







导语 | 本文尝试在系统级的编译软件层面,挖掘云应用的性能提升空间。以C/C++应用的反馈优化技术为例,介绍业务和编译技术深度整合后产生的收益和价值,希望给相关业务的探索提供参考。
一、现代云应用特征
云应用特征梳理是一个非常庞大的系统工程,只有云厂商才有机会做全局剖析。一些特征沉淀成专用芯片或专用指令,比如AI芯片和新一代ARM64 CPU中的Matrix乘累加指令,或者一些RISC-V中的Protobuf加速尝试,一些特征驱动系统级的OS/编译软件优化获得普适收益。本次我们主要以典型C/C++应用展开分析,目前这仍然是云应用部署量和代码量的主力。
(一)计算特征
从芯片微体系结构角度看,云应用和桌面/移动应用计算特征有几个非常大的差别,主要包括程序热点分布和Cache压力。一方面云应用的workload非常分化,无论从机器内的应用看还是从应用内的函数看,执行非常扁平。整个应用计算跨越多个组件,从基础库(rpc/zip/pb/memory)到自身分布式服务组件,应用内函数热点通常是非常典型的扁平分布。尽管这种分化性的存在,我们仍然认为超级应用的存在,比如一个DB的云部署量几百万核,一个流行APP的后台部署量千万核。
另一方面云应用对Cache压力很大。从指令Cache角度看,BinarySize通常很大,为方便部署通常静态链接,几十几百M几G大小非常普遍,指令内存占用远超ICache大小(100x),大的指令内存占用导致处理器的前端压力很大,前端停顿能占到整个应用的15-30%,而传统桌面/移动端只有5%,云应用MPKI(千条指令失效数)通常是所谓标准benchmark的1-2个数量级。这些计算特征驱动一些系统级优化的机会和价值,包括针对基础库的通用优化,比如通过针对Kernel的编译优化可以普适提升一些sys时间占用大的应用比如kv数据库性能,通过操作系统对text的hugepage支持可以进一步降低iTLB压力,针对ICache的编译优化可以提升超级应用的性能,10%的提升可以对应几十万到几百万核的提升。这些特征也可以指导未来的硬件设计。
(二)基本数据
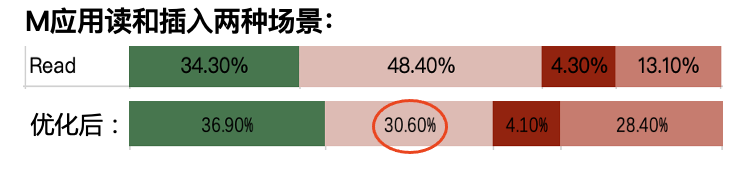
这里通过一些业界和自身业务数据来量化描述上述的计算特征,这些数据主要基于TMAM(自顶向下的微体系结构分析方法)。TMAM主要采用分层的方法去确定应用的微体系结构瓶颈,在顶层将应用执行划分为四个阶段,Frontend Bound,Bad Speculation,BackendBound和Retiring,每个阶段可以再下下细分子阶段。关注ICache影响主要看Frontend Bound的占比,关注DCache影响主要看BackendBound占比。下图是我们对公司内部使用的两款开源数据库R和M的TMAM分析,其中R测试随机读场景下,M测试读和插入场景。

R数据库随机读场景:

M数据库读和插入两种场景:


下图是Google给出的自身业务的TMAM分析,其观点是云应用的Frontend Bound占比远高于当前业内所谓benchmark的对应部分(2-3x),应用BinarySize每年增长~30%。
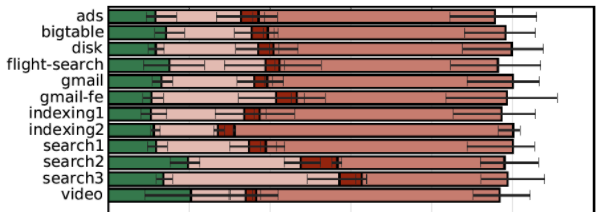
下表是不同应用的ICache失效数据,可以看出MySQL的ICache/ITLB失效非常高。
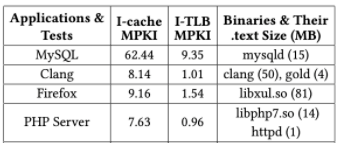
从不同云应用不同纬度的性能数据看,ICache/ITLB是云应用一个典型瓶颈。从系统软件角度看,OS和编译器有很大的改进空间,特别是存在一些OS/编译器协同优化的空间。从业界看,Google/Facebook近几年也在结合自身云应用特征来分析和优化系统,也产生有一些有影响力的社区工作。
二、编译优化技术
