







👉目录
1 面临问题
2 接口管理平台建设
3 接口生命周期治理
4 面向未来-技术债务的 AI 时代
腾讯新闻经过这几年的重构、服务下线、服务合并等处理后,目前遗留了大量的历史接口。腾讯新闻对端的接口没有完善的规范,文档分散在 iwiki、腾讯文档、yapi,没有使用统一的平台进行自动化的管理。客户端、前端开发环境迫切需要 Mock 能力,只能通过本地工具进行 Mock,没有办法在远程接口进行 Mock。这些问题降低了研发效率,存在大量人工沟通成本,因此针对我们业务当中遇到的这些问题进行了治理,取得不错的成果,另外也比较深入思考了如何使用 AI 来治理技术债务,借此机会分享给大家,也希望大家的业务通过我们的经验给大家带来一些帮助和思考。
关注腾讯云开发者,一手技术干货提前解锁👇
01
面临问题
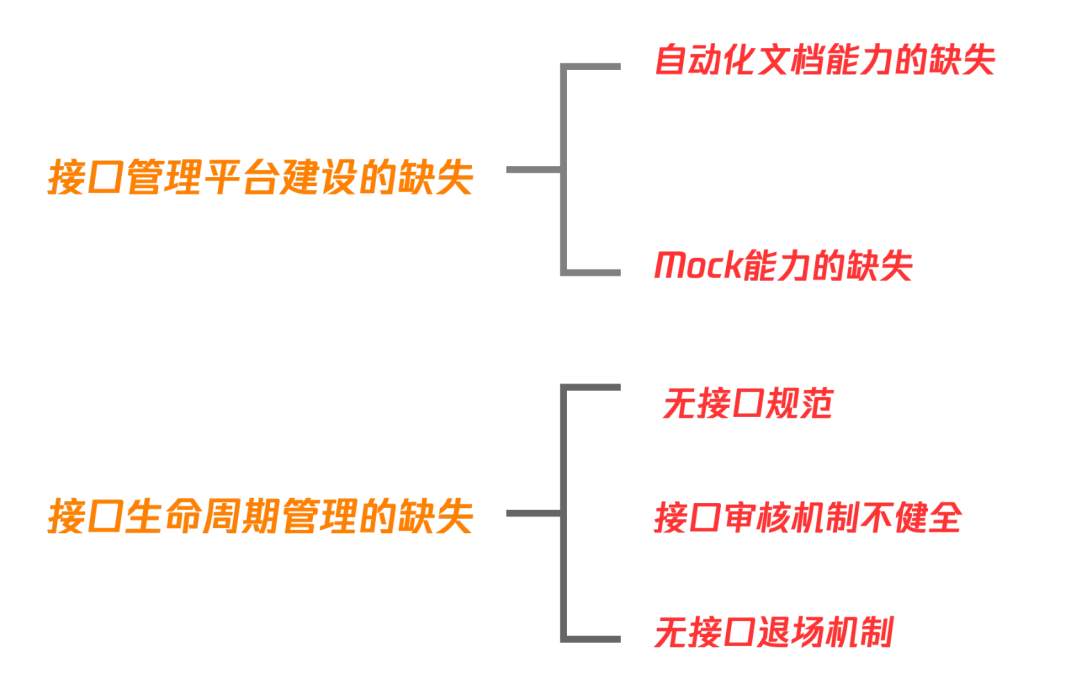
1.1 接口管理平台建设的缺失
1.1.1 自动化文档能力的缺失
协议变更沟通效率低:协议对接通过人工沟通的方式进行,人工沟通方式不仅效率低,还容易出错,比如:字段类型约定是 int,但是实际下发是 string 导致一些问题的发生。给客户端协议确认带来了极大的不便,如果服务端对字段进行下线那么需要人工找对应的负责人进行确认,
无统一文档格式: 文档有的存在于 wiki、有的存在于 yapi 或者腾讯文档,没有使用统一的平台进行自动化的管理, 导致使用方需要在不同地方查询。
人工手动同步文档:大部分接口无新增字段、后续的维护基本处于缺失的状态,协议只在创建的时候是最全的、最完整的。
1.1.2 Mock 能力的缺失
目前的 Mock 方式是以客户端在本地通过 ProxyMan 其它工具进行 Mock,这样做的最大的问题是 Mock 不能共享、不够灵活。
示例: 客户端接到需求只是针对页面进行调整,可是这种页面只有在特定返回的数据中才有,这时候就需要 Mock 能力,相对于把返回结果硬编码到 App 包中,我们可以通过实时接口 Mock 更加灵活的控制结果,另外也可以将 Mock 返回给对应的客户端。
1.2 接口生命周期管理的缺失
1.2.1 无接口规范
没有规范就无法做到标准化,没有标准就会影响整个团队的协作效率。
接口、协议管理规范没有建立,接口随意创建,有的使用 Restful 风格、有的是自定义的风格;没有接口版本控制机制;字段名称惯例不统一等等问题。
1.2.2 接口审核机制不健全
审核机制不健全,部分服务没有开启审核机制,协议变更后可饶过审核,没有经过两级(服务内部和网关)审核,导致协议可以随意修改。
1.2.3 无接口退场机制
接口无退场:整个服务的接口一直处于熵增的状态,共计1300+个接口,没有有效的机制及时确认删除。除此外,服务大量的重构在新闻的网关存在大量 Mock 返回的线上运行接口。
02
接口管理平台建设
2.1 平台调研与选型
基于接口文档的使用习惯、管理方式我们调研了相关平台。
2.1.1 Swagger
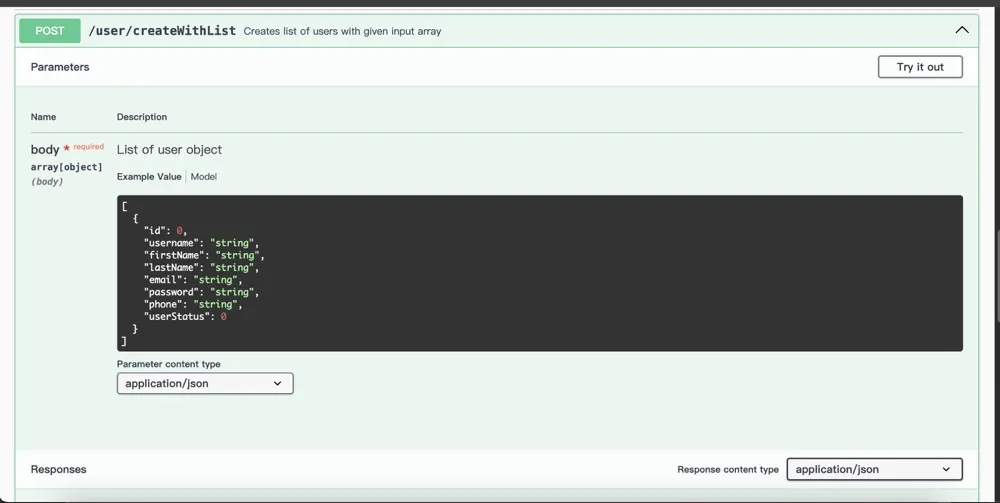
演示地址:https://petstore.swagger.io/#/user/createUsersWithListInput
维护方式:
代码注释生成方式,支持自动导入。
维护支持 json, yaml 配置。
优势:
Swagger UI 可以展示文档。
可以在页面触发接口请求,观察接口响应。
劣势:
展示页面简单、页面丰富度不足。
公司内部暂时没有平台,需要自己搭建。
接口测试工具简单:不支持 mock,不能存储测试用例。
2.1.2 YAPI
维护方式:
支持 OpenApi 3 json, yaml 配置。
支持平台维护。
通过流水线可根据代码注释生成配置。
