







👉目录
1 背景现状
2 tRPC 脚手架工具建设
2.1 trpcx.NewServer()
2.2 tRPC插件引入
2.3 OpenTelemetry yaml 文件创建
2.4 规范目录结构生成
3 文档天机阁租户降本增效
3.1 ClickHouse 优势
3.2 存储迁移节奏
3.3 文档租户数据计算
3.4 落地效果对比
4 可观测性最佳实践
4.1 可观测性是什么
4.2 三大数据模型
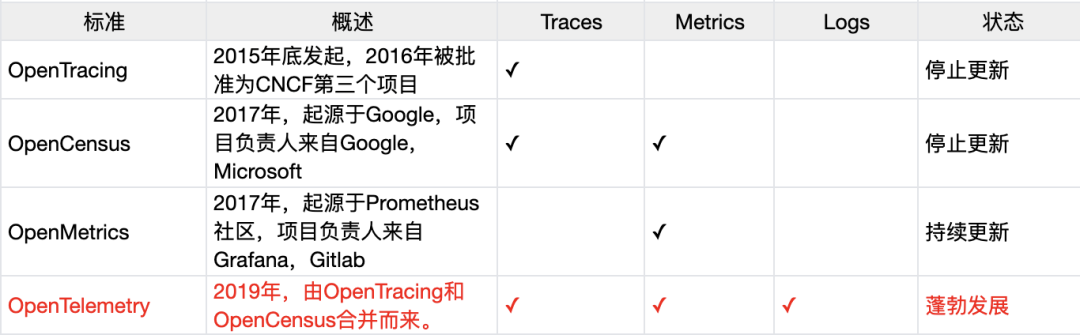
4.3 OpenTelemetry 是什么
4.4 天机阁与 OpenTelemetry 关系
4.5 目前不规范实践
4.6 服务接入
4.7 基于监控进行根因分析
4.8 排查现网问题正确姿势
针对腾讯文档后台大仓研发模式,在后台非标 tRPC 服务改造过程中,结合基础架构组开发的通用 trpcx 和脚手架工具,以插件化、标准化、可观测性为目的,赋能文档后台研发效能提升。同时,通过迁移天机阁 ES 存储至 ClickHouse,实现文档后台业务增效。
01
背景现状
tRPC 是腾讯自研的高性能、跨平台、插件化、具备高度服务治理能力的 RPC 框架, 目前在公司内各大业务广泛使用并已对外开源,详见:腾讯开源 tRPC:多语言、高性能 RPC 开发框架。文档后台使用大仓研发模式进行项目管理。在过去存量服务中,有以下等问题亟待解决优化:
第一,框架层未实现统一,存在大量使用非标 tRPC-Go 服务的情况,同时存有部分非 tRPC 的 Golang 服务和少量 Java、PHP、SSPP 等服务,后台内部系统异构。
第二,中间件难以复用,没有使用 tRPC 提供的众多中间件及存储生态,而是不同模块、不同小组单独封装,如 rLog、Redis、Errors 等,存在重复造轮子的成本和大量废弃代码的风险,不符合 Less is More 原则。
第三,服务边界不清晰,存量服务过于庞大且耦合,通常有几十甚至上百个接口,多人同时修改一个服务,频繁发布时可能导致夹带他人变更而不自知,不符合 Simple is Best 原则。
第四,目录结构不规范,各形各色的目录结构导致代码可读性极低,不利于团队一致性提升,不能充分利用可观测性手段治理服务可用性及性能。
第五,可观测性利用不充分,存量服务大多接入了天机阁等内部可观测性平台,但在天机阁使用上强依赖 Traces 能力,导致故障定位效率低下、全量上报 Traces 成本高昂,且 Metrics、Logs、告警等能力未充分利用。
但是目前天机阁不对外服务,大家有企业可观测性建设的需求,可以试用腾讯云可观测平台(TCOP):TCOP包含了云拨测 (CAT),云压测(PTS)、前端/终端性能监控 (RUM)、应用性能监控 (APM)、Prometheus & Grafana 服务以及云产品基础监控等多个子产品,经过往几年产品的打磨与积累,在可观测领域已经形成了相对比较完整的产品矩阵,且积累了丰富的行业客户案例。新客户也有免费 15 天试用期。
体验地址:https://cloud.tencent.com/product/tcop
02
tRPC 脚手架工具建设
2.1 trpcx.NewServer()
文档后台封装有通用 tRPC 服务启动工具,读取本机 trpc.yaml 文件,通过 Config as Code 进行服务启动初始化配置加载。该部分代码无需开发自行填写,使用 ./create_app.sh + 模块名 + 服务名,脚本即可自动生成对应所有代码目录、配置文件、启动服务等。
注意,这里服务命名建议遵循 tRPC 命名规范,模块名为 app Name,服务名为 Server Name,均使用全小写字母。例如:文档收集表后台数据统计服务,app 为 formcollect,server 为 formstatistics。为区分各业务与模块的边界,应避免使用 docx 作为 app Name。