编译器是一个非常庞大的系统软件,其南向是各种芯片(CPU/GPU/NPU),其北向是各种语言(C/C++/JS/DSL),中间是一条漫长的优化流程。
从芯片视角,语言视角,或者应用特征视角,编译器的设计都有不同的侧重点。比如过去编译器针对Branch的优化侧重于减少branch损失的cycle,但从云应用的角度看ICache应该更优先,而这两种目标在设计上又会有冲突。我们这里重点从第一章中的云应用特征角度来针对性的探讨优化。
(一)反馈优化技术及策略
反馈优化的方法是:采集某个程序在运行实际业务时的代码调用信息,使用该信息指导该程序的编译,从而达到优化性能的目的。如下两个例子可以帮助理解反馈优化:
Basic Block (BB) Reorder是编译器在编译过程中,为了优化程序性能而存在的编译环节。在进行BB Reorder时,如果能了解到在实际业务中,哪一个BB被调用的更频繁,就能使得这些BB在重排时,能够被放到相对更合理的位置,否则,只能根据对代码本身的静态分析进行通用的Basic Block Reorder。
Inline是编译器对一部分函数进行函数体展开,从而减少函数调用过程中开销的优化操作。如果能够了解到实际业务中,每个函数调用的频繁程度,那么会使得Inline展开更加合理,否则,只能根据函数体的大小和对代码的静态分析进行通用的Inline展开。
反馈优化技术
反馈优化可以发生在编译时和编译后,主要有以下几种方法:
Profile Guided Optimization (PGO)
Sampling PGO
Instrumentation PGO
使用 Binary Optimization and Layout Tool (BOLT)
Sampling PGO的过程是:
使用Profile工具(比如linux的perf)采集进程运行时的代码调用信息。
使用编译器提供的工具将perf产生的代码调用信息转换为编译器可以识别的格式。
使用转换后的代码调用信息重新编译程序。
Instrumentation PGO的过程是:
编译Instrumented版本的程序。
运行程序,采集进程运行时的代码调用信息。
使用采集到的数据重新编译程序。
采集过程中,Sampling PGO不对程序本身进行修改,而Instrumentation PGO会在程序中加入记录点,在程序运行时通过这些记录点,收集程序运行时的代码调用频率等信息。Instrumentation PGO会带来运行时额外的开销,而Sampling PGO可以直接对在线运行的程序进行信息的采集,不需要使用特殊模式对程序进行编译就可以收集到所需的信息。因此,Sampling PGO采集信息的过程带来的额外开销相对Instrumentation PGO更小。
Instrumentation PGO会在程序中加入大量记录点,因此,带来额外开销的同时,会记录充裕的程序运行时信息来帮助后续的优化过程。而Sampling PGO需要依赖其他Profile工具的同时,采集的信息也相对Instrumentation PGO更少。因此,Instrumentation PGO一般作为Sampling PGO的基准,通过比对本次Sampling PGO与Instrumentation PGO的性能差距来判断本次Sampling PGO的优劣。
Sampling PGO由于是使用Profile工具进行采样的,由于Profile工具本身,与Profile工具使用方式的差异,使得Sampling PGO的结果会产生波动。而Instrumentation PGO由于是在特定位置插入观测点来采样,因此可以得到相对稳定的可复现的结果。需要特别注意的是,无论是PGO还是BOLT,均要求使用实际运行时会使用到的输入来当作程序运行时的输入,否则不仅不会产生优化的效果,甚至可能会发生性能退化。
