






关注公众号:青稞AI,第一时间学习最新AI技术
作者:Kaichen Zhou
声明:本文为作者投稿,版权归属原作者

尽管自监督单目深度估计与位姿估计技术已经取得了长足的进展,但在处理包含动态物体的复杂场景时,仍面临诸多挑战。这主要是由于这些方法大多建立在静态世界假设的基础上,难以准确捕捉并处理动态变化。为了突破这一瓶颈,我们推出了Manydepth2,一个创新的基于运动引导代价体积的深度网络。
Manydepth2将光流信息与初步的单目深度估计结果相结合,构建出一个静态参考帧,以此作为处理动态场景的基础。通过与目标帧的协同作用,我们构建了一个运动引导的代价体积,有效地捕捉了场景中物体的运动信息。此外,为了增强网络的性能,我们还引入了一种先进的基于注意力的深度网络架构,该架构能够高效地整合来自不同分辨率特征图的关键信息,进一步提升了深度估计与位姿估计的准确性和鲁棒性。
实验数据证明,在KITTI-2015和Cityscapes等权威数据集上,与计算成本相近的其他方法相比,Manydepth2在自监督单目深度估计与位姿估计任务中均展现出了卓越的性能,实现了显著的误差降低和精度提升。
其中的主要贡献包括:
- 静态参考帧生成:我们创新性地结合了估计的光流信息和先前的深度信息,生成了一个新的静态参考帧。这一方法有效地消除了原始帧中动态元素的影响,为后续的深度估计和动态捕捉提供了更稳定的基础。
- 运动引导代价体积构建: 通过引入新的静态参考帧、目标帧以及初始参考帧,我们构建了一个新颖的运动引导代价体积。这一体积能够精准地捕捉移动物体的动态信息,为精确的深度估计提供了有力支持。
- 基于HRNet和注意力机制的深度估计架构:我们利用高分辨率网络(HRNet)引入了一种创新的深度估计架构,该架构集成了注意力机制。这一设计使得网络能够整合不同细节级别的特征,从而实现精确的像素级密集预测,显著提升了深度估计的精度。
- 性能卓越:在KITTI、Cityscapes和KITTI Odometry等权威数据集上,我们提出的模型表现优异,超越了现有的单帧和多帧方法。这证明了我们的方法在处理复杂动态场景时的有效性和准确性。
- 高效训练:我们的模型训练效率较高,仅需在单张3090图形卡上,于合理的时间范围内即可完成训练。这一特性使得我们的方法更易于在实际应用中推广和部署。
论文投稿: ICRA 2025:https://2025.ieee-icra.org/
代码开源: https://github.com/kaichen-z/Manydepth2
研究背景
在计算机视觉领域,基于视觉的深度估计因其能够从二维观测中理解场景的三维几何结构而变得日益重要。这一能力为各种高级三维任务(如场景重建、目标检测和导航)提供了基础。 近年来,自监督深度估计作为一种可行的训练方法逐渐兴起,旨在减轻对大量训练数据的依赖并降低高计算需求。这些方法可以从单目图像或立体图像对中学习深度图。尽管自监督单目视觉深度估计取得了显著进展,但与自监督立体视觉深度估计相比,仍存在明显的性能差距。这种性能差异主要归因于立体方法能够利用多个视图构建特征体积,从而融入更多的三维相机视锥体信息。 相比之下,尽管多帧单目方法能够基于相邻帧构建特征体积,但这些相邻帧中存在的动态元素可能会破坏特征体积的构建,从而影响深度估计的准确性。因此,如何在保持计算效率的时,有效处理动态场景,成为自监督单目深度估计领域亟待解决的问题。