2.2 tRPC 插件引入
文档后台开发有多种插件 filter,如:
dyeing:环境路由拦截器。针对 HTTP 请求 cookie 中的环境路由字段设置到 metadata 中,从而将请求路由到指定环境。
trpctelemetry:天机阁 tRPC 插件。针对请求、服务、容器等维度,对 Traces、Metrics、Logs 等数据进行上报和拉取。
telemetryx:Traces 扩展字段拦截器。针对 HTTP 请求和 tRPC 请求分别从 head cookie 和 metadata 中取出 uid、env_id、docid 等业务关注字段,设置到天机阁 Trace Attributes 中。
apiheader:登陆态解析拦截器。针对 HTTP 请求中的文档登陆态、QQ登录态、客户端 IP 等字段填充到 context 的 api.ReqHeader 结构中,透传给下游。
checkLoginStatus:登陆态校验拦截器。针对请求校验用户当前登陆态,通常 CGI 服务都需要引入该插件。
截至目前,通用型必须引入的插件已经统一引入到 trpcx 服务启动中,业务代码中无需重复匿名引用,只需通过 trpcx.NewServer() 即可自动配置通用插件。如业务需要使用自定义插件,可以自行引用。但是目前插件功能过于分散。未来计划将类似功能的插件收敛到统一插件中,如 telemetryx 和 dyeing 插件,其实现都是从 cookie 中特定字段添加到 metadata 中进行扩展上报,收敛后有助于降低使用插件时的心智负担。
2.3 OpenTelemetry yaml 文件创建
遵循 “Git as Code” 和 “可观测性 as Code” 的原则,使用 create_app.sh 脚本默认会根据模块名和服务名创建好服务接入天机阁 GitOps 告警对应的 opentelemetry.yml 文件,在里面可以根据 PromQL 表达式编写具体告警规则。
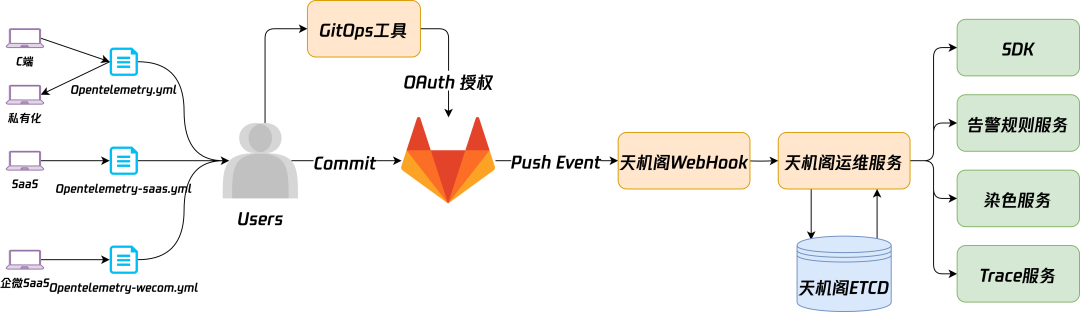
通过监听文档后台工蜂仓库的 Push Event 事件,触发天机阁 WebHook,将子服务目录下对应 opentelemetry.yml 配置文件经天机阁运维服务解析处理后,将最终执行规则存储至天机阁 Etcd 中,最终由运维服务执行如 告警发送、设置错误码特例等。
2.4 规范目录结构生成
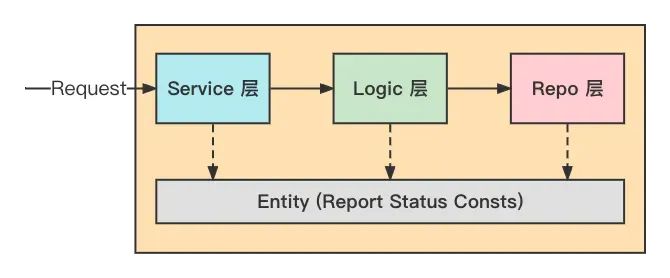
基本原则:高内聚、低耦合。
Service:代码入口层。不耦合业务逻辑,仅做对外接口的封装和提供。Logic:业务逻辑层。与对外接口和外部依赖以及开发框架解耦的纯业务逻辑层。Repo:网络依赖层。外部 RPC 调用/读写 DB/远程配置/中间件 等第三方网络依赖层。
使用 tRPC 脚手架,自动生成对应代码目录规范,无需手动创建目录结构,直接根据对应的服务 PB 编写业务逻辑代码。
03
文档天机阁租户降本增效
为解决业务可观测性数据存储 ElasticSearch 的高成本痛点、满足用户降本增效的诉求,经天机阁团队和云观(可观测性标准和工具)Oteam 联合研发,提供了天机阁 ClickHouse 版本。天机阁腾讯文档 tdocs 租户积极响应公司号召,于2022年7月将底层存储从 ElasticSearch 迁移至 ClickHouse。
3.1 ClickHouse优势
ClickHouse 优势在于,批量写入吞吐量高,压缩率高,尤其适合 Traces、Logs 这类写多读少的场景、且数据只写入不更新,对于删除只需要过期时批量删除。
3.2 存储迁移节奏
