







 超级会员免费看
超级会员免费看
第2关:爬取网站实训图片并下载
任务描述
本关任务:上一关爬取的是图片链接,本关需要更进一步,将图片下载下来并保存到根目录下的images文件夹中(不存在需新建),并且根据提取的信息对图片进行命名。
编程要求
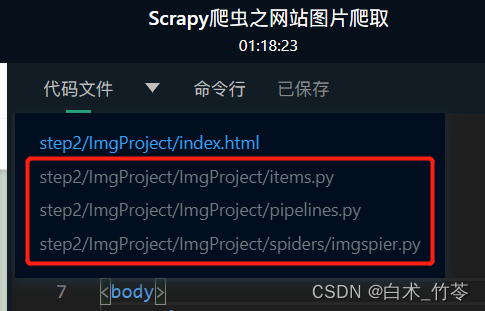
首先,通过审查元素,观察图片链接的代码规律;然后,点击代码文件旁边的三角符号,如下图所示,分别选择items.py、pipelines.py和主爬虫imgspier.py三个文件,补充 Begin-End 区间的代码,最终能成功将网站的图片下载到images文件夹,并且将图片命名为对应的数字。
测试说明
代码完成后点击测评,当评测出现 Django 启动失败时,重新评测即可。爬虫运行完成后,会在根目录下生成images文件夹,在本平台进入命令行,找到相应目录:cd /images,通过命令ls,可以查看images文件夹的内容,如下图所示。

上图红框部分的内容即为爬取到的图片。
预期输出:
爬取成功
开始你的任务吧,祝你成功!
解析:
首先点击 代码文件 ,可以看到以下

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 5739
5739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