优势:
较为完善平台交互页面。
支持权限管理。
支持 mock:动态化 mock 能力、支持高级 mock(根据参数动态 mock)。
数据同步,支持自动合并(具有平台修改、配置同步能力)。
暂无成本分摊。
劣势:
功能相对简单:只有文档编辑和 mock 能力,没有基于接口压测功能,平台化能力不够完善。
2.1.3 结论
学习成本:由于组内、开发人员有一些已经使用了 Yapi 平台,学习 Yapi 平台成本是最低的。
服务成本:可以使用 CSIG 部门提供的 Yapi 服务,维护成本低。
迁移成本:因为之前有部分接口已经在使用 Yapi 平台,因此 Yapi 的迁移成本这个是最低的。
使用场景:新闻团队的核心诉求是文档和 Mock 能力,其它的不是必选项。
综合新闻内部开发人员以前的使用习惯、目前使用场景、服务成本、迁移成本考虑以后,最终选用了 Yapi 来管理整个服务。另外如果后续不满足我们的需求,可以进行较低成本的平台切换,因为每个平台都支持 swagger 格式的协议同步,只不过不同平台对使用者有一定学习成本。
2.2 Mock 能力建设
在平台上 Mock 的优势:
Mock 数据共享:Mock 的期望数据可以在不同的开发人员中共享,提升开发人员的效率。
方便自动化测试:提供对端的接口 Mock,可以很方便的做一些 APP、前端的展示自动化测试用例。
方便非开发人员验证:我们可以 Mock 好数据,提供给 PM、测试验证前端功能,无需硬编码。
在确定使用 Yapi 平台后,接下来是如何满足客户端开发人员的 Mock 能力。我们根据客户端的需求,开发了基于网关的 Mock 插件。
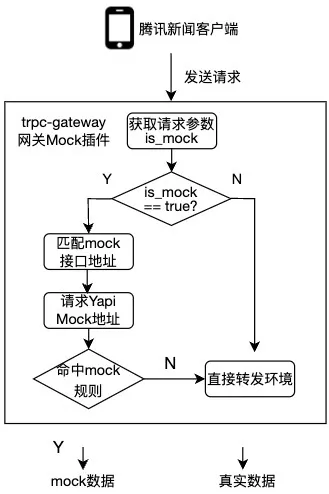
核心策略:
在网关插件中构建 Mock 地址和实际请求地址的映射关系,客户端无需感知请求接口与 Mock 地址关系,实现自动关联能力。
客户端开启 Mock 后才会请求到对应到 Yapi Mock 地址,没有命中 Mock 规则则会请求到实际地址。
2.2.1 YapiMock 能力优化
针对客户端、前端使用体验,对 Yapi 中的 Mock 能力返回进行一些优化。
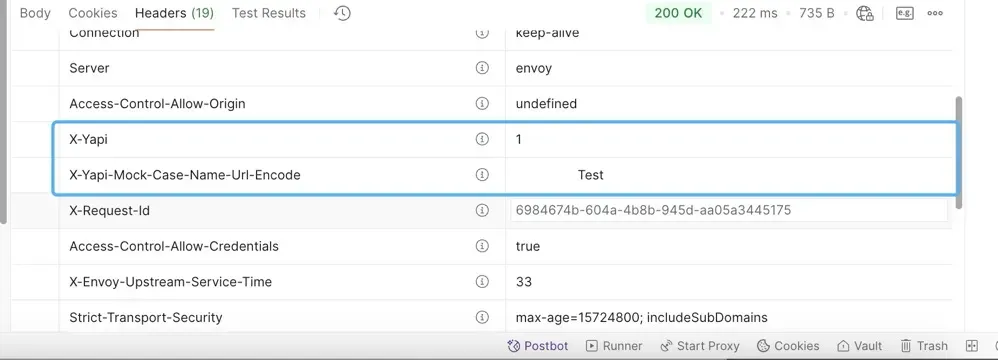
1、命中 Mock 规则自动在 Header 返回对应规则的名称,方便开发人员识别:
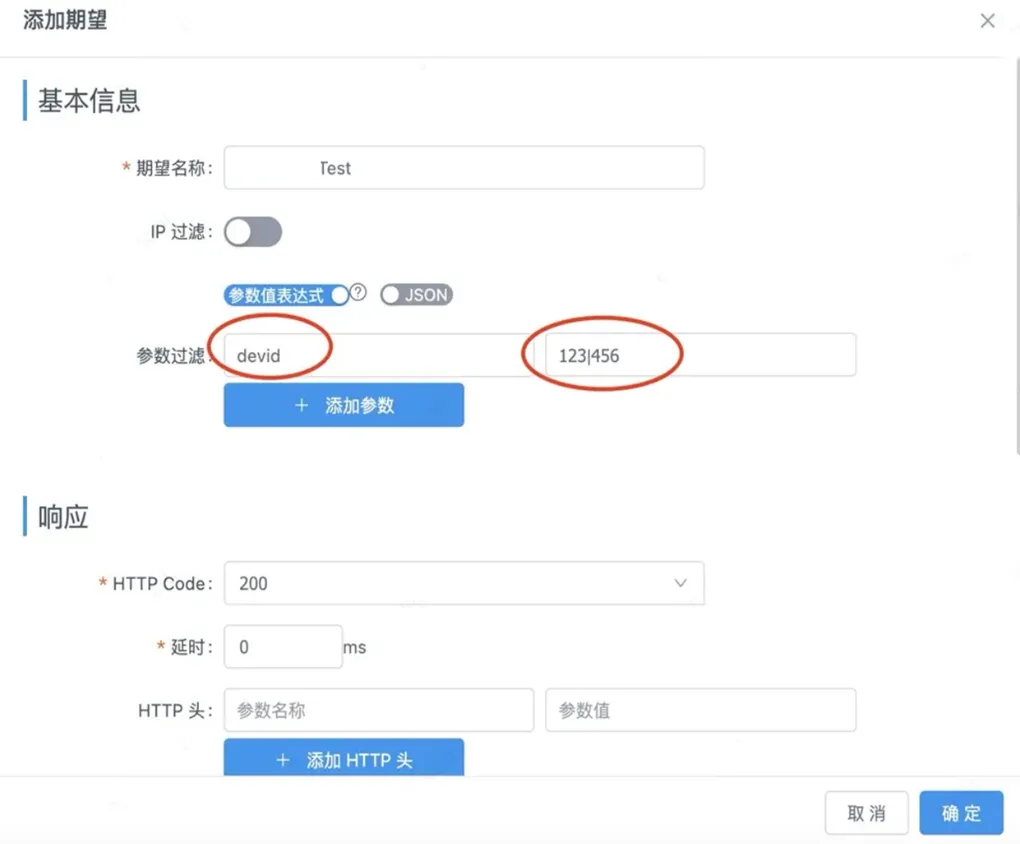
2、支持参数列表的 Mock 能力,方便开发人员对接口的 Mock:
之前的 Yapi 能力,无法支持一个参数或条件,如果这样做只能创建多个期望,操作成本过高,因此支持了参数列表能力,开启后参数可以用|分割,只要参数命中一个就认为该参数符合条件。
2.3 自动化文档能力建设
开发人员需要人工手动维护接口协议,导致协议、文档无法自动更新,客户端等使用方无法以 Yapi 协议为准,来确认协议维护状态、对新人的学习使用成本比较高。目标是通过自动化的形式,低成本实现接口自动化更新能力,尽可能减轻开发人员维护成本,形成可持续长期接口文档化机制。
trpc 的官方工具 trpc-cli 提供了 PB 转换机制,可以基于 trpc 转换,但是在实际的同步过程中,也遇到了一些问题。例如:在 PB 的同步当中如何将项目进行关联?如何对同步的方法进行修改等?还有新闻的一些项目由于一些原因使用的结构体定义的返回结果,如何对结构体进行无感知自动同步?一系列的问题,给自动化文档的搭建带来了不少的挑战。
通过自动化能力的搭建:
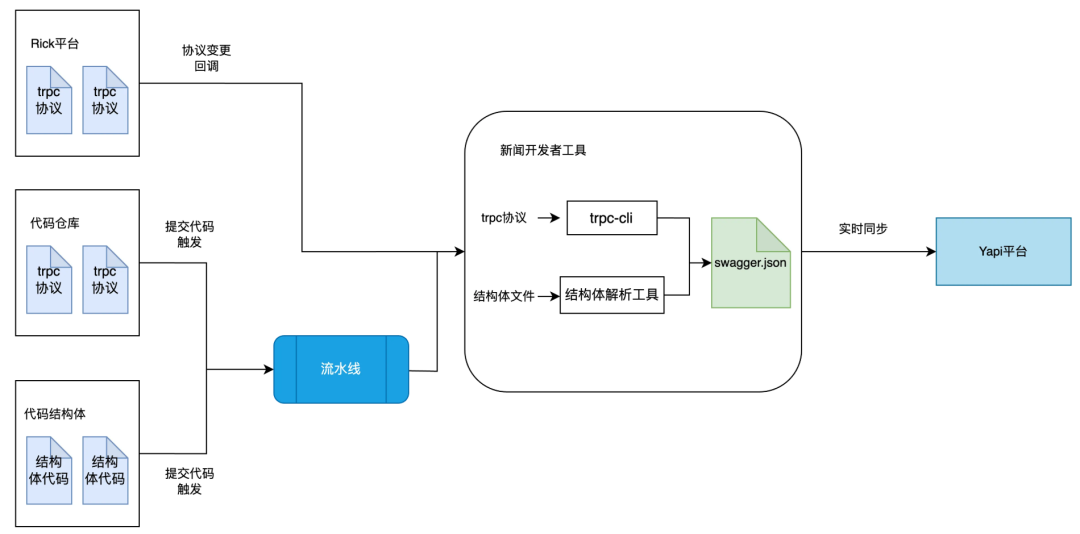
2.3.1 PB 自动化同步
问题:
如何将代码仓库中的 PB,rick 平台中的 PB 自动化同步到对应 Yapi 平台里?