2022年7月5日-7.10日为灰度验证阶段,从 ElasticSearch 集群复制 10% 流量,用来灰度验证文档租户数据压缩比与成本核算。2022年7月11日-7.15日为全量复制阶段,Traces 和 Logs 数据复制流量双写至 ElasticSearch 和 ClickHouse 集群,便于研发同学提前熟悉适应 ClickHouse 的类 SQL 查询语法和规范使用姿势。2022年7月16日以后为完成切换阶段,将下掉 ElasticSearch 集群,全面拥抱 ClickHouse 存储,以更低的成本、更强悍的性能,为研发效能的提升赋能。
3.3 文档租户数据计算
灰度验证阶段数据统计结果如下:

文档的 Traces 压缩比是 7:1,当前一天 433TB 数据,按 450TB 计算,保留 7 天,需要 7~8 天的空间 3600TB,压缩后是 515TB。文档的 Logs 的压缩比是 11:1,当前一天 26TB,按 30TB 计算,保留 7 天,需要 7~8 天的空间 240TB,压缩后是21.8TB。高性能型 ClickHouse 每个节点 7TB SSD,大存储型 ClickHouse 每个节点43TB SSD,但由于腾讯云高性能型资源不足,不便于后续水平扩容,因此选用大存储型。32C 每天大约可以支撑 10~15TB 写入量,预计需要 45 节点左右。相比原来的 ES 90 节点降低约一半成本。为了给查询预留 CPU Buffer,同时为 Logs 放量提前预留空间,最终选择 50 节点 ClickHouse 集群。
3.4 落地效果对比
Traces、Logs 原始上报数据量对比:

ElastisSearch、ClickHouse 集群资源对比:

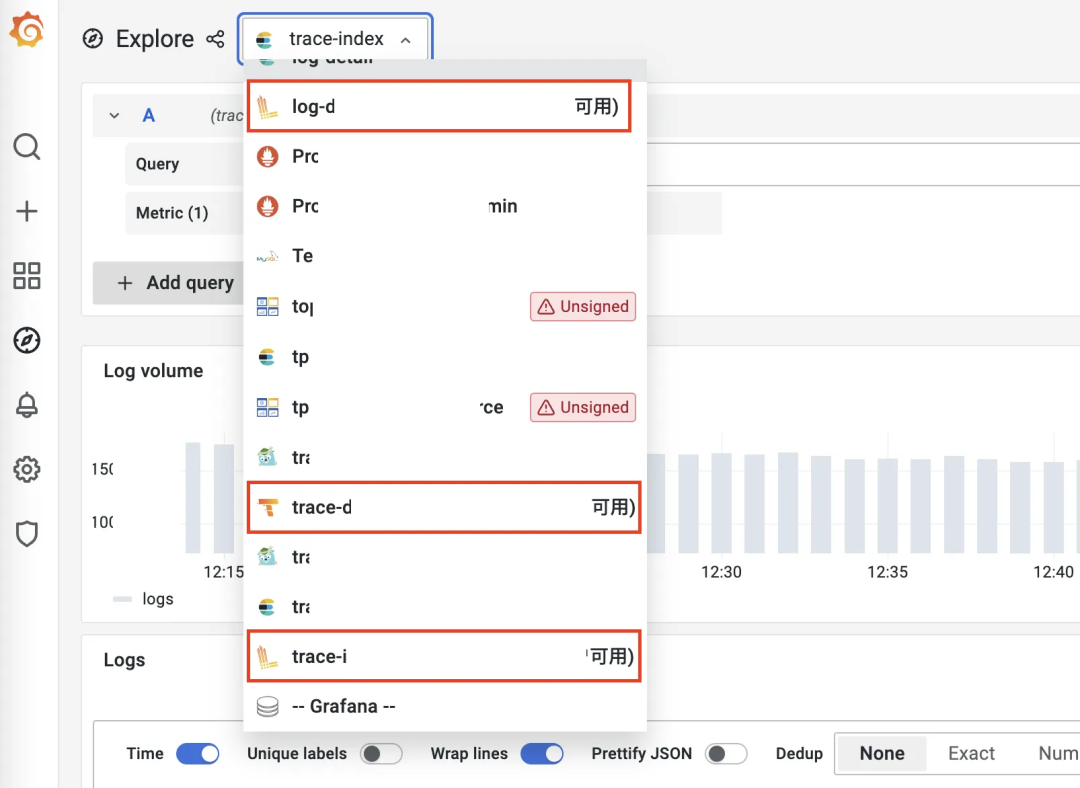
查询时使用 ClickHouse 数据源:
04
可观测性最佳实践
4.1 可观测性是什么
可观测性起源于自动控制理论,它是指系统可以由其外部输出推断其其内部状态的程度。最早来自于电气工程领域,主要原因是随着系统发展的逐步复杂,必须要有一套机制用来了解系统内部的运行状态以便更好的监控和问题修复,为此工程师们设计了很多传感器、仪表盘用于表现系统内部的状态。其定义是,如果仅使⽤来⾃输出的信息(即传感器数据)可以估计当前状态,则系统被认为是“可观测的”。
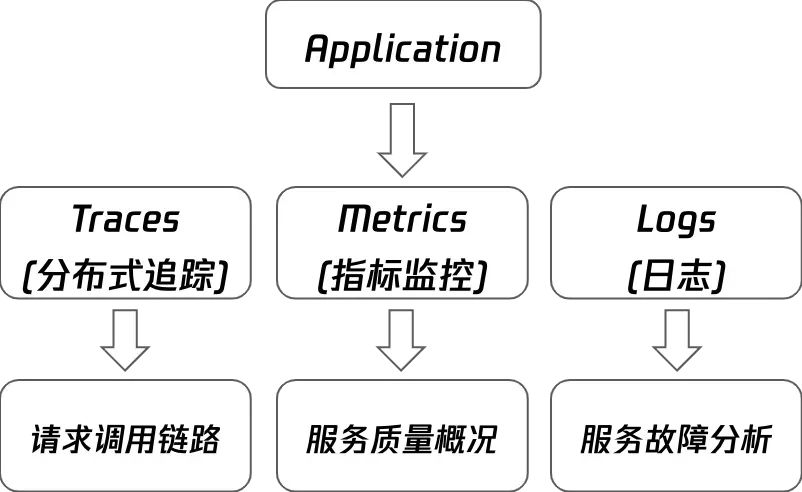
那么对于软件分布式系统,例如微服务、Serverless、ServiceMesh 等中,可观测性系统将输出遥测(telemetry)数据,主要是跟踪数据(Traces),指标数据(Metrics),日志数据(Logs)来观测分布式系统状态的能力。
4.2 三大数据模型
Traces:分布式追踪,提供了一个请求从接收到处理完成整个生命周期的跟踪路径。可以跨进程、跨网络和跨安全边界。例如,前端发送 HTTP 请求开始,所经过的所有下游服务,最终根据 traceID 串联起来形成一条完整的请求链路。
Metrics:指标监控。指标是⼀种可累加的聚合的数值结果,具有原⼦性。例如,经常说的 QPS、TPS、SLA 都是计算后得到的 Metrics;基础设施中的 CPU 使⽤率、负载情况、内存占用率等也可以认为是 Metrics。
Logs:服务日志。在特定时间发⽣的事件,被以结构化的形式记录并产⽣的⽂本数据。⽇志可以为本人们展现系统在任意时间的运⾏状态,又因为它是结构化的⽂本,所以本人们很容易通过某种格式来进⾏索引。
4.3 OpenTelemetry 是什么
OpenTelemetry is a collection of tools, APIs, and SDKs. You can use it to instrument, generate, collect, and export telemetry data (metrics, logs, and traces) for analysis in order to understand your software's performance and behavior.