鉴于光流估计领域的最新进展及其在运动检测和估计任务中的成功应用,我们提出了Manydepth2。Manydepth2是一种自监督的单目视觉深度估计系统,它通过结合运动信息来改进深度估计的准确性。该系统利用注意力机制构建了一个运动引导代价体积,以整合运动信息。选择注意力机制是因为它在表示学习和多样化信息有效融合方面表现出了卓越的性能。通过这种方法,Manydepth2能够在不需要标注数据的情况下,从单目图像中更准确地估计出场景的深度信息。
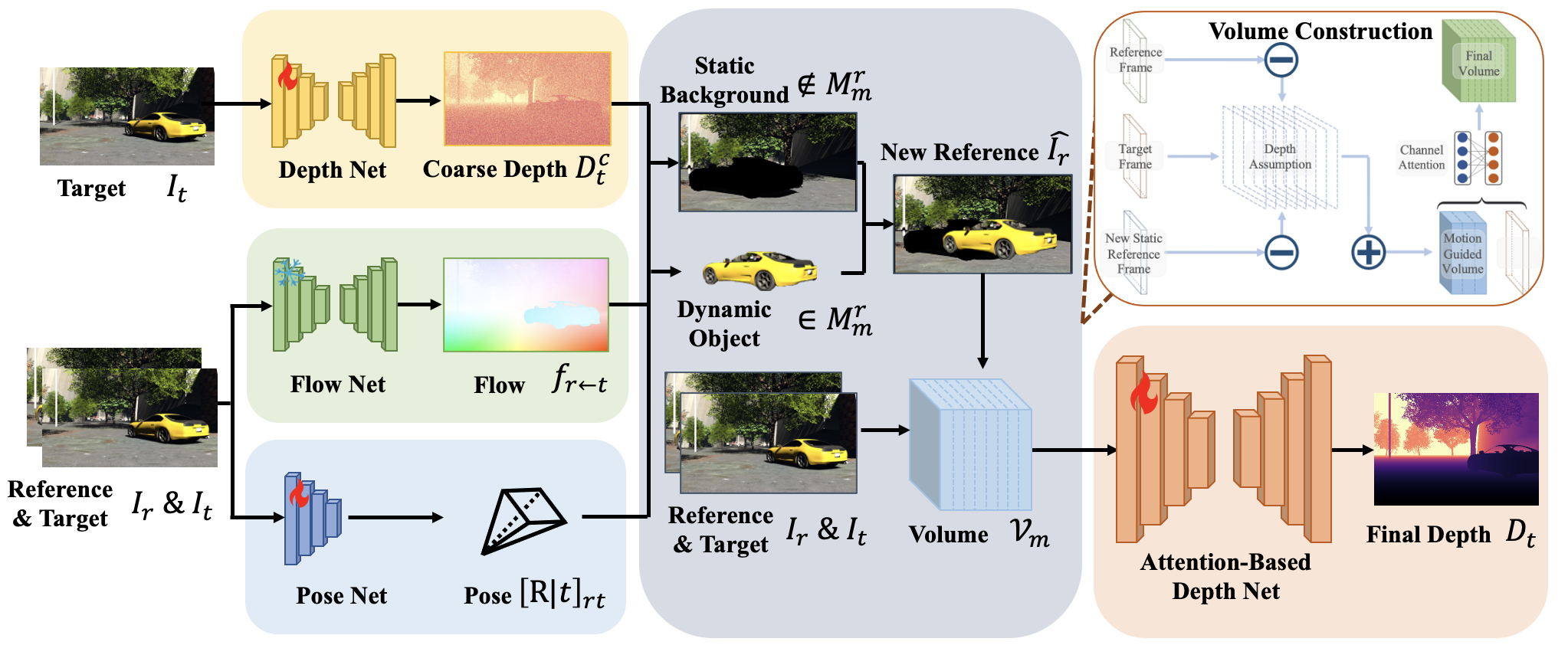
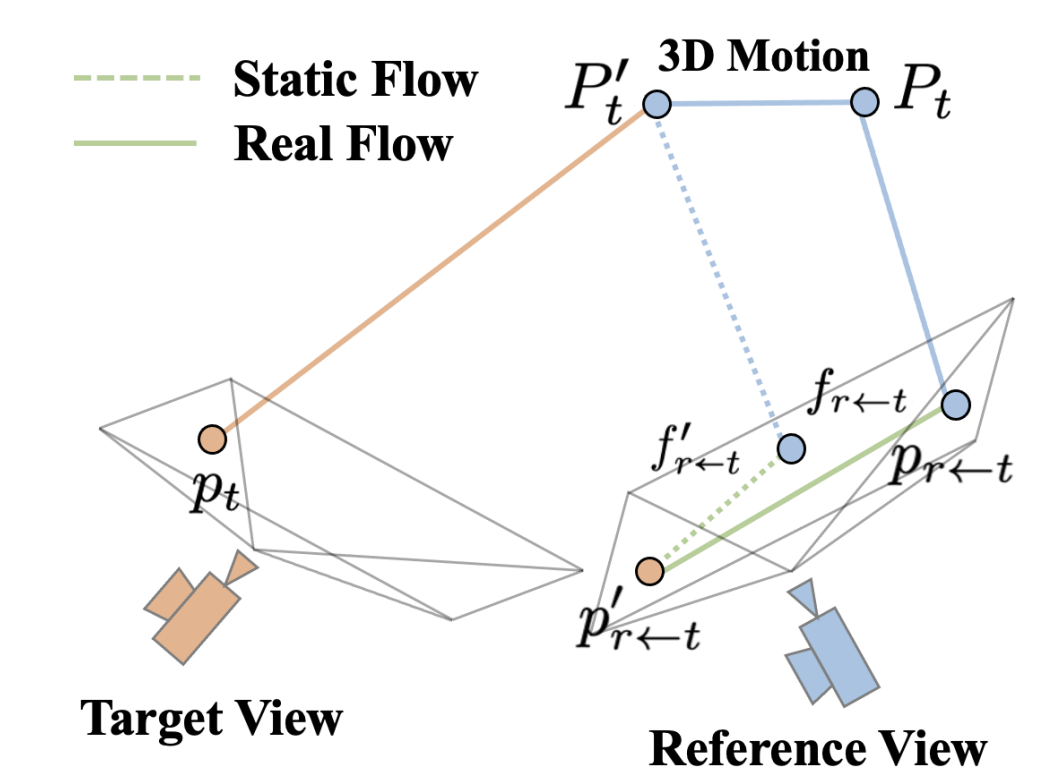
静态参考帧生成
在单目视频中对移动物体进行深度估计时,我们利用了从 t 时刻到 r 时刻的光流估计 f r ← t f_{r←t} fr←t 、变换矩阵 [ R ∣ t ] r t [R∣t]_{rt} [R∣t]rt 以及粗略的深度图 D c t D_{ct} Dct 。我们可以根据以下表达式计算基于深度的光流(静态光流) f ′ r ← t f′_{r←t} f′r←t :
f ′ r ← t = 1 / D r ( K r ) ( R r t ( K t ) − 1 D c t p t + t r t ) − p t , f′_{r←t} = 1/D_{r} (K_{r})(R_{rt}(K_{t})^{-1} D_{ct} p_{t} + t_{rt}) − p_{t} , f′r←t=1/Dr(Kr)(Rrt(Kt)−1Dctpt+trt)−pt,
其中, p t p_{t} pt 是帧 I t I_{t} It 中的像素; K r K_{r} Kr 和 K t K_{t} Kt 分别是帧 I r I_{r} Ir 和 I t I_{t} It 的内参矩阵。在静态场景中,静态光流 f ′ r ← t f′_{r←t} f′r←t 与真实的光流 f r ← t f_{r←t} fr←t 相一致。在包含移动物体的场景中,真实的光流 f r ← t f_{r←t} fr←t 可以分解为静态光流 f ′ r ← t f′_{r←t} f′r←t 和动态光流 f d , r ← t f_{d,r←t} fd,r←t 。基于以上分析,静态参考帧可以通过以下公式生成:
I
r
^
=
{
I
r
if
∥
f
t
←
r
(
p
i
)
−
f
t
←
r
′
(
p
i
)
∥
2
2
<
=
ϵ
;
ϕ
′
(
I
t
,
D
t
,
K
t
,
K
r
,
[
R
∣
t
]
r
t
)
if
∥
f
t
←
r
(
p
i
)
−
f
t
←
r
′
(
p
i
)
′
∥
2
2
>
ϵ
.
\hat{I_r} = \begin{cases} I_r & \text{if } \|f_{t←r}(p_i) - f_{t←r}'(p_i)\|_{2}^{2} <= \epsilon; \\ \phi'(I_t, D_t, K_t, K_r, [R | \mathbf{t}]_{rt}) & \text{if } \|f_{t←r}(p_i) - f_{t←r}'(p_i)'\|_{2}^{2} > \epsilon. \end{cases}