如何做一些定制化的操作,例如:增加接口分类、增加接口路径别名、增加接口请求方法等。
Rick 同步:
通过 Rick 平台(PB 管理平台)选择服务生成,触发回调方式进行同步。回调到我们的一个工具服务触发执行 trpc-cli 工具生成 swagger.json 文件,调用 Yapi 同步接口,同步 Yapi 当中。
PB 仓库同步:
我们有一些协议在代码当中的仓库维护,通过提交协议变更时的流水线,执行 trpc-cli 工具生成 swagger 调用 Yapi 同步接口同步 Yapi 当中。
定制化
因为 trpc 的接口默认支持 Get、Post 请求,如何自动同步中知道该接口的请求方法呢?整体思路通过类似于 trpc tag 的形式对接口名称、接口方法、接口分类进行自定义。
service Test {
// @alias=/sports/Medal @yapi-tags=列表分类 奖牌榜 @yapi-method=get
rpc Medal (Request) returns(Response);
}这里我列出了支持的 yapi 同步相关的 tag:
@yapi-ignore=1 忽略该接口,不会将改接口同步到 Yapi
@yapi-summary= 接口在 Yapi 中的标题
@yapi-tags= 接口在 Yapi 中的分类
@yapi-method= 接口指定的请求方法,trpc 默认会生成协议中 method 的 Get 或者 Post 请求,因此需要指定对端的请求方式
@yapi-path= 实际接口路径,如果对接口别名和客户端接口不同,可以使用这个进行改写。
@yapi-required= 指定参数为必须。
这样可以在修改 PB 时候直接对接口文档相关属性进行修改,无需再进行跨平台操作,介绍开发人员操作路径。
2.3.2 结构体协议自动化同步
我们有小部分的核心服务使用了结构体在服务中进行定义了返回、请求数据,如果我们推动服务进行改造、改造成本比较高。希望有个灵活的工具,能把结构体转换成 swagger.json,也调研了一下开源的swaggo,工具很强大,但是是基于注释实现的,而且注释的配置有一定的学习成本。
根据内部的诉求想基于一个配置的 json 只需要:指定接口名称、接口方法、接口备注、请求返回结构体,这样管理起来更加方便清晰。
因此我们实现了一套类似 swaggo 简单的解析工具:
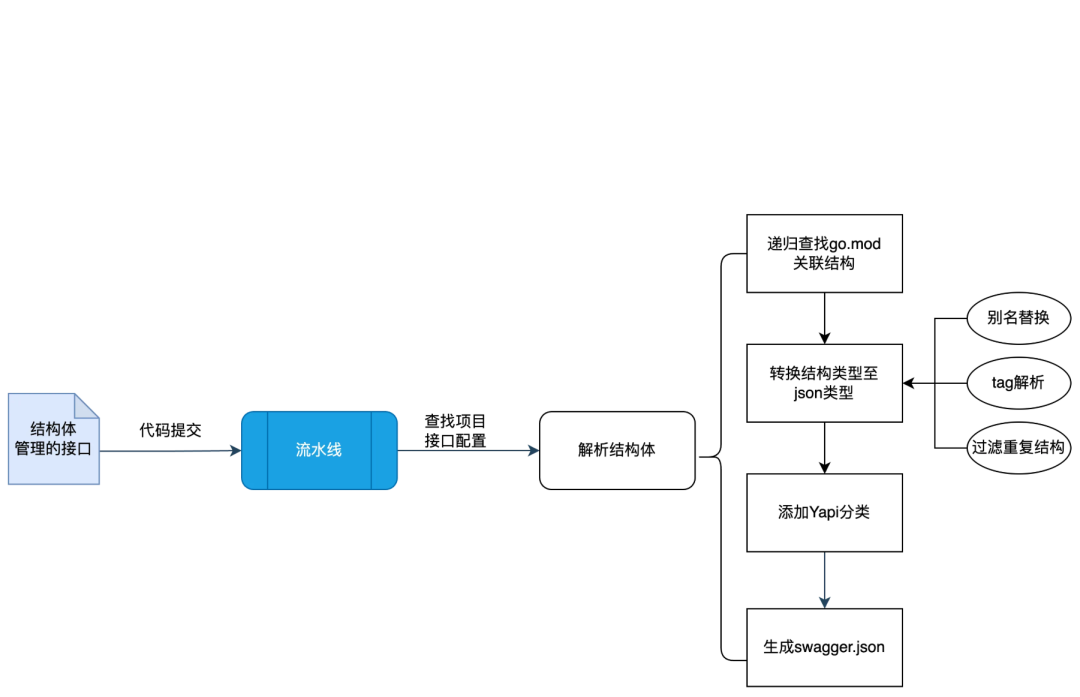
项目中接口配置信息:
{
"/api": {
"summary": "xxxx接口",
"description": "xxx接口",
"request": "#/definitions/gitxxx|commonReq.RawReq",
"response": "#/definitions/git.xxx|entity.Result"
}
}后续收集下大家的使用功能上的便捷性,如果后续功能需要拓展,还是会内部在讨论一下切换至 swaggo 工具的使用,减少这些工具的维护成本。
2.4 接口管理平台建设总结
目前将新闻内部的所有26个核心代码仓库全部自动化同步,避免接口文档缺失,使用 Yapi 管理接口对使用侧开发人员更加友好。
我们将新闻微服务所有应同步的核心仓库全部接入自动化机制,确保了我们协议文档的维护的及时、准确、可持续。对客户端的 Mock 能力需求的提供了较完善的支持,日均使用达到了750+。
03
接口生命周期治理
3.1 接口生命周期全景
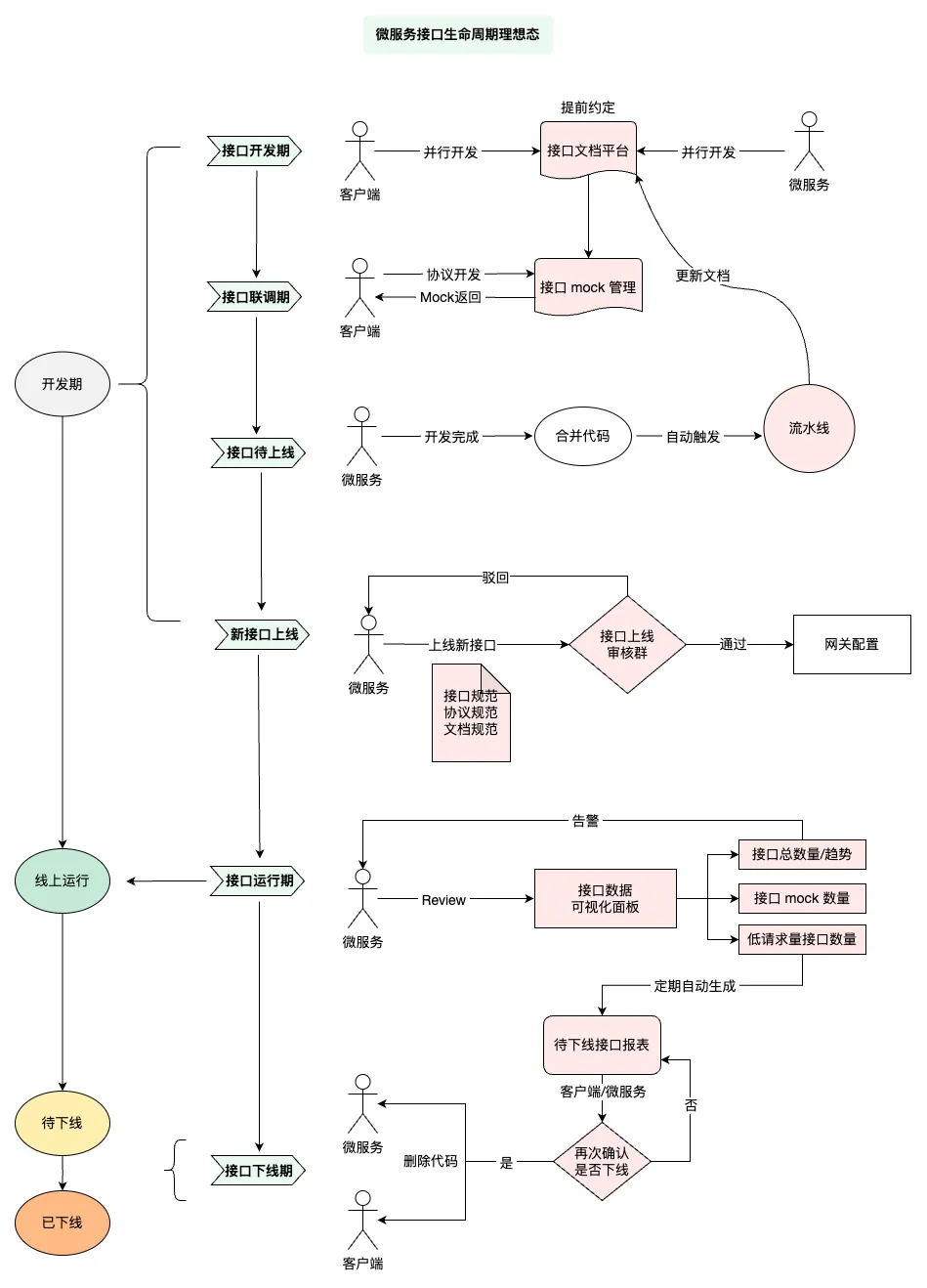