与PGO不同,BOLT优化的对象是链接后的二进制文件。相似的是,BOLT同样使用Profile工具采集程序运行时信息,比如Linux perf,或者使用Instrumentation PGO中编译得到的Instrumented程序采集的运行时信息。BOLT首先会将二进制文件反汇编,基于反汇编构造程序的Control Flow Graph (CFG),然后基于CFG使用采集得到的运行时信息进行优化。
AutoFDO
反馈优化可以与CI/CD进行结合,从而实现自动化 (AutoFDO, Automatic Feed Back Optimization),AutoFDO当前主流的搭建方法是基于Sampling PGO和BOLT的,原因是在采集Sampling PGO和BOLT所需的程序运行时信息时,几乎不会对线上正在运行的程序造成影响。
如果使用基于Instrumentation的方法,由于产生的Instrumented程序加了很多记录点,使得性能会大幅度下降。使用基于Instrumented的方式进行AutoFDO也并非完全不可行,如果业务是离线处理的话,可以将部分输入发给Instrumented程序,从而进行信息采集。
无论使用上述哪种方式,AutoFDO接下来会定期采集程序运行时信息,使用该信息定期进行PGO与BOLT优化,将优化结果在程序库中缓存。最后,根据不同业务部署的策略,定期的将优化后的二进制部署到线上,从而实现AutoFDO,全部流程如下图所示。
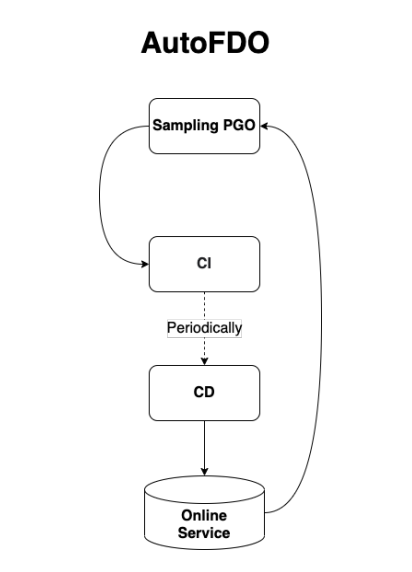
由于Profile设计在线采集,很多项目在通过启发式规则和AI的方式改进静态Profilie的准确性,从而提升当前编译器中普遍使用的Wu方法。
(二)针对Branch行为的优化
为了掩盖分支(Branch)指令的延迟,现代处理器几乎都拥有分支预测的能力,通过投机执行分支处指令,避免在流水线中产生停顿(Stall)。虽然最先进的分支预测器可以做到超过95%的准确率,但只要预测失败,就需要清空流水线,重新加载正确的分支,这通常带来几十条指令周期的性能损失。编译器中大量优化方案以优化Branch行为作为出发点,目的都是降低Branch带来的性能损失。常见的优化思路包括以下几种:
消除分支指令
删除冗余的分支指令,例如连续的两条无条件跳转,可以合并成为一条分支指令;将条件分支+后续操作,变换成条件传送指令。典型优化方案还包括ICP(indirect call promotion)/function inlining,降低函数调这一类分支指令具有重要价值。
减少分支指令执行次数
分析代码的控制流,设计可行的等价变换,使得分支指令的执行次数最少。典型的包括循环优化中的loop peeling/loop invariant code promotion,都可以实现减少循环体内部分支指令执行次数的效果。
提升分支预测准确率
在实现优化方案时,考虑对硬件分支预测器的友好性,例如使条件分支后的的第一个代码块是最有可能被执行的。更进一步的,利用先验信息预测代码的执行路径,调整代码布局以适应分支预测器。这些先验信息可以来自于代码静态分析、编译器内建的分支预测特性(likely()/unlikely())、profiling数据。在拥有准确的profiling数据后,根据条件分支的执行概率,可以针对代码的冷热路径,做进一步的优化。借助反馈优化技术,也为一些相对复杂的控制流分析和变化提供了依据。下面将举例说明拥有profiling数据后,对于branch行为优化方案的改进。
loop predicting
统计循环体内各分支的执行概率,尝试将执行概率最高的一条分支检测条件松弛成不变量,再提取到循环体外部。
初始状态:
for (i = 0; i < n; i++) {
guard(i < len);
...
}松弛检测条件后:
for (i = 0; i < n; i++) {
guard(n-1 < len);
...
}循环不变量外提:
if (n - 1 < len)
for (i = 0; i < n; i++) {
...