Ir^={Irϕ′(It,Dt,Kt,Kr,[R∣t]rt)if ∥ft←r(pi)−ft←r′(pi)∥22<=ϵ;if ∥ft←r(pi)−ft←r′(pi)′∥22>ϵ.
这种方法使得我们能够在包含动态物体的复杂场景中,更加准确地估计每个像素的深度,通过将总光流分解为静态和动态部分,我们可以更加细致地分析场景中的运动信息,从而提升深度估计的精度和鲁棒性。
运动引导代价体积
在为目标帧 I t I_t It 构建运动引导的代价体 V m V_m Vm 时,定义了一组与 I t I_t It 的光轴垂直的平行平面,这些平面基于深度假设 D = { d k ; k = 1 , … , M } D = \{d_k; k = 1, \ldots, M\} D={dk;k=1,…,M},其中 M M M 表示平面的数量。特征提取器 θ f e \theta_f^e θfe 用于生成 I t I_t It 和 I ^ r + ( 1 − α ) I r \hat{I}_r + (1 - \alpha) I_r I^r+(1−α)Ir 的特征图 F t F_t Ft 和 F ^ r \hat{F}_r F^r。借助于 D D D 和 [ R ∣ t ] r t [R|t]_{rt} [R∣t]rt,通过对 F ^ r \hat{F}_r F^r 进行变形生成一组特征图 { F ^ d k t ← r ; d k ∈ D } \{ \hat{F}_{d_k}^{t \leftarrow r}; d_k \in D \} {F^dkt←r;dk∈D}。通过融合特征图 F ^ d k \hat{F}_{d_k} F^dk和 F t F_t Ft,即可生成运动引导的代价体 V m V_m Vm。
基于注意力的深度网络
高分辨率网络(HRNet)因其能够在输入图像中保留高水平的细节信息而备受赞誉。HRNet由多个分支组成,这些分支用B表示,每个分支生成S个特征。然而,与仅利用每个分支最后阶段的特征图来进行视差图预测的做法不同,我们采用了通道注意力机制。这种机制将当前分支不同阶段的特征图与更深层分支的特征图进行融合。这一融合过程可以表示为 A ( [ f b s ] s = b s = 4 , [ f b + 1 s ] s = b + 1 s = 4 ) A([f_b^s]_{s=b}^{s=4}, [f_{b+1}^s]_{s=b+1}^{s=4}) A([fbs]s=bs=4,[fb+1s]s=b+1s=4)。简而言之,HRNet通过其多分支结构在多个尺度上并行处理图像特征,而通道注意力机制则进一步增强了这些特征之间的信息交互和融合,从而有助于更准确地预测视差图。
实验结果
本文在两大公开数据集——KITTI 2015与Cityscapes上,分别对无监督深度估计算法的准确性进行了全面验证。同时,针对无监督位姿估计算法,本文在KITTI odometry数据集上进行了精度测试,以确保该算法在实际场景中的有效性和可靠性。
自监督深度估计对比