达成退场协议
服务端与客户端达成握手机制接口下线,HTTP Code 返回404,通知客户端该接口下线。绝大多数情况下,是相应的功能不在分发,双端可确认下线。
在接口规范当中也对接口返回错误码的机制进行了明确,对业务 code 返回不是0,客户端也会在页面提示重试按钮,这对我们在操作下线接口时对接口操作规范提供了指导。
3.2 构建规范
基于我们在新闻网关接口下线的过程中,总结了目前所遇到的问题如下,我们对接口的字段、接口名称、接口审核机制等进行明确规定。
接口设计原则
明确接口 GET、POST http 请求方法使用规则。
我们对字段、接口路径、接口字段基础类型进行了限制。
接口文档
针对之前文档缺失、维护问题,已经要求所有新建服务都接入 Yapi 平台。
废弃的字段应当及时删除。
接口测试
针对接口自动化测试、接口的压测缺失,提供了建议性的措施。
接口发布审核
构建二级审核机制:内部 pb CR 审核、网关接口发布前的审核。
接口监控
对接口的响应耗时、错误率、低流量、Mock 等接口提供了详细的建议新规范。
接口下线机制
构建接口下线流程,与客户端、前端达成下线 SOP;
通过监控观测低流量、Mock 接口,定期生成报表对接口进行处理。
后续我们会在接口发布时接入蓝盾流水线对接口进行检测拦截。
3.3 监控与报表
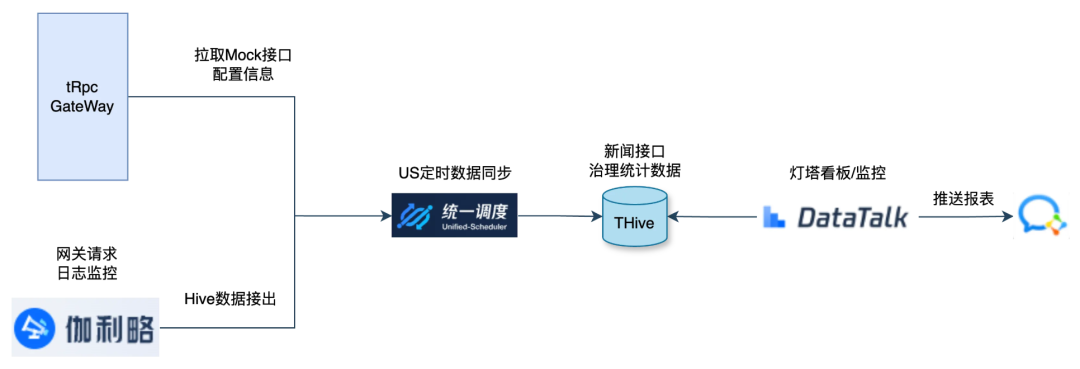
自动化接口报表
我们会定期将网关中需要确认下线的接口状态定期通过机器人的方式推送到群里,减少人工从网关监控、伽利略拉取数据再生成 Excel 操作成本,提升效率,达到定期梳理的操作。
报表:
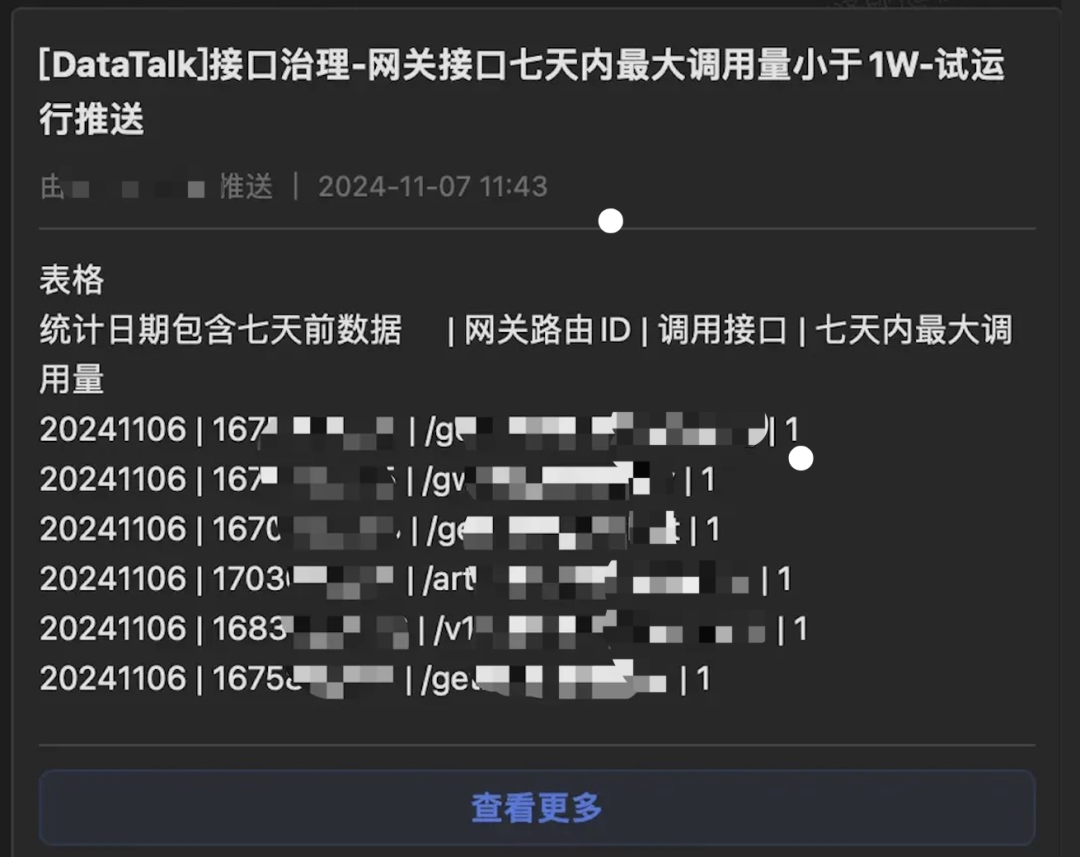
构建监控指标
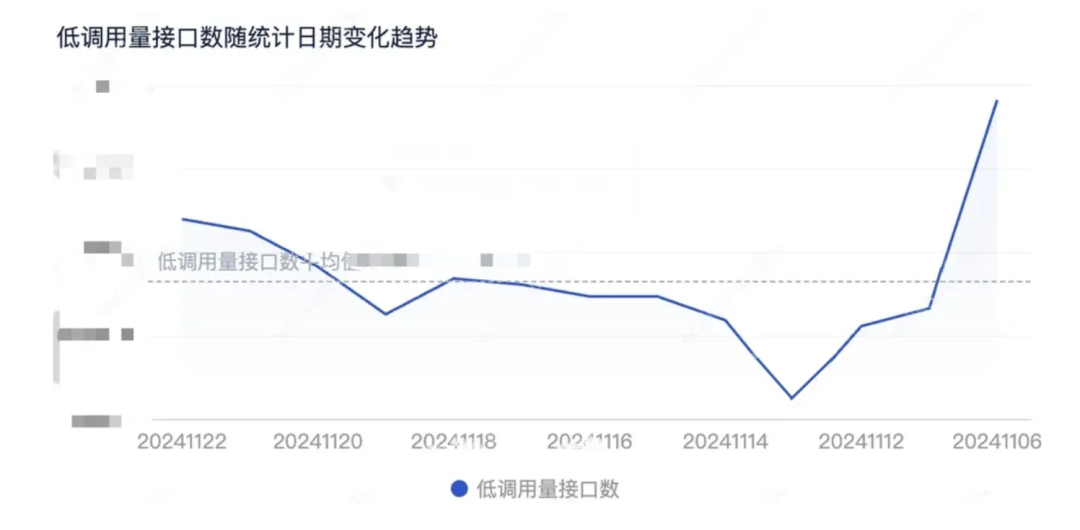
为了更好的评估整个微服务的接口技术债务健康状态,我们完善了以下监控指标。
1、监控:线上低请求流量指标。
线上日请求流量的10000接口,每天接口数量的波动指标进行监控。
监控面板:
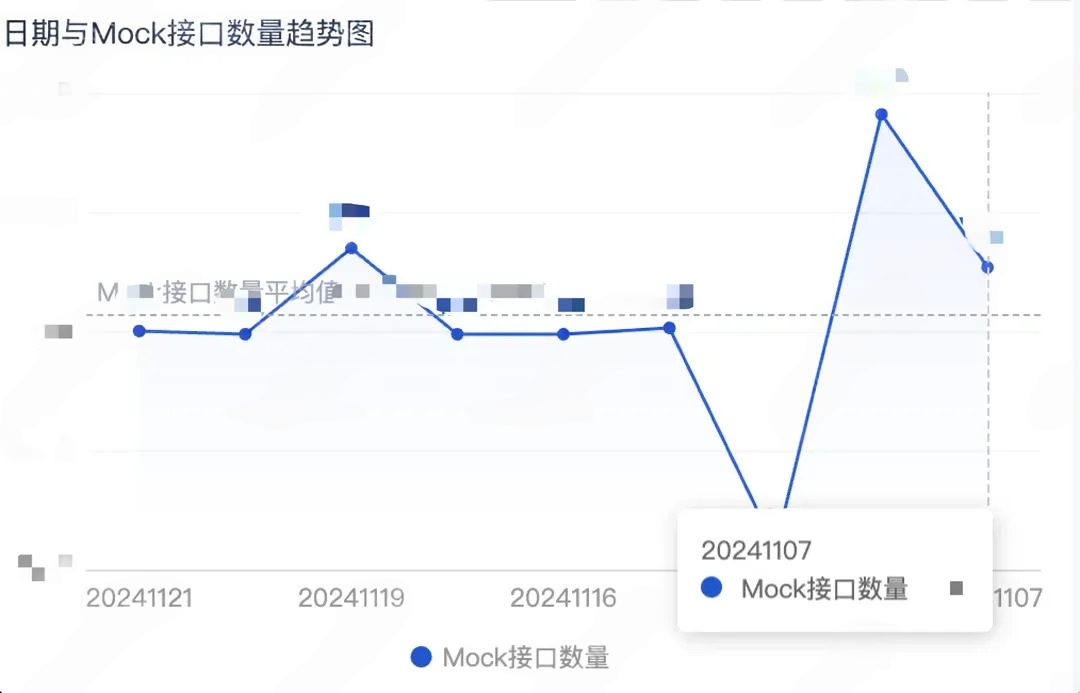
2、监控线上 Mock 接口指标。
很多接口在网关中的已经下线,实际上只是在网关直接进行 Mock,因为有客户端历史版本可能会触发请求,临时在网关进行了 Mock,但是实际上没有删除。监控这项指标让我们了解到,当前接口没有删除掉的 Mock 接口。
监控面板:
未来我们依据这两指标可以构建整个微服务接口债务分级健康状态,例如
健康状态:
mock 接口数小于50且流量小于10000的接口数小于50。
警告状态:
mock 接口数小于100且流量小于10000的接口数小于150。
严重状态:
mock 接口数小于200且流量小于10000的接口数小于300。
3.4 接口生命周期治理总结
整个新闻微服务共计1300+个接口,经过我们进行全面排查和治理,确认每个接口当前的状态、责任人,共计300多接口待下线、对下线接口执行了删除操作。与客户端达、前端成接口的退场机制、构建了相应的研发规范、完善了审核机制、接口监控以及报表、建立了长效的接口治理机制。
04
面向未来-技术债务的 AI 时代
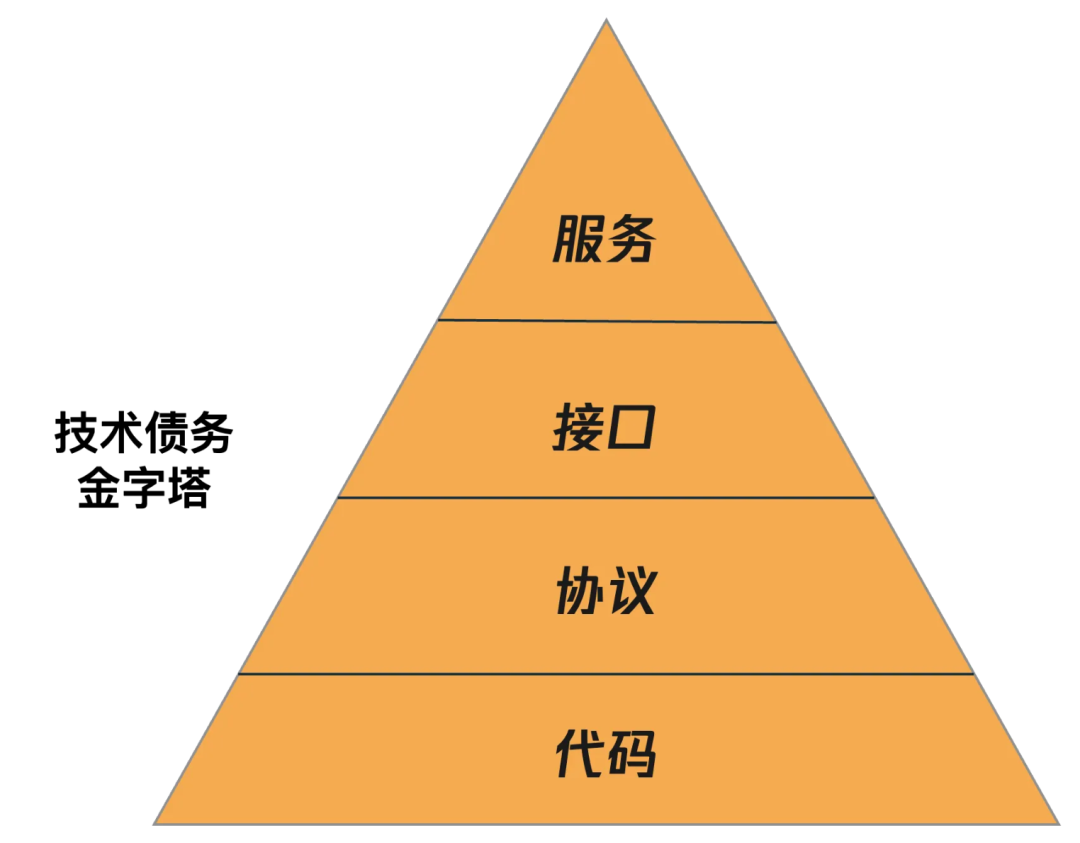
其实技术债务本质都依赖不开我们的代码,我们可以借助AI的手段治理代码,进而来控制包括接口、字段协议、服务技术债务,为什么使用AI治理技术债务,使用AI治理技术债务有什么优势?
