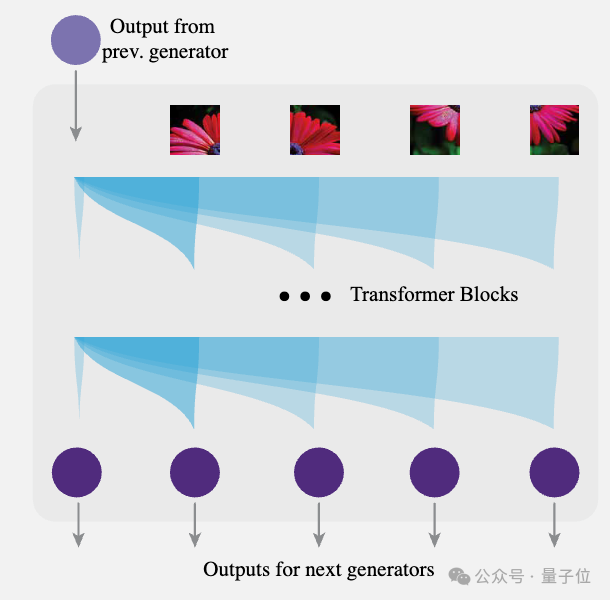
最终,在每个分形级别中,自回归模型接收来自前一个生成器的输出,将其与相应的图像块连接,并使用多个transformer模块为下一个生成器生成一组输出,逐步从图像块到像素细化生成过程。
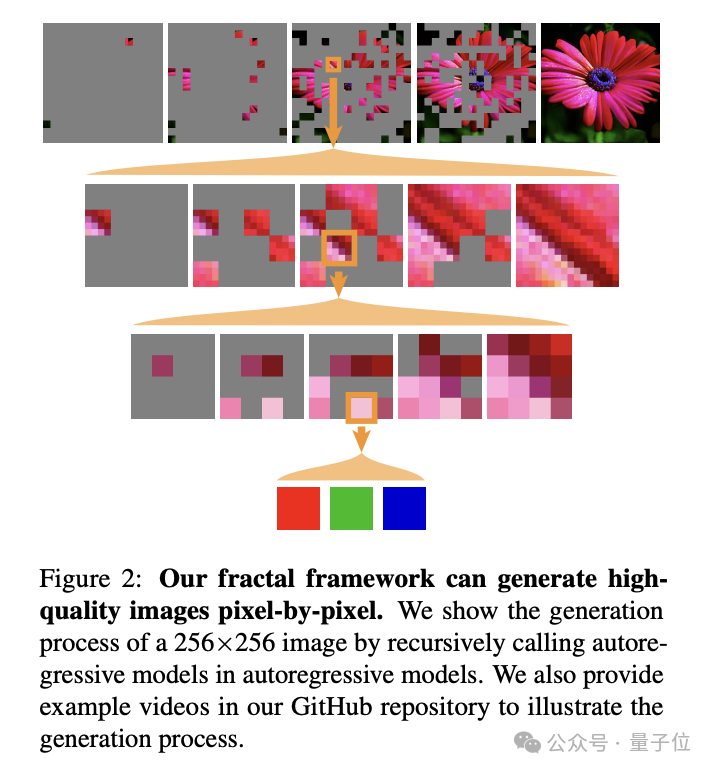
之所以选择像素级图像生成这个任务,是由于原始图像数据具有高维度和复杂性,像素之间存在丰富的结构模式和相互依赖关系。
这类高维生成问题任务在逐个元素生成数据,但又与长序列建模不同,通常涉及非顺序数据,像分子结构、蛋白质、生物神经网络等数据也符合这个特点。
团队认为分型生成模型不仅是一个计算机视觉方法,还能展示分形方法在处理这类高维非顺序数据建模问题上的潜力,为其他数据领域的应用提供参考。