实验结果表明,Manydepth2在自监督单目深度估计任务中展现出了卓越的性能,其能够高效地估计出场景中丰富细节的深度信息,充分证明了该算法在捕捉复杂场景深度特征方面的准确性:

自监督动态物体深度估计对比
相比于之前的自监督单目深度估计网络,Manydepth2能够更加有效地估计动态物体的深度细节:

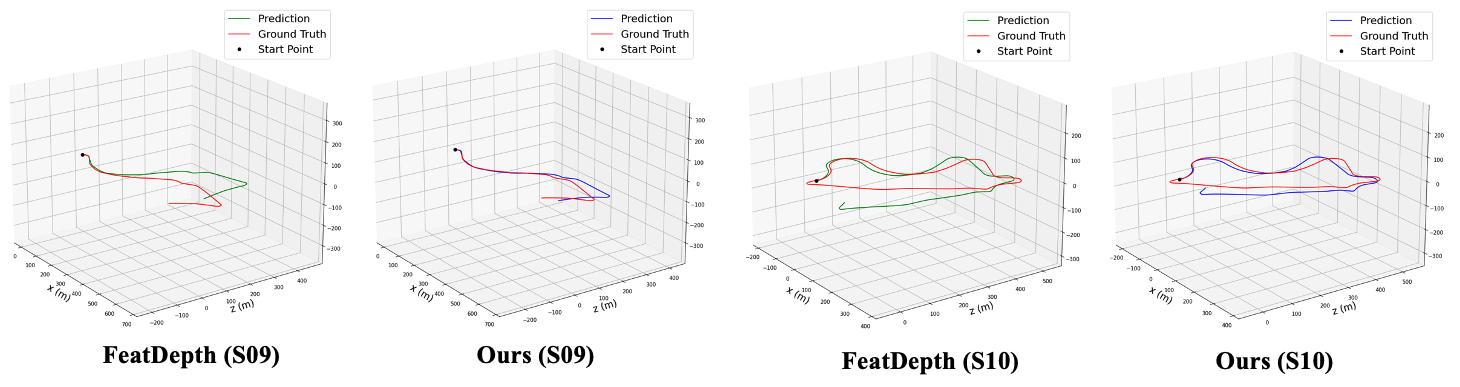
自监督位姿估计对比
同时,Manydepth2能够更加有效地估计长序列场景的位姿信息:
参考文献
- [1] Geiger, A., Lenz, P., Stiller, C. and Urtasun, R., 2013. Vision meets robotics: The kitti dataset. The International Journal of Robotics Research, 32(11), pp.1231-1237.
- [2] Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S. and Schiele, B., 2016. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3213-3223).
- [3] Wang, J., Sun, K., Cheng, T., Jiang, B., Deng, C., Zhao, Y., Liu, D., Mu, Y., Tan, M., Wang, X. and Liu, W., 2020. Deep high-resolution representation learning for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 43(10), pp.3349-3364.
- [4] Godard, C., Mac Aodha, O. and Brostow, G.J., 2017. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 270-279).
- [5] Watson, J., Mac Aodha, O., Prisacariu, V., Brostow, G. and Firman, M., 2021. The temporal opportunist: Self-supervised multi-frame monocular depth. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 1164-1174).















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









