







LLM在多个领域表现出强大能力,尽管在线服务广泛应用,但出于隐私和离线需求,个人常需要端侧部署。然而,现有的基于MoE和Transformer架构的LLM在端侧部署时面临显存容量不足的挑战。
5月22日20:00,青稞Talk 第50期,北京大学智能学院博士生、华为诺亚方舟实验室实习生节世博,将直播分享《MoLE & SpeCache:大语言模型端侧部署的架构与算法》。
本期Talk将聚焦模型参数与KV Cache两大推理时显存开销来源的两项解决方案:MoLE 和 SpeCache。
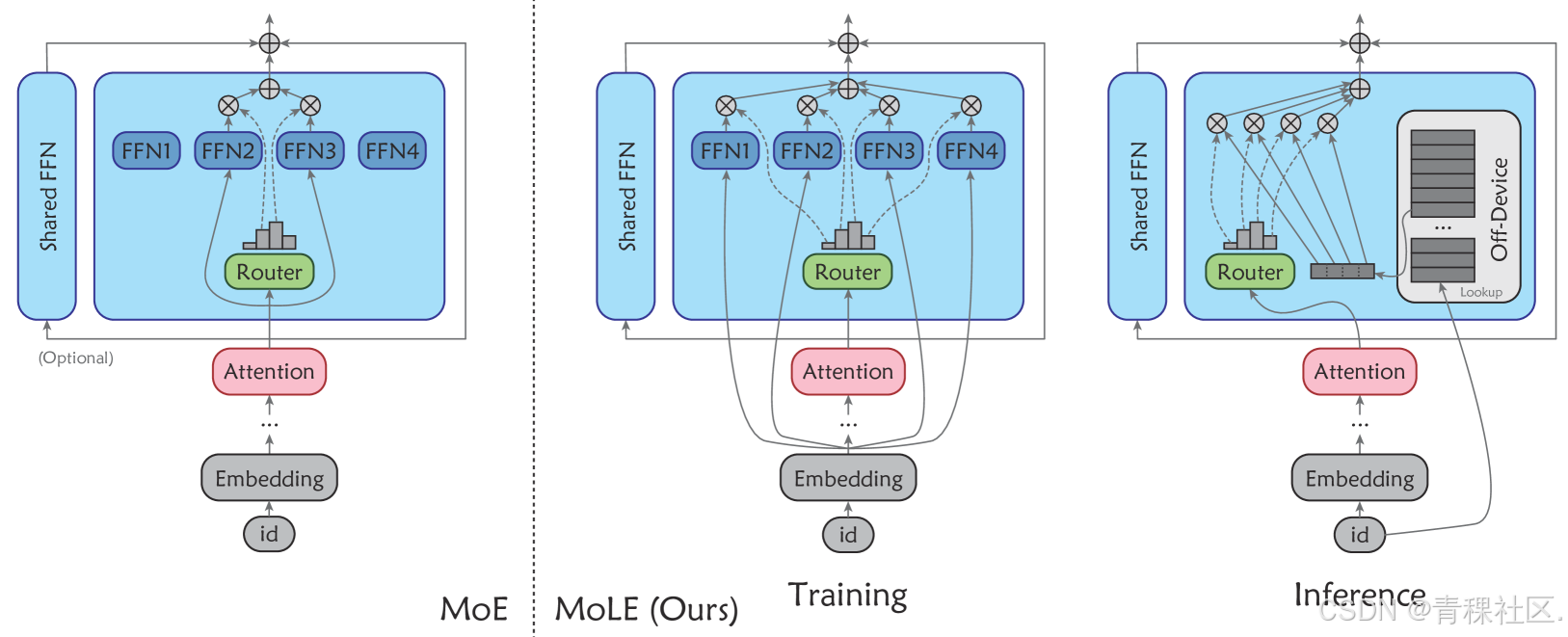
MoLE 架构将专家模块转化为可存储在底层存储中的查找表,用显存外的查找代替显存内的计算,显著降低显存需求和搬运代价。
论文名称:Mixture of Lookup Experts
论文链接:https://arxiv.org/pdf/2503.15798
论文代码:https://github.com/JieShibo/MoLE
SpeCache通过卸载KV Cache来降低显存需求,并在解码时临时加载所需要的top-k KV Cache,通过投机预取方法对top-k进行提前猜测,实现KV Cache的预取与解码计算并行。
论文名称:SpeCache: Speculative Key-Value Caching for Efficient Generation of LLMs
论文链接:https://arxiv.org/pdf/2503.16163
分享嘉宾
节世博,北京大学智能学院博士生,华为诺亚方舟实验室实习生,研究方向为大模型的高效微调与推理,在ICML、ICCV、ECCV、AAAI等AI领域国际顶级会议发表六篇一作工作。
主题提纲
MoLE & SpeCache:大语言模型端侧部署的架构与算法
1、MoE 和 Transformer架构大模型在部侧部署的挑战
2、降低推理时显存的主流方法解析
3、MoLE:推理阶段可重参数化的新型 MoE 架构
4、SpeCache:针对 KV Cache 降低显存开销
直播时间
5月22日20:00 - 21:00


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