这里介绍一下我对 AI 模型在技术债务中的理解:
识别准确性:AI 利用强大推理能力,可以识别代码中隐藏问题,结合规则可以构建完善的代码技术债务识别。
辅助智能化:可以通过大语言模型的对话机器人达到人工对获取相关信息,辅助人工决策技术债务治理,更加高效,快捷便捷。
不同任务可塑性:通过不同的模型以及对具体任务的精调或者提示词优化等,完全可以胜任不同类型的语言数据债务场景。
其实司内的工蜂代码 Copilot 对代码的 CR、辅助词的提示已经做的很不错了,这里我列出了我们的场景可以落地的一些 AI 相关债务治理的探索。
4.1 代码技术债务自动探测
现有的模型内已经有相关的代码技术债务的探测模型,如果这个模型能否真正能落地是对我们的代码的技术债务定期检测、监控都是有很大的帮助的。
https://github.com/NamCyan/tesoro
下图模型设计的具体流程:
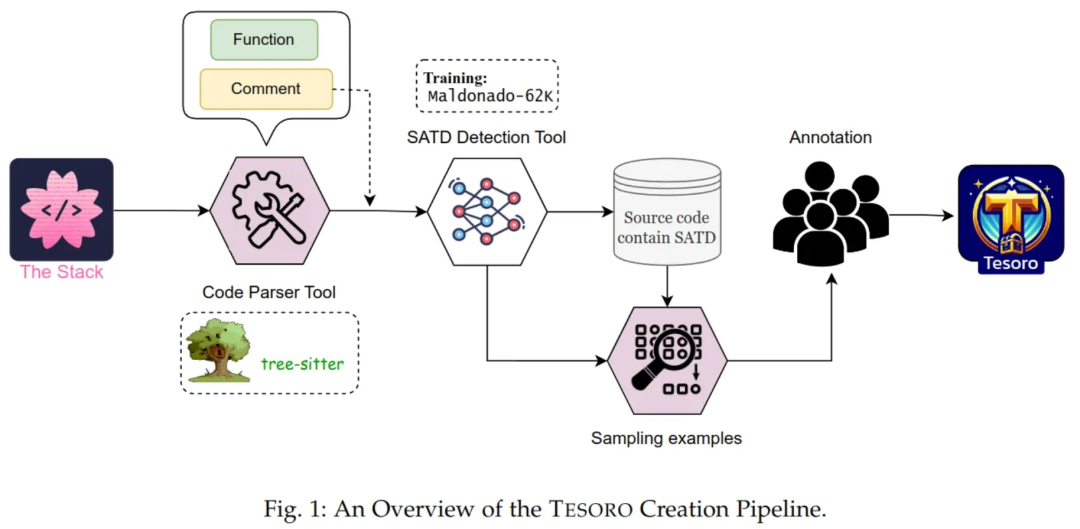
训练数据集使用两种方式:
注释:自我标注的技术债务相关的注释,如 TODO:、FIXME 等等这样的注释。
代码:根据代码直接直接判断技术债务,无任何注释。
目前有两个问题:
数据集用的是 Java,对其他的语言实现识别可能会出现偏差。已在对应的仓库提了 issue,静待好消息。
直接通过代码判断技术债务的 F1 Score 最高只有46.19,代码结合注释 F1 Score 最高90.12(详见论文),直接通过代码的方式分数还是挺低的,也就是识别需要结合注释。
因此可见目前的 Tesoro 技术债务识别的一个前提条件就是有良好的注释规范,虽然没有亲自尝试这个模型的有效性,但是 Tesoro 确实是一个技术债务治理的曙光。
4.1.1 实现思路
将探测模型接入到每次代码的提交的流水线,判断当前代码提交信息是否存在技术债务。
技术债务定期全量扫描,判断代码的仓库中的技术债务。
4.2 接口协议字段下线辅助查询
纯代码的技术债务的探测,对业务的高频迭代的场景显然是不足的,因为有很多功能频繁的上线和下线,基于代码技术债务自动探测只是关注了代码内部的设计,而并不是整个上下游全链路的关联。
现在新闻内部的很多字段,需要前端、后端、生产侧等确认。与上下游确认的流程效率低,我们想基于当前的服务端代码,针对客户端人员的使用问题进行检索,并返回对应的检索结果。检索结果中不仅包含代码片段,包含机器人对代码的分析结果,后续也可以加一些建议,这样可以减少一些人工排查的成本、提高研发效率。
整个实现路径不能太复杂、机器成本和人力成本,10亿以上参数的模型不在我们考虑的范围,使用较低成本达到预期效果。
我们基于 Langchain 技术框架的 RAG(Retrieval-Augmented Generation)方法(是一种结合信息检索和生成模型的方法,用于增强生成式 AI 的性能和准确性),实现了一个简单的协议确认对话机器人。
4.2.1 实现思路
这里主要是四个步骤,对这些步骤中的的关键点进行一些简单的介绍。
Embedding:jina
Index: whoosh
Vector: InMemoryVectorStore
环境:l20 (CPU 32核;内存 64G;硬盘 500G;显卡 l20 1/3卡;显存 14G)
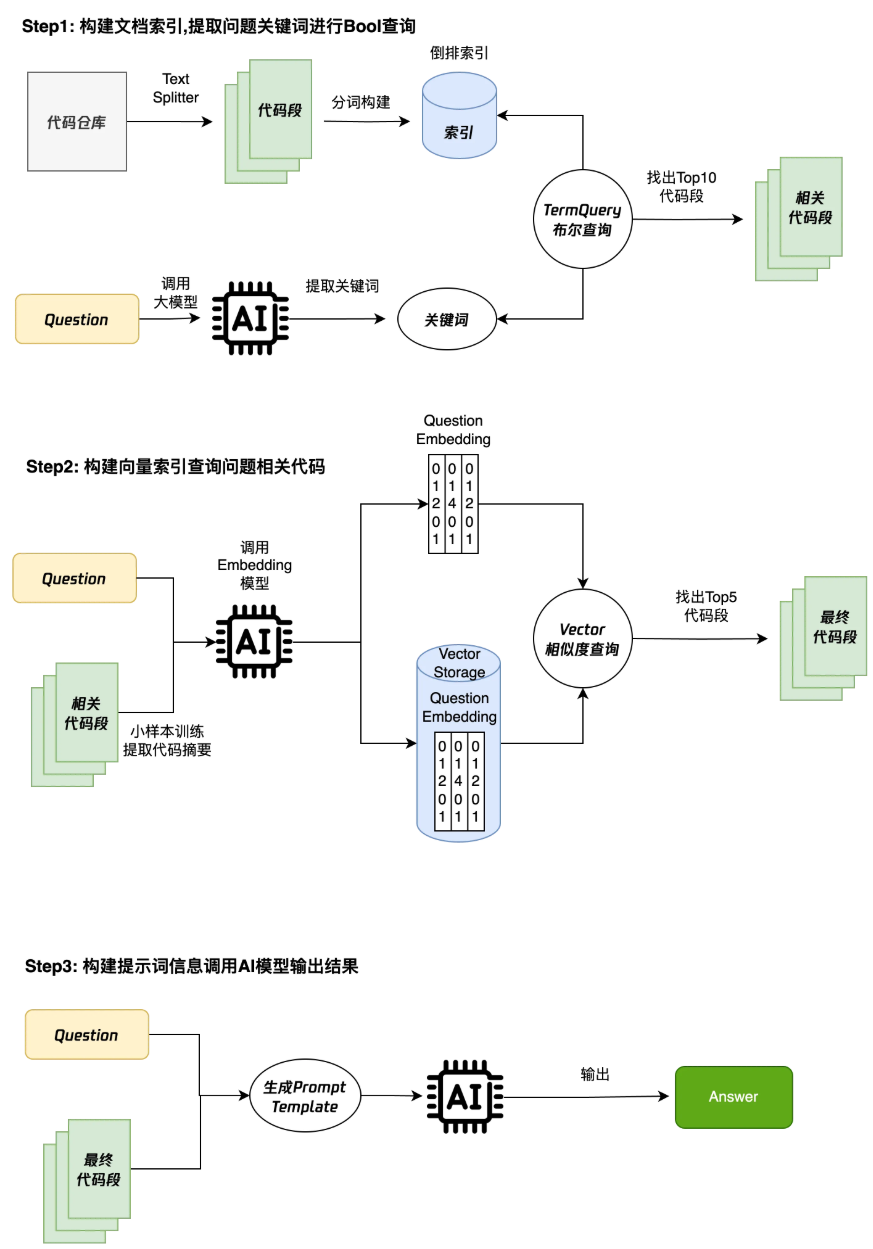
Step1: 构建文档索引,提取问题关键词进行 Bool 查询
构建文档索引:Demo 索引实现为 whoosh,实际生产建议使用 ES。
解释一下为什么需要先构建索引,用 Bool 查询查询文档呢?
