






Hadoop数据模型及应用架构介绍
TextFile
TextFile通常表现为csv(字段分界格式),json,Fixed-length Flat formats(固定长度的文件)
优点和缺点:
文本文件好读取,解析容易,是可分解的 splitable
文本文件不好的>好的,占用空间大,用hive,spark装载数据时,因为数据量大,读写时间很长,很费资源。最致命的是不支持块压缩,
zip的弊端:
在mapreduce中,mapper数量固然越多越好,mapper的产生是取决于逻辑分块,如果是文件经过了zip,那么物理分块可能有很多,但是逻辑分块只有一个,这样虽然占用内存虽然少了,但是并行度下降,很不利于计算。
块压缩:
引出块压缩,块压缩是将一个大的文件按照记录格式分成若干个块,针对于每一个块进行压缩,并在每一个块之间写一个特别的符号,sync mark,于是就形成了一个新的数据格式,这时将这个文件送进hdfs,它是splitable 可分解的
支持块压缩一定支持分解,支持分解不一定支持块压缩
splitable:
判断一个文件是不是splitable,那么就看它是否支持并行处理,送进hdfs最好是splitable。
文本文件具体实践
一般csv放进hdfs时候,一方面会保存原始的csv 叫做RAW,在hive中可以进行转换成ORC parquet avro。
Squence File
最初使用来map——>reduce文件数据传送,进可能让数据传送数据量最小,是key-value的二进制形式,比文本文件读写快的多
基于行,一个key 一个value
通常用于map reduce任务之间数据传送的格式
可以合并小文件成大的squenceFile
虽然说squencefile传送数据空间,以及读写快,其他各方面均没有优势
当数据文件是压缩的也是可以分解的(支持块压缩)
支持splitable的文件放到hdfs中可以支持并行处理
SequenceFile Format
Record Format
header Rec1 … sync RecX … sync RecN
Block Format
header Block1 Sync Block2 Sync … Sync BlockN
压缩:
记录层面和block层面上的压缩
javaAPI:org.apache.hadoop.io.SequenceFile
Sequence可以作为hive的一种文件格式,但是不建议这样做,因为value中可以包含多种字段,那么需要经过解析,然后拿出具体值,消耗资源是很大的
AVRO
AVRO不管可以定义数据文件格式,还可以定义schema
schema:json
数据存储:二进制格式
支持的数据类型:
null Boolean int long float double bytes strings binary data
arrays,maps,enumerations,records
schema Evolution
avro格式可以包容统一单元数据的不同版本。


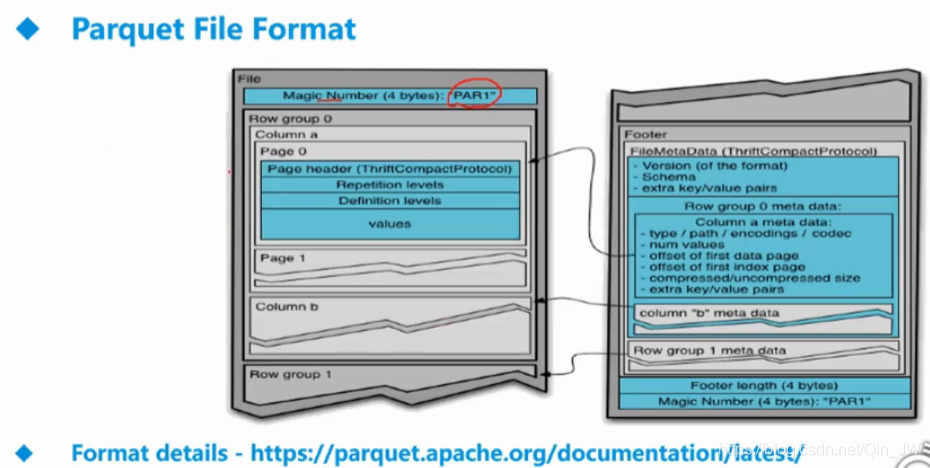
Parquet File
列式存储:将一个表进行横向切分成不同的分区,类似于hbase中的region,针对于每一个分区,当列非常多的时候,或用来存储一个宽表,那么就用该存储格式。parquet File 查询速度很快,但是生成一个parquet file很花费时间
parquet也包含schema信息
schema类型:
BOOLEAN INT32 INT54 INT96 FLOAT32 DOUBLE64 BYTE_ARRAY(string)

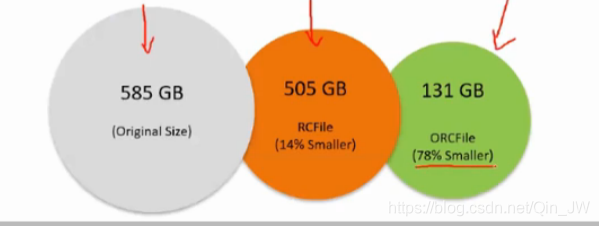
RC & ORC
这两种格式专门针对于hive设计
也是列式存储,支持建立索引 ,splitable


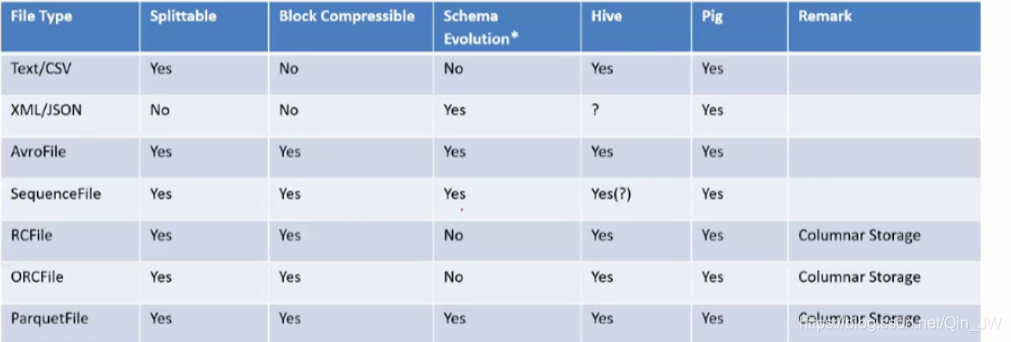
文件类型的比较
一般而言,写文件花的时间不是很在意,但是读文件
avro - schema evalution,数据集格式的定义随着时间变化,那么用avro是最好的
parquet - 宽表
parquet orc - 提升读的性能 花费了写的性能
text- 读取速度很慢
hive的查询速度:
ORC>Parquet>Text>Avro>SequenceFile
数据压缩:
块压缩,不牺牲文件并行处理,但同时对数据进行压缩
压缩算法:

Bzip2本身压缩就是splitable
Snappy Deflate用在大数据环境下用在块压缩是非常普及的
总结:
现阶段最流行的存储格式是AVRO,TEXT ,Parquet
ORC仅限在hive中效率和压缩都是最好的,但考虑到hdfs中存储的文件不光是给hive用,还用其它应用程序要用,所以hive的临时结果,中间结果可以用ORC。














 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