不过还是来看看它在像素级图像上的表现:
首先是直观的视觉效果,在ImageNet 256x256数据集上,逐像素生成一张图需要1.29秒。

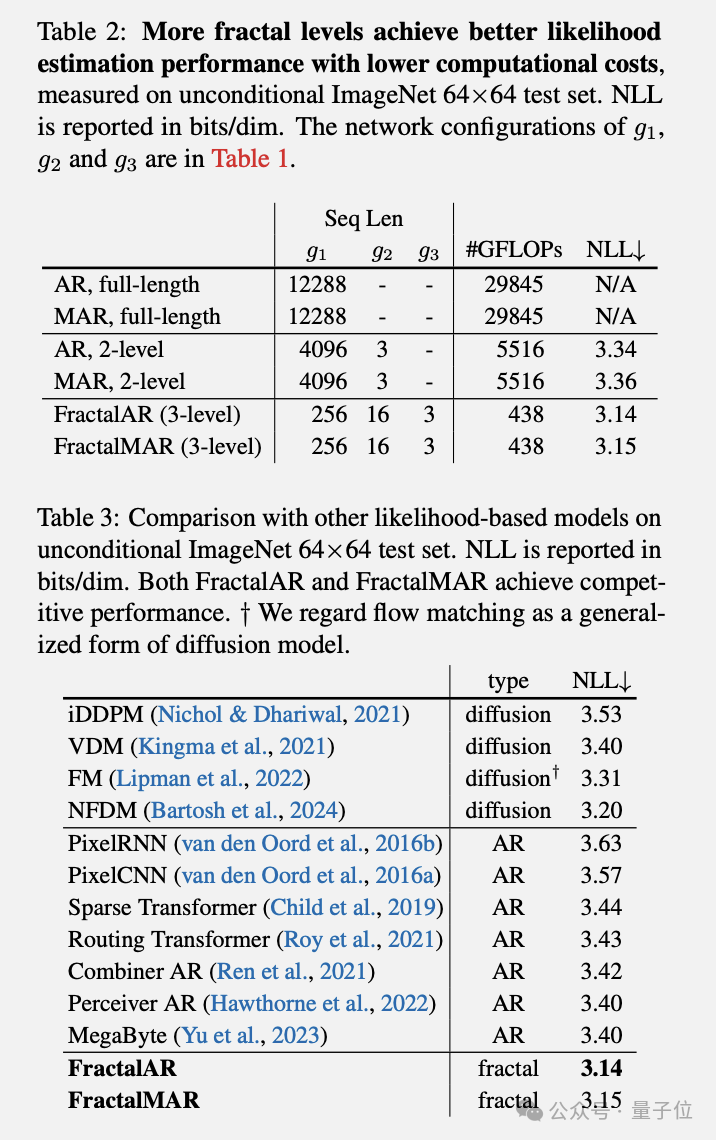
测试指标方面,分形模型在ImageNet 64×64无条件生成上实现了3.14bits/dim的负对数似然,超越此前最佳的自回归模型。
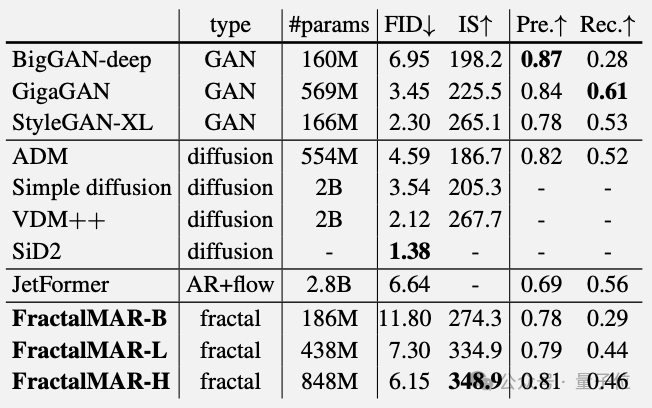
在图像质量上,FractalMAR-H 模型达到6.15的FID和348.9的Inception Score。
更值得关注的是,分形架构将计算效率提高到传统方法的4000倍,逐个像素生成高分辨率图像首次成为可能。

团队还探索了将掩码重建与分形生成模型结合起来,实验发现也可以准确预测被掩蔽的像素。
此外,它可以有效地从类标签中捕获高级语义,并将其反映在预测的像素中,比如最后一列,把猫的脸替换成狗的脸,这些结果证明了该方法在已知条件下预测未知数据的有效性。

最后附上更多生成结果样本。

何恺明MIT天团,一作黎天鸿
此次成果是由MIT何恺明团队和谷歌DeepMind全华人班底完成,并由谷歌提供TPU、GPU资源支持。
一作何恺明的学生黎天鸿。

黎天鸿本科毕业于清华叉院姚班,在MIT获得了硕博学位之后,目前在何恺明组内从事博士后研究。
他的主要研究方向是表征学习、生成模型以及两者之间的协同作用。目标是构建能够理解人类感知之外的世界的智能视觉系统。
此前曾作为一作和何恺明开发了自条件图像生成框架RCG,团队最新的多项研究中他也都有参与。

Qinyi Sun,目前MIT三年级本科生。
范丽杰,清华计算机系校友,去年博士毕业于MIT CSAIL,目前在谷歌DeepMind担任研究科学家,致力于生成模型和合成数据。
此前曾与黎天鸿共同参与过FLUID的研究——
一个可扩展的自回归文本转图像模型,无需VQ。10B参数模型实现SOTA性能。

论文地址:
https://arxiv.org/abs/2502.17437v1


















 4
4

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