可观测性指应用程序通过输出信号来观测理解系统内部状态的一种能力。目前实践中主要提供以上三种信号(Signal) 。
4.4 天机阁与 OpenTelemetry 关系
天机阁作为公司内部优秀的云原生可观测性平台, 基于业界 CNCF OpenTelemetry 标准, 旨在打造标准化的云原生可观测性基础设施及服务。目前平台已稳定服务公司内180+业务, 提供万亿级数据的可观测支撑能力。
4.5 目前不规范实践
4.5.1 业务查问题强依赖 Traces
使用姿势不规范,业务查问题强依赖 Traces,通常前端/测试提供给到 traceID 信息,然后直接根据 trace-detail 查询,由于未根据索引检索导致查询时间缓慢;完整链路检索出的瀑布图过长,甚至部分服务达到上万+ span,定位过程变得肉眼检索且不可控。

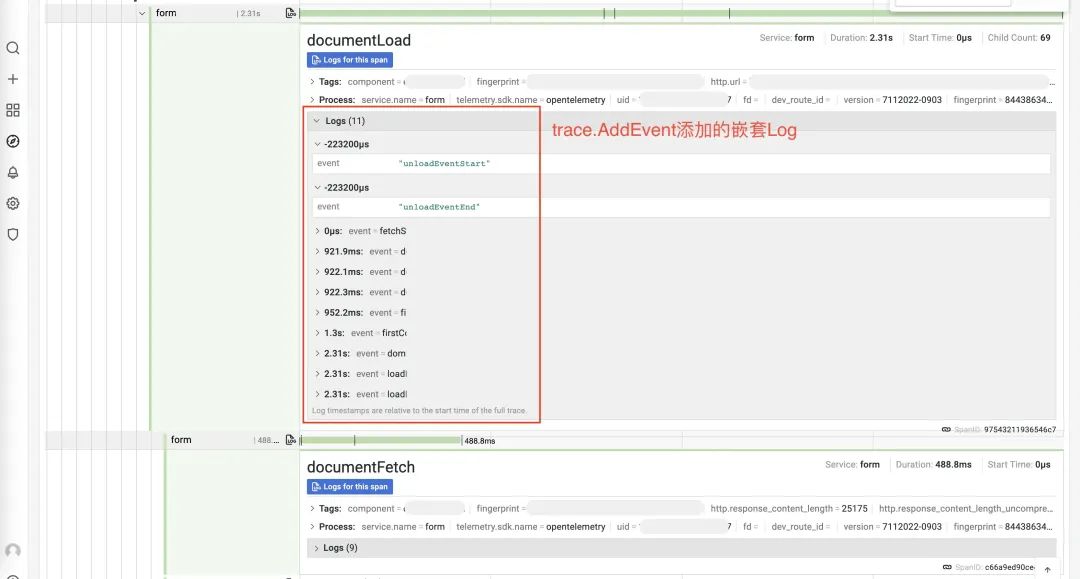
4.5.2 Traces 嵌套过多冗余 Logs 信息
使用 rLog 或 trace.AddEvent() 把日志嵌套在 Traces 中,导致 Traces 过长,存储至 ClickHouse 压缩比也随之下降。同时 rLog 仍会将数据写到天机阁 log-detail 中,数据双写导致成本上涨。
4.5.3 未充分利用 Logs 进行故障分析
目前 Traces 流量是 Logs 的近 20 倍,这是不健康的落地存储方式,反映出服务普遍没有使用标准 tRPC-Log。
4.5.4 未充分利用 Metrics 监控告警主动发现问题
Metrics 监控顾名思义,是帮助开发同学根据服务运行时的概况进行主动的问题发现,能够让开发一切尽在掌握,如主被调的成功率、异常率、超时率,容器维度的协程数、GC、健康状态等。同样,基于监控的告警可以在异常时通知到服务负责人。
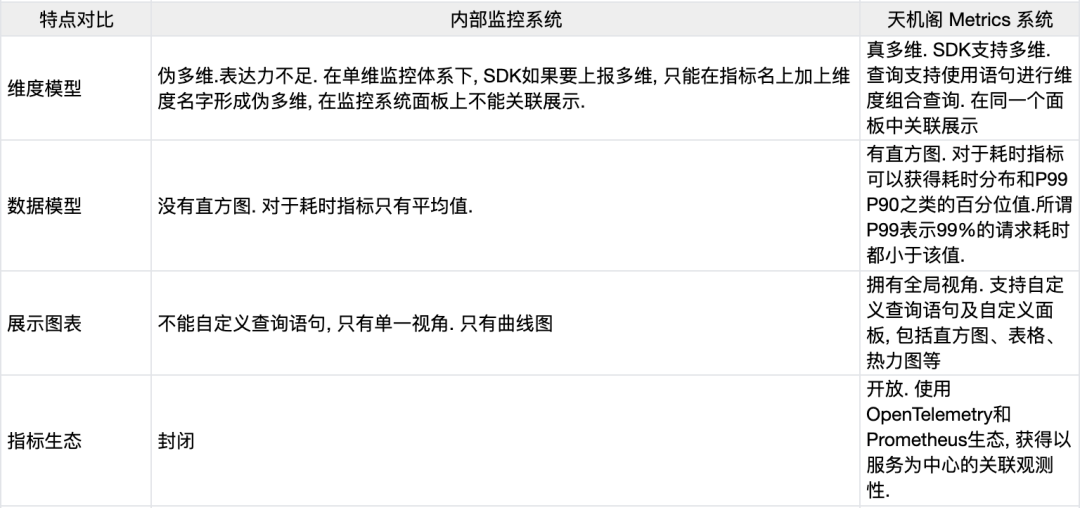
4.5.5 不理解 Traces Logs Metrics 的区别和作用
Traces 可以帮助进行分布式追踪梳理上下游调用链路和架构治理,Metrics 可以帮助根据服务概况发现问题,Logs 可以帮助进行故障定位和根因分析。
4.6 服务接入