因为文档直接用向量索引去召回,代码的查询准确度有较大偏差,语义文本和代码的文本差距是很大的,对语义的理解不够准确。当然这里也可以用相关的文档做 BM-25、TF-IDF 算法排序。
Qustion 调用大模型进行拆词,使用大模型对多语言的支持更好,可以更精确的提取关键词,这里使用 FewShotTemplate(通过少量的示例来训练模型),见下文的源码。
Step2:构建向量索引查询问题相关代码
下文源码使用了 JinaEmbedding,先对大模型进行小样本训练将代码提炼成简短的摘要,然后对问题和摘要进行了 Embedding,其实还可以直接用大模型把问题转换成英文然后再调用 Embedding,这样做更加精确一些。
也可以直接使用 AI 模型生成 Embedding。由于机器显存有限,我选了一个较小的模型(Jina)生成对应的 Embedding。
为什么还需要进行 Vector 查询?由于一般的大模型对上下文的 Token 有限制,不能把 bool 查询的数据全部丢给大模型,这一步主要是提取问题相关的代码段,更好的找到问题关联的代码段。如果模型上下文足够大可以跳过这一步骤。
Step3:构建提示词信息调用 AI 模型输出结果
对文档进行一个小样本的提示词训练,查询到最终的文档和问题构建 Promp Template,对当前的任务进行特定训练,输入给大模型返回输出结果。
4.2.2 具体实现
以开原仓库 swaggo 为例,以下实现的一个初版本的 demo 精简版示例,供大家参考。
def split_go_doc(repo_path="/data/swag", chunk_size=1024, chunk_overlap=0) -> List[Document]:
"""切割Go doc 文本"""
loader = GenericLoader.from_filesystem(
repo_path,
glob="**/*",
suffixes=[".go"],
parser=LanguageParser(language=Language.GO)
)
documents = loader.load()
go_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.GO,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap)
texts = go_splitter.split_documents(documents)
return texts
class Embedding:
def __init__(self, model: Union[Any, None], model_name='jinaai/jina-embeddings-v2-base-zh'):
if model != None:
self.model = model.model
self.tokenizer = model.tokenizer
return
# 从model name加载对应的大模型
self.tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True, )
self.model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
def mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def embed(self, text):
inputs = self.tokenizer(text, return_tensors='pt', max_length=8192, truncation=True)
outputs = self.model(**inputs)
return self.mean_pooling(outputs, inputs['attention_mask']).squeeze().tolist()
def embed_documents(self, texts):
# Embed each document using the embed method
return [self.embed(text) for text in texts]
def embed_query(self, query):
# Embed the query using the embed method
return self.embed(query)
class QuestionTranslator:
examples: List[dict] = [
{
"question": "请问字段content的具体使用方法?",
"answer": "Please tell me how to use the field content specifically."
},
{
"question": "请问有没有注释为付费的函数实现?",
"answer": "Is there any function implementation annotated as paid?"
},
]
few_shot_prompt_template: FewShotChatMessagePromptTemplate
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{question}"),
("ai", "{answer}"),
]
)
final_prompt: ChatPromptTemplate
def __init__(self, llm):
self.llm = llm
self.few_shot_prompt_template = FewShotChatMessagePromptTemplate(examples=self.examples,
example_prompt=self.example_prompt)
self.final_prompt = ChatPromptTemplate.from_messages(
[
("system",
"你是一个翻译助手,请将问题转换为英文"),
self.few_shot_prompt_template,
("human", "{input}"),
]
)
def translate_quesiton(self, question: str) -> Any:
"""使用大语言模型调用"""
chain = self.final_prompt | self.llm
res = chain.invoke({"input": question})
if res == "":
return self.resolve_question_simple(question)
return res
class QuestionResolver:
examples: List[dict] = [
{
"question": "请问字段content的具体使用方法?",
"answer": "content"
},
{
"question": "请问有关函数content函数以及text字段的使用?",
"answer": "content,text"
},
{
"question": "请问有没有注释为付费的函数实现?",
"answer": "付费"
},
{
"question": "请问字段content且注释为付费的具体使用方法?",
"answer": "content,付费"
},
]
few_shot_prompt_template: FewShotChatMessagePromptTemplate
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{question}"),
("ai", "{answer}"),
]
)
final_prompt: ChatPromptTemplate
def __init__(self, llm):
self.llm = llm
self.few_shot_prompt_template = FewShotChatMessagePromptTemplate(examples=self.examples,
example_prompt=self.example_prompt)
self.final_prompt = ChatPromptTemplate.from_messages(
[
("system",
"你是一个代码查询的助手,你的唯一任务是解析出语句中所提问的函数,字段,注释的信息,并将结果以逗号区分,如果没有任何信息请不要返回"),
self.few_shot_prompt_template,
("human", "{input}"),
]
)
def resolve_quesiton(self, question: str) -> Any:
"""使用大语言模型调用"""
chain = self.final_prompt | self.llm
res = chain.invoke({"input": question})
if res == "":
return self.resolve_question_simple(question)
return res
def resolve_question_simple(self, question: str) -> str:
"""最简单方案提取英文关键字关键字"""
# 提取关键字
english_words = re.findall(r'[a-zA-Z]+', question)
if len(english_words) == 0:
return question
# english_words.append("func")
result = ' '.join(english_words)
# 打印提取出的英文单词
# print(result)
return result
class CodeExtractor:
examples: List[dict] = [
{
"question": """
var specialTagForSplit = map[string]bool{
paramAttr: true,
successAttr: true,
failureAttr: true,
responseAttr: true,
headerAttr: true,
}
""",
"answer": "定义了一个specialTagForSplit变量"
},
{
"question": """
type Formatter struct {
// debugging output goes here
debug Debugger
}
""",
"answer": "定义了一个结构体Formatter,包含debug字段"
},
{
"question": """
func NewFormatter() *Formatter {
formatter := &Formatter{
debug: log.New(os.Stdout, "", log.LstdFlags),
}
return formatter
}
""",
"answer": "定义了一个NewFormatter函数,返回了Formatter结构体"
}
]
few_shot_prompt_template: FewShotChatMessagePromptTemplate
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{question}"),
("ai", "{answer}"),
]
)
final_prompt: ChatPromptTemplate
def __init__(self, llm):
self.llm = llm
self.few_shot_prompt_template = FewShotChatMessagePromptTemplate(examples=self.examples,
example_prompt=self.example_prompt)
self.final_prompt = ChatPromptTemplate.from_messages(
[
("system",
"你是一个代码查询的助手,你的唯一任务是提取出提供的代码中的信息,控制在30字以内"),
self.few_shot_prompt_template,
("human", "{input}"),
]
)
def extract_code(self, question: str) -> Any:
"""使用大语言模型调用"""
chain = self.final_prompt | self.llm
res = chain.invoke({"input": question})
if res == "":
return self.resolve_question_simple(question)
return res
def extract(self, docs: List[Document]) -> List[str] :
res = [self.extract_code(doc.page_content) for doc in docs ]
return res
class EmbeddingRetriever:
vec_retriever: VectorStoreRetriever
embedding: Embedding
def __init__(self, texts: List[Document], embedding: Embedding):
self.embedding = embedding
self.vec_retriever = self.init_vec_retriever(texts)
def init_vec_retriever(self, texts: List[str]) -> VectorStoreRetriever:
"""对应的retriever"""
vector_store = InMemoryVectorStore(self.embedding)
ids = [str(i) for i, x in enumerate(texts)]
vector_store.add_texts(texts=texts, ids=ids)
return vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5},
)
def retrieve_doc(self, question: str, docs : List[Document]) -> List[Document]:
"""获取相关文档"""
texts = self.vec_retriever.invoke(question)
return [ docs[int(text.id)] for text in texts]
class IndexRetriever:
idx: FileIndex
texts: Union[List[Document], None]
question_resolver: QuestionResolver
def __init__(self, texts: Union[List[Document], None], qustion_resolver: QuestionResolver):
self.texts = texts
self.idx = self.init_idx(self.texts)
self.question_resolver = qustion_resolver
def init_idx(self, texts: Union[List[Document], None]) -> FileIndex:
"""初始化whoosh索引 主要存储对应的Bool 文档对应的数据"""
# 创建索引,暂存与当前目录的indexdir里
dir = "indexdir"
if os.path.exists(dir) or texts == None:
return open_dir(dir)
# 定义索引架构
schema = Schema(page_content=TEXT(stored=True), meta_data_content_type=TEXT(stored=True),
metadata=TEXT(stored=True))
os.mkdir(dir)
idx = create_in(dir, schema)
# 添加文档
writer = idx.writer()
for text in texts:
writer.add_document(page_content=text.page_content, meta_data_content_type=text.metadata["content_type"],
metadata=json.dumps(text.metadata))
writer.commit()
return idx
def find_doc_with_bool_query(self, question: str) -> List[Document]:
question = self.question_resolver.resolve_quesiton(question)
# 搜索
res = []
with self.idx.searcher() as searcher:
query = QueryParser("page_content", schema=self.idx.schema).parse(question)
combined_query = And([query, Or([Term("meta_data_content_type", "simplified_code", boost=2),
Term("meta_data_content_type", "classes")])])
search_res = searcher.search(combined_query, limit=10)
for text in search_res:
doc = Document(page_content=text['page_content'], metadata=json.loads(text['metadata']))
res.append(doc)
return res
class Chain:
chain: BaseCombineDocumentsChain
def __init__(self):
self.chain = self.init_chain()
def init_chain(self) -> BaseCombineDocumentsChain:
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
template = self.get_prompt_template()
prompt_template = PromptTemplate(
input_variables=["context", "question"],
template=template,
)
return load_qa_chain(llm, chain_type="stuff", prompt=prompt_template, callback_manager=callback_manager)
def get_prompt_template(self) -> str:
"""
返回对应的prompt模版
"""
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
system_prompt = """你是一个对Go语言代码仓库的解析助手,请对我的提供的问题结合相关的上下文进行解答,使用中文回答对应信息,请不要提供无关的信息."""