}
else
deoptimize这个优化有正收益的前提是,外提分支在所有分支中执行概率最大。静态分析无法得出该结论,借助profile信息可以给编译器提供此类优化机会。
Partial Inlining
这是对普通inlining优化的增强,同样需要借助profile信息。如果发现函数入口处有返回语句,而根据profile信息,该返回语句的执行概率非常高,编译器将尝试将该返回语句前段基本块inline到调用点(caller)。例如:
void foo() {
bar();
// rest of the code in foo
}
void bar() {
if (X)
return;
// rest of code (to be outlined)
}partial inlining后:
void foo() {
if (!X)
bar.outlined();
// rest of the code in foo
}
void bar.outlined() {
// rest of the code in bar
}(三)针对iCache/iTLB的优化
根据TMAM性能分析方法,ICache Miss和ITLB Miss是构成CPU前端停顿的主要因素。据谷歌公开数据,在云应用中,前端停顿占整个应用执行时间的15-30%。过去编译器对Branch的优化策略重点放在降低branch行为产生的损失,上一章节介绍的优化方法都遵循这一思路。面对云应用场景CPU停顿因素构成的上述变化,编译器优化策略理应做相应调整,针对ICache/ITLB命中率的提升设计优化方案。近年来业界针对ICache/ITLB提出了一些优化方案,包括通过调整二进制文件布局聚合热点代码降低ICache/ITLB丢失率,以及通过操作系统对text的hugepage支持进一步降低iTLB压力。本章节以经典的Basic Block Reorder和Function Reorder为例,介绍这一类思想在编译器优化中的应用。
Basic Block Reorder
Basic block reorder是一种常见的iCache优化,旨在通过重排basic block的layout,达到更好的code locality,进而降低iCache miss rate。一个basic block,包含一串顺序执行的指令。简单来说,其思路是根据basic block的执行频率,确定hot basic block,在处理分支跳转时,将hot branch basic block放在分支跳转指令后面,使其成为 fall-through block。因此带来的收益是降低分支跳转的次数和降低iCache miss rate。如下面左图,BB3具有更高的branch probability,因此basic block reorder进行优化后的basic block layout如下面右图。
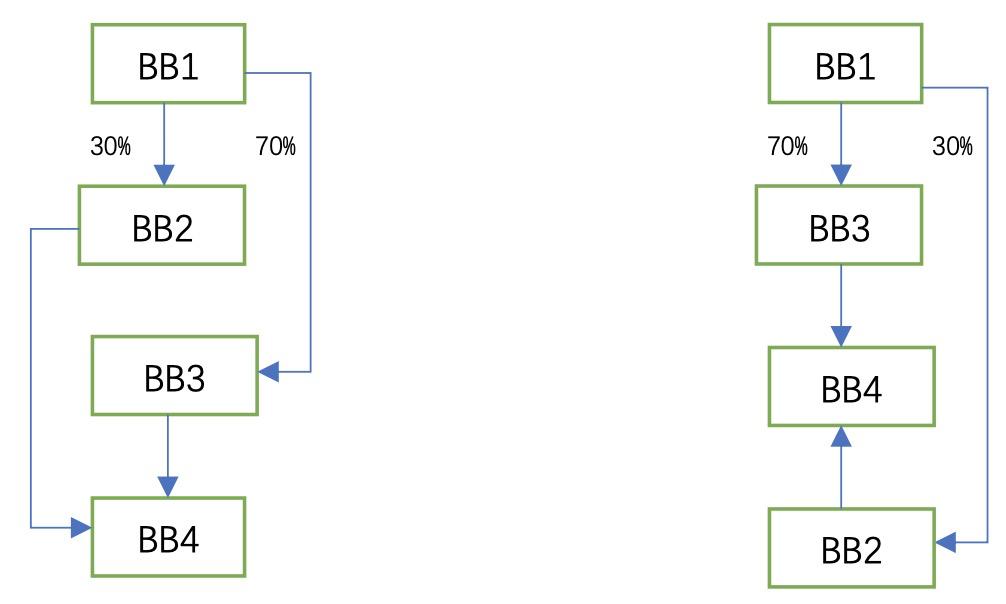
用例子来进一步说明:
int foo(int key, int data) {
if (key > 100)
data -= key | 3;
else
data += key | 5;
data = data >> 7;
return data;
}上面这段C代码产生的汇编如下,如果在实际运行中,(key>100) 这个分支判断高频率命中,即“jle L2”很少发生,那么bb1这个basic block具有很好的code locality。
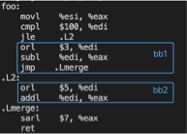
反之,如果profile信息显示 (key>100) 这个分支判断低频率命中,即“jle L2”高频率成立,那么跳转到bb2这个basic block会导致较大的iCache miss,这种情形下,通过basic block reorder调整bb1和bb2的位置,以减小iCache miss,优化后产生的汇编如下。