目前后台 tRPC 脚手架中已默认集成天机阁 opentelemetry.yml 文件,且天机阁2.0(tpstelemetry) 工蜂公共账号加为文档后台大仓 docx-online 项目组 Reporter 权限,同时设置webhook地址为 http://gitops.tpstelemetry.woa.com/webhook?match_pattern=opentelemetry.yml 表示匹配完整文件路径名为 opentelemetry.yml 的文件,不限目录。
业务在接入过程中,无需修改任何配置,即可自动接入天机阁 GitOps 能力,后续有新增告警项或错误码特例,均可直接在项目 yaml 文件内做修改。需要注意 opentelemetry.yml 文件中的 app 和 server 需要和 trpc.yaml 中保持一致。
opentelemetry.yml 定义例子-最小集简洁版:
version: v1 # 版本, 不同版本对应下文解析格式不同
owners:
- name: rtx_name_1 # 告警接收人用户名
- name: rtx_name_2 # 告警接收人用户名
resource:
tenant: tenantName # 请改为服务对应的租户
app: appName # app
server: serverName # server
cloud:
provider: provider
platform: "platform"
alert:
items:
- alert: 主调异常率>5% # 标题
metric: client_request_exception_rate_percent # 系统定义的告警项, 参考见表格
type: max # type 告警类型
threshold: 5 # 告警阈值 数值
- alert: 被调异常率>5%
metric: server_handled_exception_rate_percent # 系统定义的告警项, 参考见表格
type: max
threshold: 5
- alert: 主调请求量5分钟波动百分比>70%
metric: client_request_count # 系统定义的告警项, 参考见表格
type: wave
threshold: 70