# system_prompt = ""
instruction = """
Context: {context}
Question: {question}"""
def prompt_format(instruction=instruction, system_prompt=system_prompt):
SYSTEM_PROMPT = B_SYS + system_prompt + E_SYS
prompt_template = B_INST + SYSTEM_PROMPT + instruction + E_INST
return prompt_template
return prompt_format()
question = "请问下有没有Schema的name字段相关信息"
base_texts = split_go_doc()
index_retriever = IndexRetriever(qustion_resolver=QuestionResolver(llm=llm), texts=base_texts)
base_texts = index_retriever.find_doc_with_bool_query(question)
question_translator=QuestionTranslator(llm=llm)
english_question = question_translator.translate_quesiton(question=question)
code_extractor = CodeExtractor(llm=llm)
texts = code_extractor.extract(base_texts)
embedding_retriever = EmbeddingRetriever(texts=texts, embedding=Embedding(model=None))
docs = embedding_retriever.retrieve_doc(question=english_question, docs=base_texts)
chain = Chain()
response = chain.chain({"input_documents": docs, "question": question}, return_only_outputs=True)
print("Quetion:", question)
print("Answer:", response['output_text'])4.2.3 功能演示
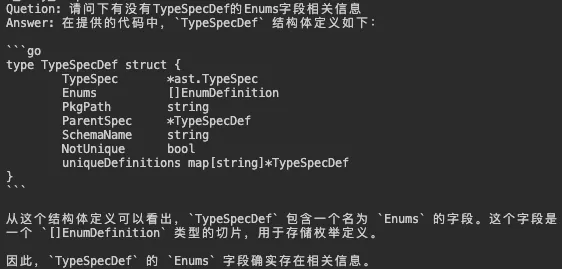
提问:请问下有没有 Schema 的 name 字段相关信息
相关信息:代码路径 swag/types.go 19行
// TypeSpecDef the whole information of a typeSpec.
type TypeSpecDef struct {
// ast file where TypeSpec is
File *ast.File
// the TypeSpec of this type definition
TypeSpec *ast.TypeSpec
Enums []EnumValue
// path of package starting from under ${GOPATH}/src or from module path in go.mod
PkgPath string
ParentSpec ast.Decl
SchemaName string
NotUnique bool
}可见 AI 模型给出了准确的回答!
4.2.4 小结
大模型在这个任务表现出的优势:
代码理解能力:根据问题、以及检索出的代码相关的上下文,进行了解析,并给出了字段是否有在使用的答案,如果结构体只有定义,那么该结构没有被使用。
解答沟通能力:以中文的形式对问题进行解答,便于提问者理解,如果是非AI模型答案可能是检索出来的代码,不能直接给出答案。除此外不仅可以给出结论,也可以给出相应的信息用作哪些处理。
4.3 全链路技术债务全自动检查
基于上面的实现对话机器人思路,我们可以实现完全自动化,最终产出一份自动化生产出的包含字段是否被具体使用、代码、接口、服务、负责人等信息。另外也可以做为技术债务指标其中的一个监控。
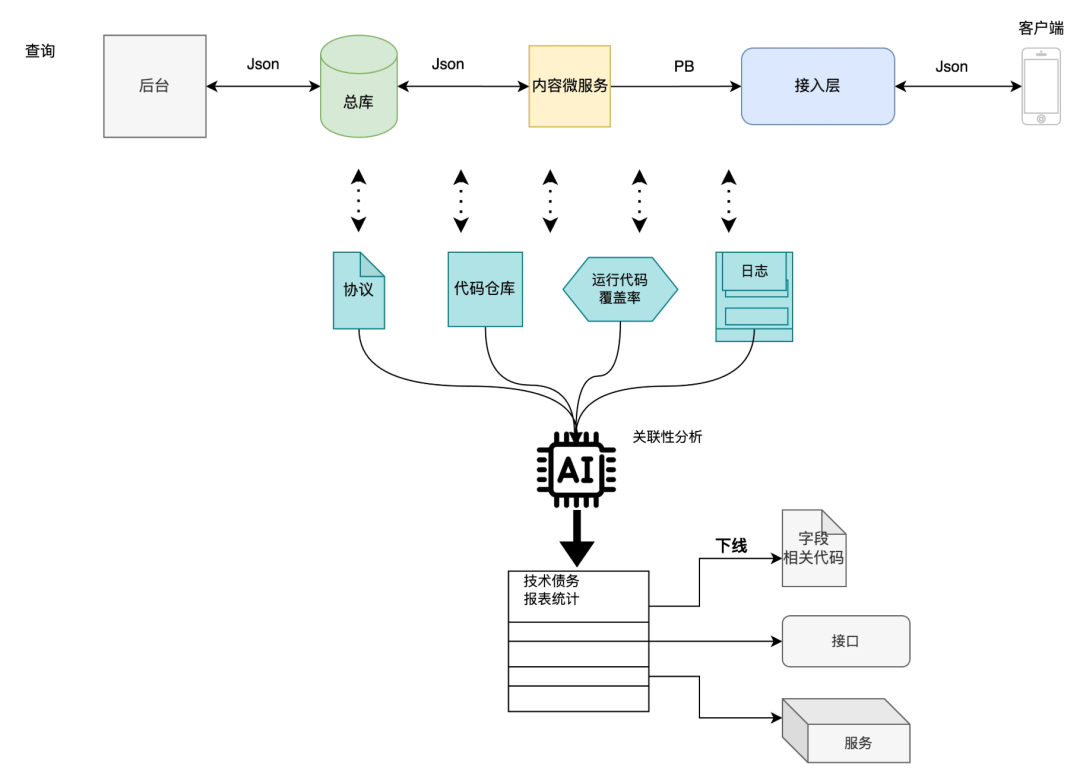
4.3.1 新闻业务流程分析
这里我先简单介绍一下新闻整个的业务流程,新闻数据生产经过后台管线加工,写入到总库里面,内容微服务为接入层的访问提供在线服务,接入层主要是处理业务逻辑,内容微服务的字段经过业务逻辑加工返回给最终的使用方客户端。
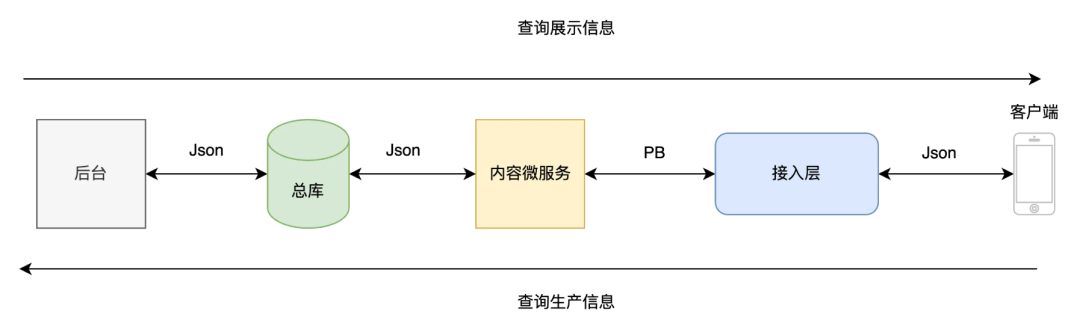
4.3.2 实现思路
因为每个服务都是通过协议交互的,协议是服务之间的纽带,整个链路中只要有一个节点断掉,那说明整个字段生产和使用是不对端输出的,要么可能被丢弃、或者被废弃。
这是一个相对简化的整体思路,实际上我们还会遇到很多服务包含了很多配置信息,动态化的字段等等。当然这些也可以有对应的解决办法,我们可以结合日志、配置、代码运行时分析等方式更加精确实现技术债务发现和探测。