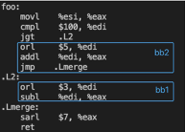
Function Reorder
函数级的布局重排对于ICache和ITLB的访问效率改善有显著作用。FaceBook提出了函数布局优化方法HFSort:

其主要流程如下:
首先收集应用典型使用场景的profiling数据。
解析profiling数据,构造出带权重的函数调用图(Call Graph)。
使用一些先验性算法,计算出调整后的函数排列顺序,通过linker得到优化后的二进制。
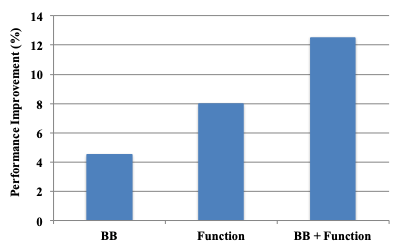
Basic Block和Function reorder两种方法具有互补性,二者结合起来的效果如下图。
一些改进
传统的基本块重排主要考虑branch指令开销影响,特别是在之前CPU中编译器更关注减少branch损失,所以很多开销模型都是基于处理器branch指令开销,比如经典的PH模型,但branch损失优先的策略经常会影响ICache行为,比如基本块复制。如果优先目标变为iCache损失,那这部分的优化以及开销模型都要随之改变。但ICache开销的建模远比branch损失复杂。近几年这个领域最常见的做法是MLGO(Machine Learning Guided Compiler Optimizations)。在静态profile阶段,通过针对控制流特征(比较操作数类型/跳转方向/循环等)向量建模,获得特定应用更准确的静态profile数据。在基本块重排阶段,通过针对控制流特征(跳转长度/跳转方向/跳转类型等)向量建模ICache影响,score函数直接为为程序性能。
三、在典型云应用场景的实践
我们在公司内部的两款数据库M和R上实践了上述优化,其性能测试及TMAM分析的结果如下所示:
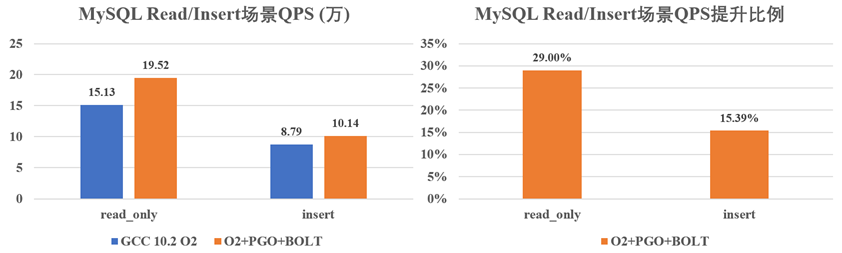
MySQL数据库在Read下的TMAM数据如下图所示,可以看出,FE部分的瓶颈减少~18%。

四、总结
云厂商拥有巨量的业务代码和数据,剖析这些业务背后的计算特征,在系统级的OS/编译器层面提供普适性的优化方法,将给云业务提供潜在的竞争力。本文以C/C++应用的反馈优化技术为例,介绍业务和编译技术深度整合后产生的收益和价值,希望给相关业务的探索提供参考。
参考资料:
1.Top-down Microarchitecture Analysis Method.
2.Automated Hot Text and Huge Pages: An Easy-to-adopt Solution Towards High Performing Services, 2019.
3.Optiminzing Function Placement for Large-Scale Data-Center Applications, 2017.
4.BOLT: A Practical Binary Optimizer for Data Centers and Beyond, 2019.
5.Improved Basic Block Reordering, 2018.
6.Profile Inference Revisited, 2022.
7.MLGO: a Machine Learning Guided Compiler Optimizations Framework, 2021.
作者简介

陈易龙
腾讯蓬莱实验室高级工程师
腾讯蓬莱实验室高级工程师,目前负责推动腾讯c++编译器基础设施的能力构建。
推荐阅读

















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