- alert: 被调请求量5分钟波动百分比>70%
metric: server_handled_exception_rate_percent # 系统定义的告警项, 参考见表格
type: wave
threshold: 70
- alert: 小卡不成对被过滤>5 # 标题
metric: "小卡不成对被过滤" # 自定义上报的属性名. 属性上报代码示例 metrics.IncrCounter("小卡不成对被过滤", 1)
type: max
threshold: 5
metric: # 错误码特例
codes:
- code: 0
type: success
description: "成功"
- code: 200
type: success
description: "成功"
- code: 1001
type: exception
description: "鉴权异常"
- code: 9999
type: timeout
description: "请求超时"
service: # 不为空表示错误码特例仅匹配特定的 callee_service, 为空表示所有 callee_service.
method: # 不为空表示错误码特例仅匹配特定的 callee_method, 为空表示所有 callee_method.天机阁告警规则现已全部收敛至 GitOps 告警,将全局告警规则托管至 Etcd 废除掉,如租户想修改自己租户下的全局规则,可以自行修改并只应用于当前租户下全局服务。

如有服务下线,需要下线所有监控告警项,不可以删除对应 yaml 文件,在保留文件的同时将所有 items 项规则删除即可去除告警。
4.7 基于监控进行根因分析
以收集表后台 docx.formcollect 服务为例。服务有现网请求后,通常需要保持一段时间观察,尤其在前端放量和后台发布期间, 由于新老逻辑的切换可能导致现网用户受到影响。天机阁提供有全面的多维度看板,包括有开发、测试、运维、产品、运营、技术负责人等多方位视角,全面观测业务质量。