示意图:
4.3.3 关键点
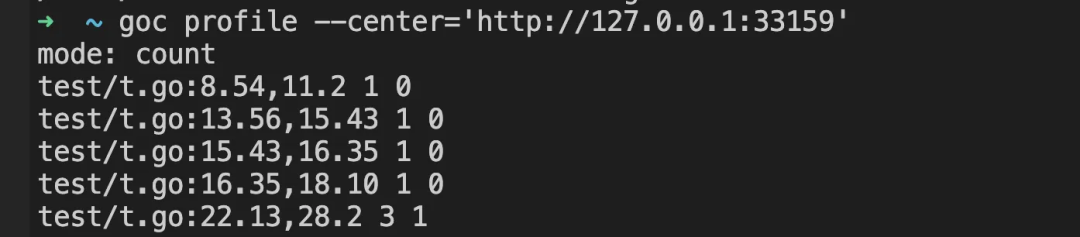
1、代码覆盖率运行检测
golang 语言建议参考 goc(采集代码运行覆盖率),线上可以采用流量复制、灰度流量、金丝雀节点的方式将小部分请求的代码覆盖率做存储 github.com/qiniu/goc
其他语言也有类似的能力,例如PHP-xdebug、C++ gcov等等。
下图展示了,对应文件中的代码的位置,有没有被执行过等信息。
可视化覆盖率界面:
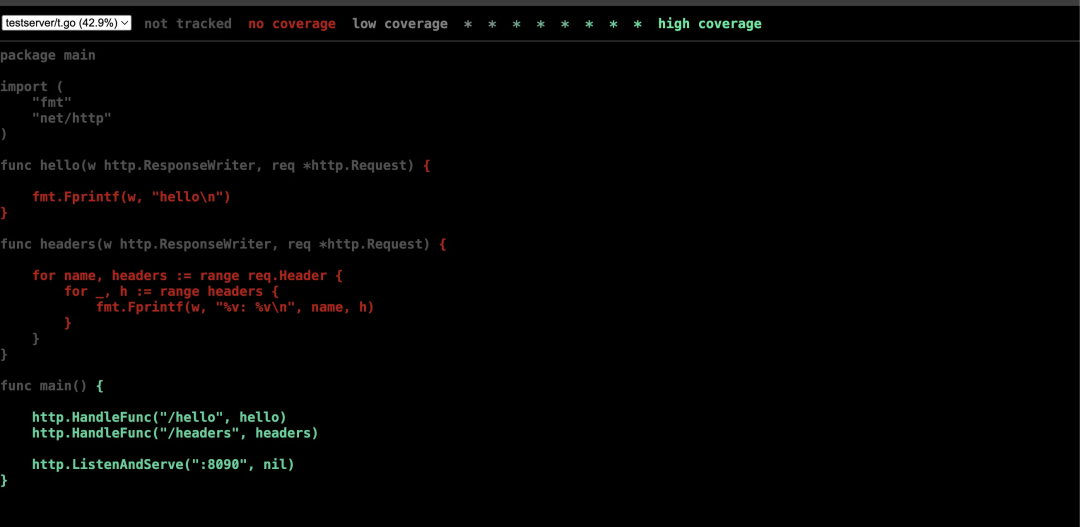
有了这些信息可以很方便的得到标注运行的代码。用于线上无用代码。
2、日志打点上报
客户端、服务端都可以通过日志打点上报判断。打点的日志可以包含当前代码的位置信息,可以很方便的定位对应的代码位置。
最终反应到代码里的是这个函数、变量、结构有没有被使用过。
3、协议
客户端和服务端,服务端和服务端之间的交互都可以能使用协议,做为交互的纽带,任何一方协议不在使用或者下线字段这个是可以被识别的。例如上游不生产的字段我们也可以自动的标注相关代码为无用代码。
4、生成标识的信息
基于以上信息我们可以生成对应的标注后的函数,以上文的 TypeSpecDef 为例,
type TypeSpecDef struct {
// ast file where TypeSpec is
File *ast.File // useless <--- 增加注释,给大模型提示
...
}有了标记以后我们可以提供对应的大模型进行代码的递归依赖无用删除推理,最终把所有标记可以下线的代码、协议字段、传递给整个服务链路。可以极大提高我们技术债务治理的效率。
我们把所有的关联代码检索出来,提供给大模型进行标注。大模型的关键在于很强的代码理解能力。
示例图:
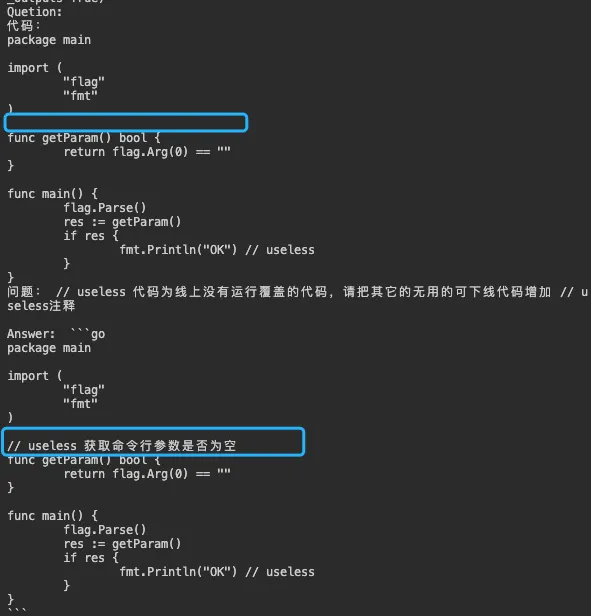
图中对代码执行逻辑进行了有效识别,对 getParam 函数(模拟动态获取 AB 实验、配置、版本兼容等动态判断代码)增加了// useless 注释。
AI 模型另一个优势是可以理解多个不同编程语言的,这极大增强了我们处理不同语言的策略可移植性。因此我们可以将不用代码关联的协议字段提供给上下游,进行传递,然后基于下线信息再进行代码技术债务处理。
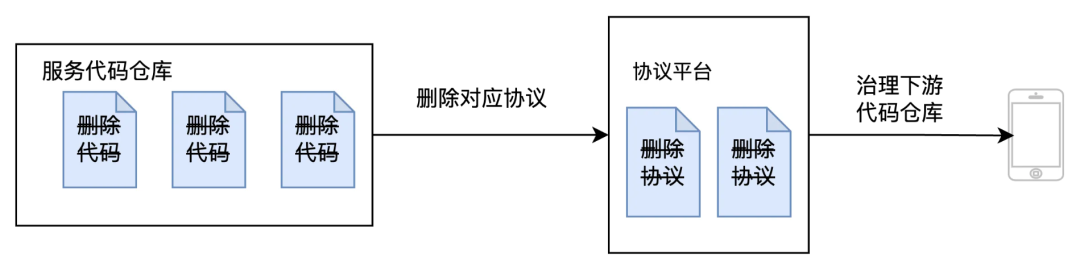
技术债务的治理是一个全局的过程,每个环节都会产生技术债务。
技术债务核心源头还是我们的代码,我们要控制好我们的代码的源头,做好每一次 CR 和设计、尽量避免每一次的 quick fix、及时清理代码中的垃圾、构建完善的规范、完善接口文档,要意识到每多一行代码就是一笔债务,我们只有严格控制好债务产生的源头,我们才可以通过技术手段去控制技术债务。
借机会打个广告我的个人博客:eddison.top 。
相关资料
https://arxiv.org/pdf/2411.05457v1
https://www.axon.dev/blog/best-practices-for-managing-technical-debt-effectively
https://www.edvantis.com/blog/technical-debt/
https://artkai.io/blog/technical-debt-management
https://huggingface.co/SeyedAli/Multilingual-Text-Semantic-Search-Siamese-BERT-V1
https://huggingface.co/DianaIulia/code_search_codebert_base
https://towardsdatascience.com/advanced-retriever-techniques-to-improve-your-rags-1fac2b86dd61
https://vijaykumarkartha.medium.com/beginners-guide-to-retrieval-chain-from-langchain-f307b1a20e77
https://python.langchain.com/api_reference/langchain/retrievers/langchain.retrievers.document_compressors.listwise_rerank.LLMListwiseRerank.html
https://arxiv.org/pdf/2305.02156.pdf
https://arxiv.org/pdf/2312.15223v2
-End-
原创作者|刘泽欣

你有使用过 AI 处理编程业务的经验吗?欢迎评论留言。我们将选取1则优质的评论,送出腾讯云定制文件袋套装1个(见下图)。12月25日中午12点开奖。

📢📢欢迎加入腾讯云开发者社群,享前沿资讯、大咖干货,找兴趣搭子,交同城好友,更有鹅厂招聘机会、限量周边好礼等你来~

(长按图片立即扫码)























 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