我们以收集表后台为例,利用天机阁Metrics监控能力分析现网业务情况。Metrics更关注系统级别的高效指标而不是单个请求级别,不要在Metrics中放过多的细节label,单独Metrics无法解决所有的可观测性问题,详细的信息应记录Logs和Traces中,或者在Exemplar带上traceID,充分利用三大信号 Metrics/Logs/Traces 关联 一起来观测系统。
首先,从首页进入,通过筛选框选择对应服务,点击监控链接跳转至监控视图看板;
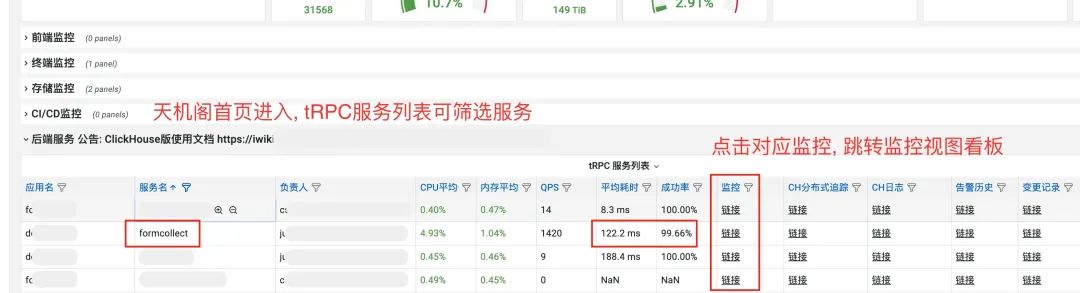
其次,监控视图中,有各个维度针对该服务的所有监控,全部由天机阁 tRPC 插件完成监控上报,业务无需进行任何改造,按上述接入方式接入插件即可;

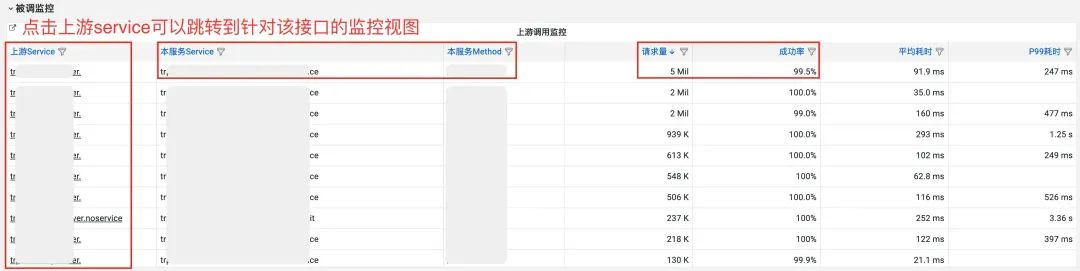
基础信息监控:从服务整体角度,节点数、CPU 核数、内存总量等;版本监控:Go、tRPC、天机阁插件等版本信息;进程监控:容器维度进程监控,CPU 和 MEM 使用率,重启次数等;运行时监控:程序运行时维度监控,协程、线程、GC 耗时、Panic 次数;主调总览+主调监控:我调下游服务监控;被调总览+被调监控:上游服务调我监控;SDK 上报监控:traces、logs 上报队列成功率、丢失率;自定义指标监控:业务代码使用 tRPC-Metrics 或原生 Prometheus 方式自定义指标上报监控。
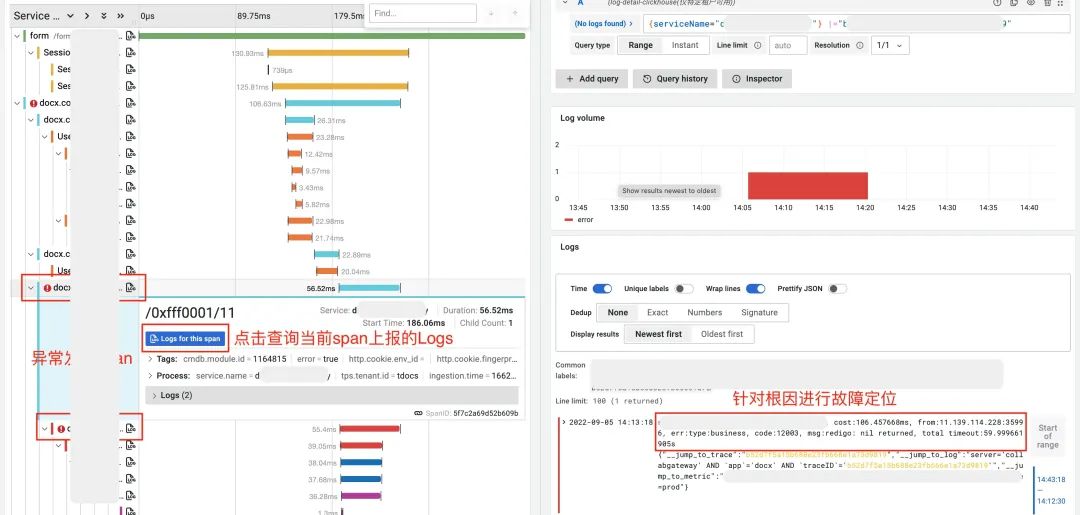
再次,以某现网请求量最大的接口为例,当我们在被调监控中发现,/0xfff0001/11(Recordcnt)接口成功率仅有99.5%,不符合我们3个9成功率的 SLA 后台可用性. 那么针对该接口进行深入分析:
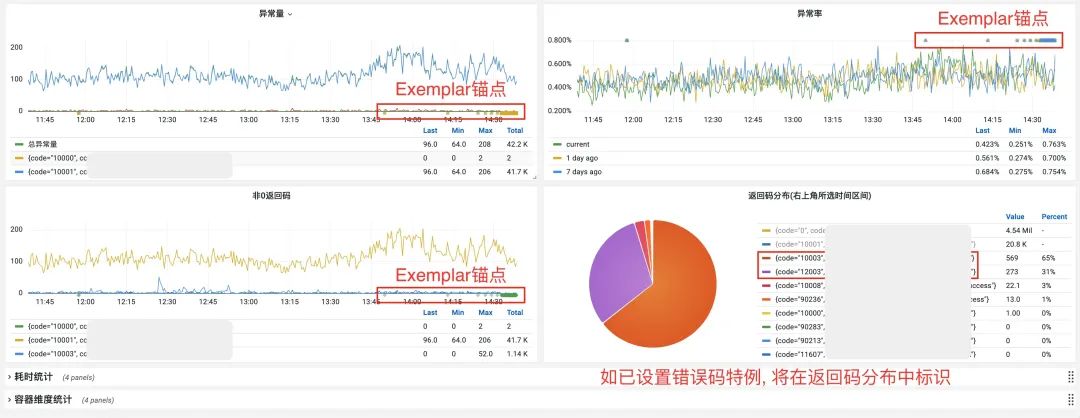
然后,在接口维度的被调监控中,所有默认监控进行了 Exemplar 锚点,可以简单理解为,在实现从 Metrics 关联到 Traces 时,将 traceID 塞入了 Prometheus Metrics 中的 Label 中。
另外,最终实现的效果是,如下图,我们可以根据 Exemplar 锚点,直接跳转到错误 code 为12003的异常请求上,看到其具体 trace detail, 找到最终发生异常的 span 环节,定位到错误发生的环节。
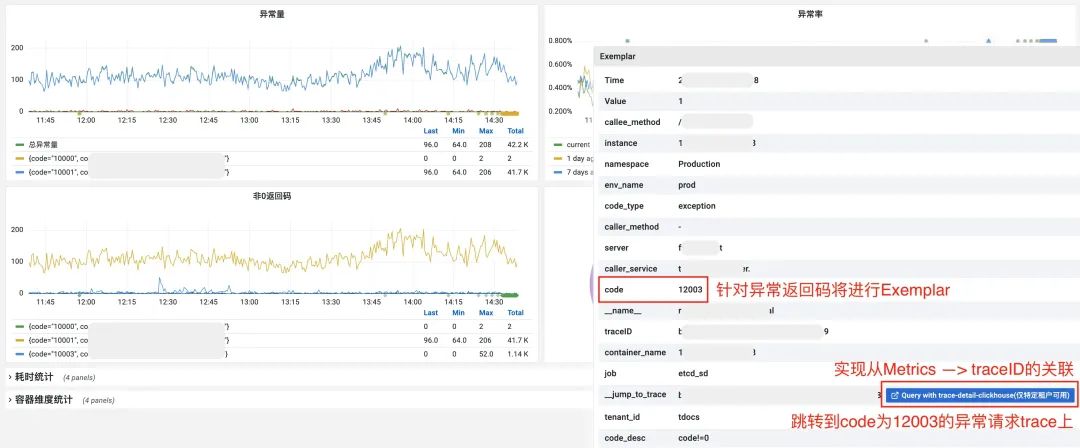
最后,在找到异常发生环节后,可以根据 Logs for this span,自动定位到具体环节上报的日志,通过日志信息辅助进行故障定位、根因分析,最终找到故障发生的最终原因为,从 Redis 获取数据值为空。
4.8 排查现网问题正确姿势
首页服务列表提供超链接,点击自动拼接服务名查询条件。
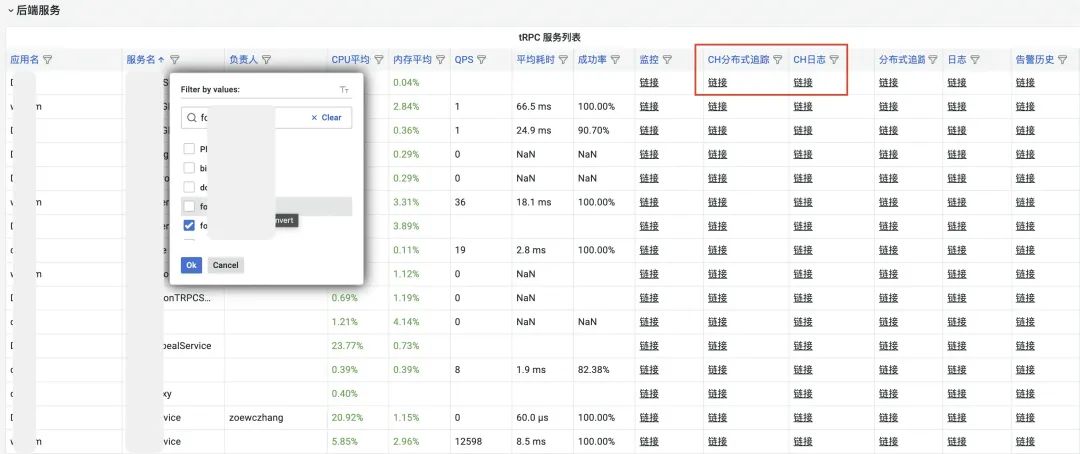
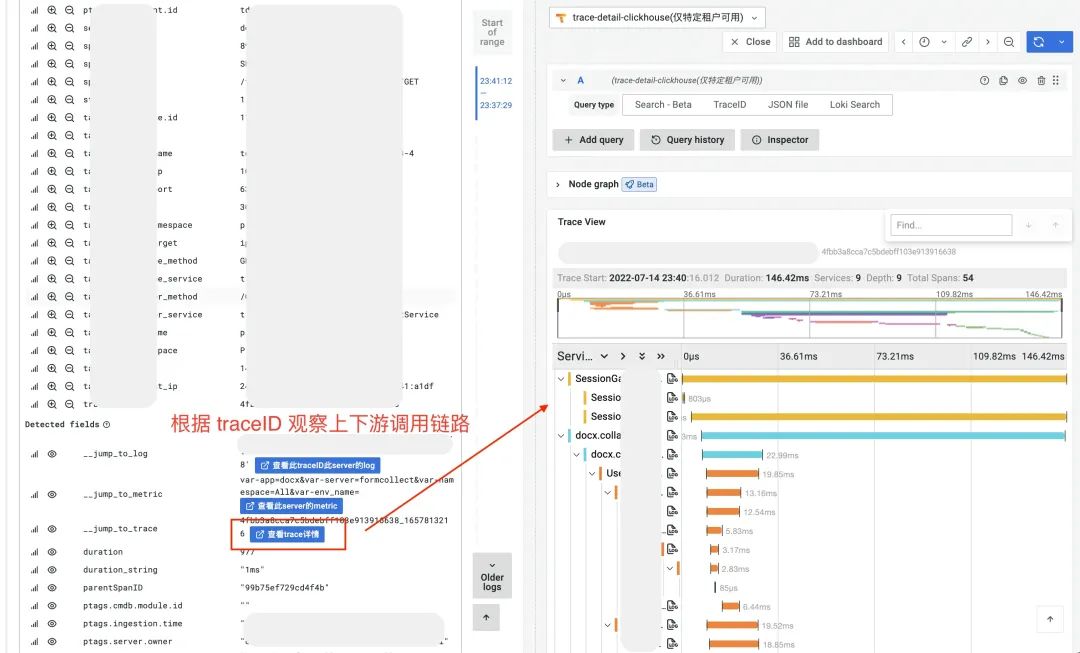
方法1:根据 trace-index —> trace-detail 观察服务调用链路上下游
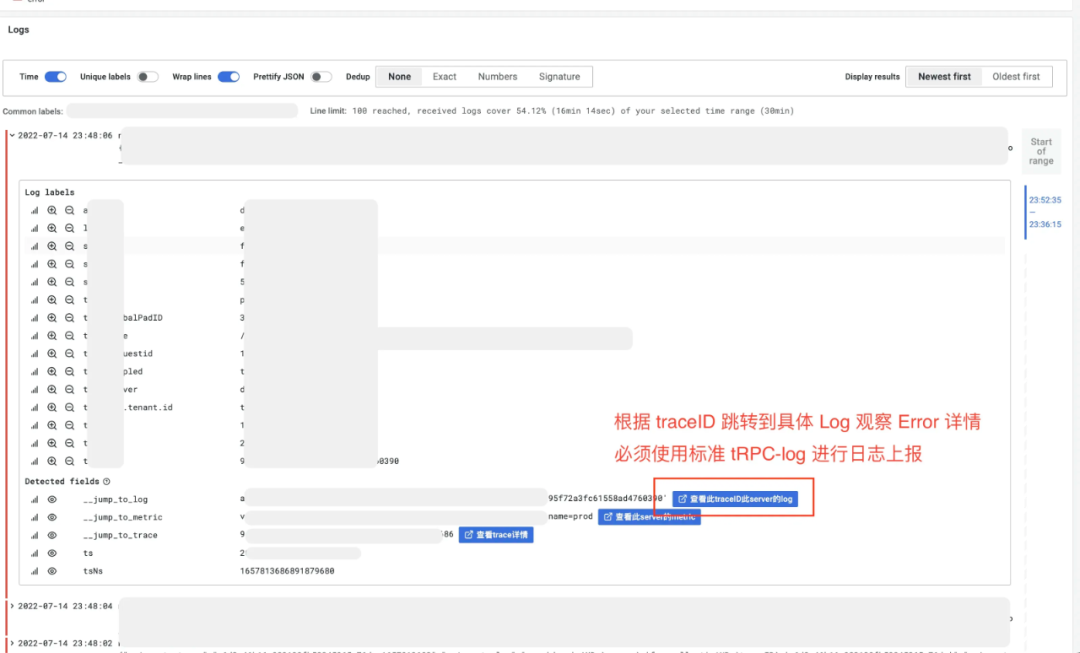
方法2:根据 trace-detail —> log-detail 观察此 traceID 在此 server 的 log
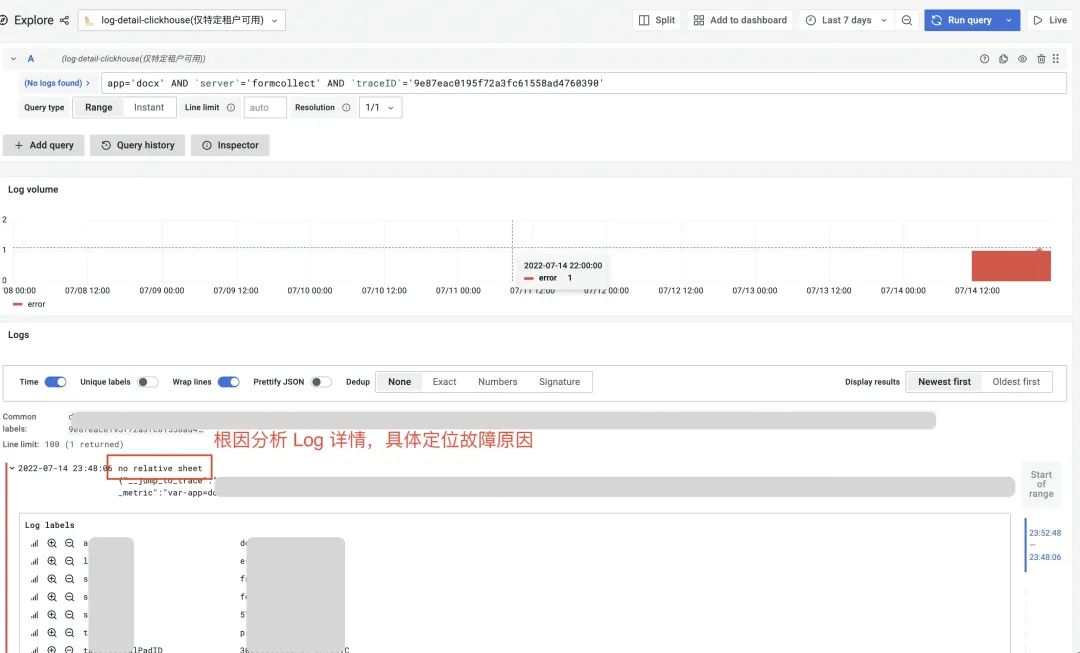
方法3:直接查询 log-detail 数据源,根据 uid 查询用户所有请求日志并观察
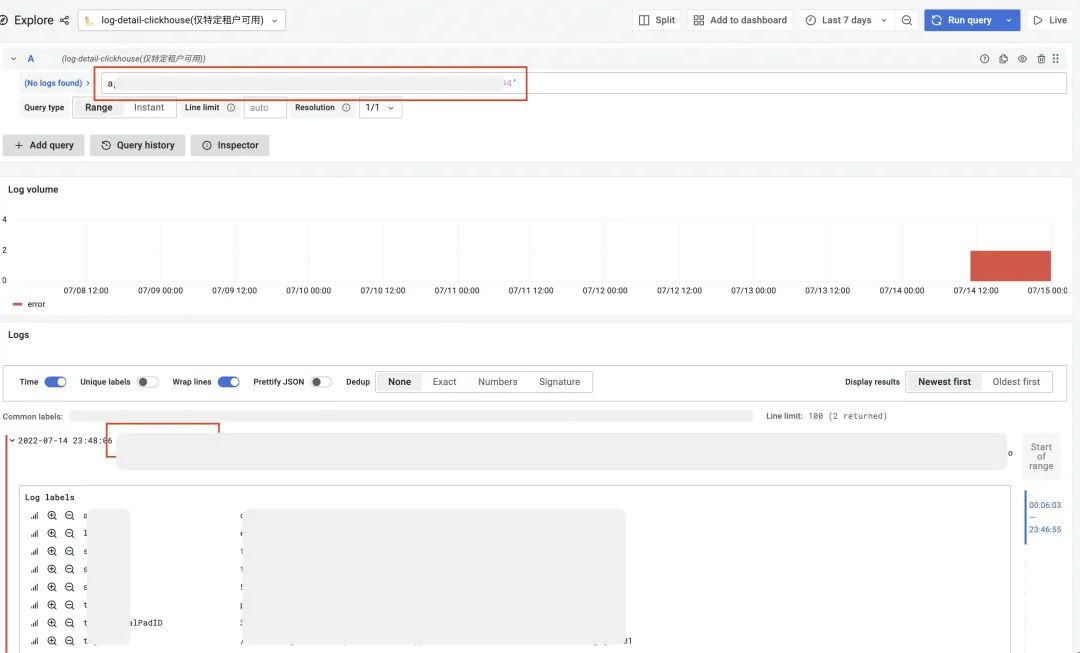
场景1:用户反馈 Bug,运营同学拉群给到 traceID,根据 traceID 定位到具体服务问题出现 server 后,根据 server 和 traceID 查询 Log-detail,使用方法1+方法2。场景2:用户反馈 Bug,运营同学拉群给到 uid,根据 uid 检索用户在问题时间段内请求日志,根据 message like 或 error 检索到对应的错误日志,使用方法3。
-End-
原创作者 | 张瀚元
后台服务治理中,如何提升可观测性?有哪些意识和工具推荐?欢迎评论留言。我们将选取1则优质的评论,送出腾讯Q哥公仔1个(见下图)。4月9日中午12点开奖。
📢📢欢迎加入腾讯云开发者社群,享前沿资讯、大咖干货,找兴趣搭子,交同城好友,更有鹅厂招聘机会、限量周边好礼等你来~
(长按图片立即扫码)

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









