







论文作者:Pengzhi Li,Pengfei Yu,Zide Liu,Wei He,Xuhao Pan,Xudong Rao,Tao Wei,Wei Chen
作者单位:Li Auto Inc.
论文链接:http://arxiv.org/abs/2502.18302v1
项目链接:https://zrealli.github.io/LDGen
内容简介:
1)方向:文本到图像生成
2)应用:文本到图像生成
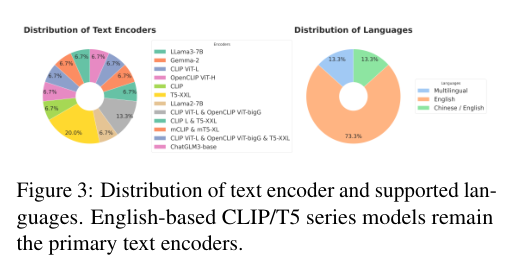
3)背景:传统的文本编码器(如CLIP和T5)在多语言处理方面存在局限性,导致它们在不同语言之间的图像生成能力受到限制。为了克服这些挑战,本文提出利用大型语言模型(LLMs)的先进能力来提升多语言图像生成性能。
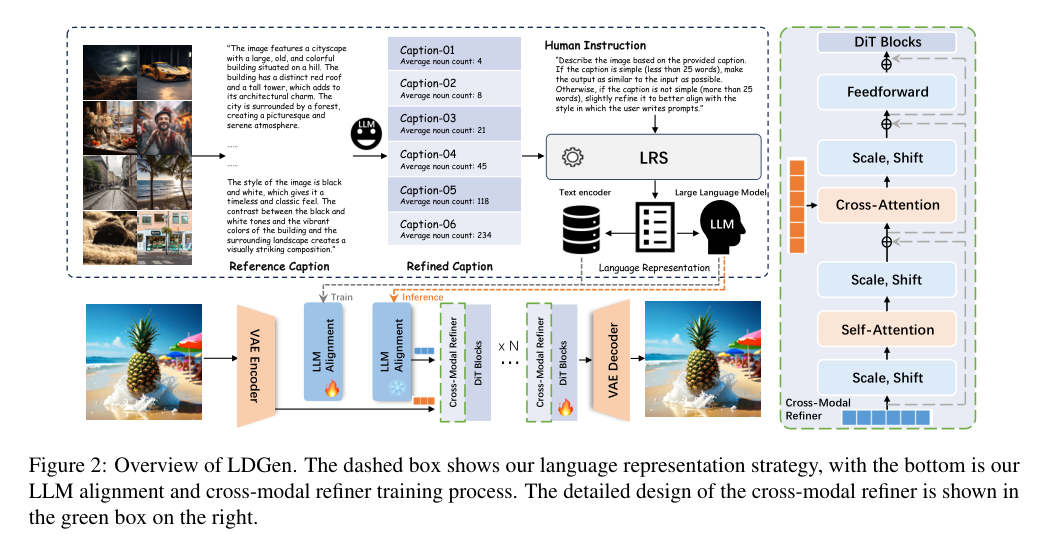
4)方法:本文提出了LDGen方法,该方法采用分层字幕优化和人类指令技术来精确提取语义信息,并结合轻量级适配器和跨模态精炼器,以实现LLMs与图像特征之间的高效对齐和交互。通过这一策略,LDGen能够减少训练时间,并实现零-shot的多语言图像生成。
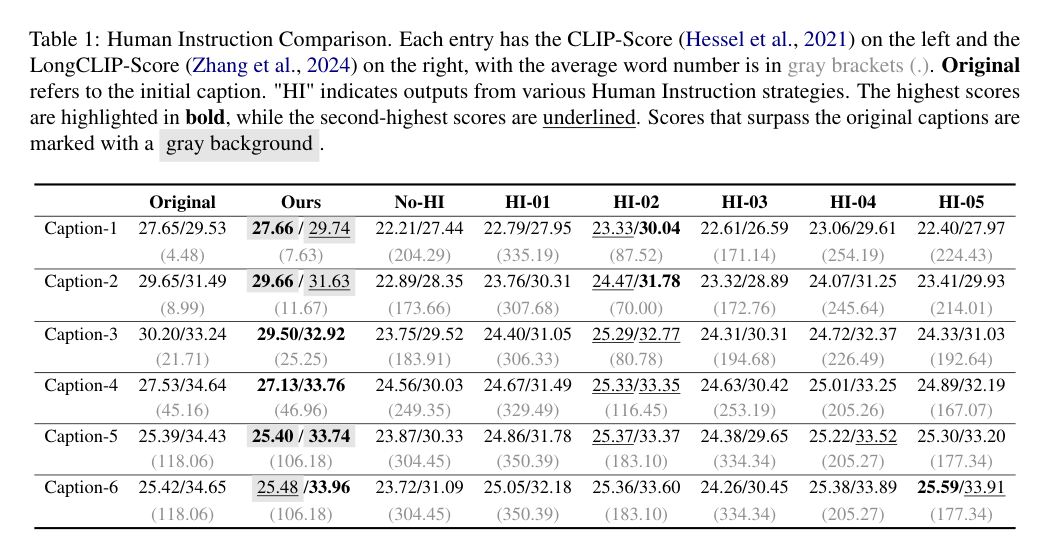
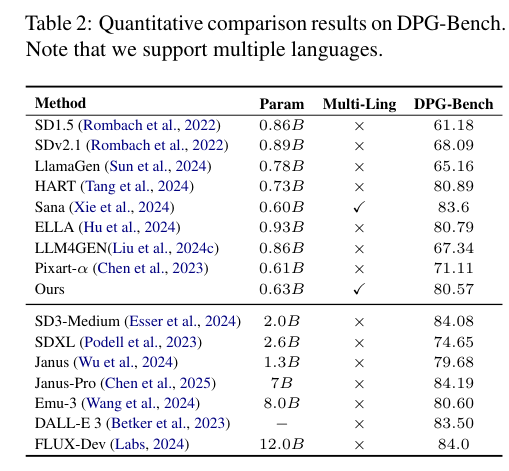
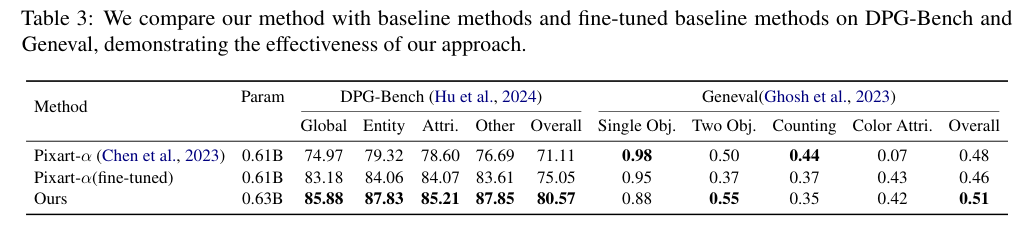
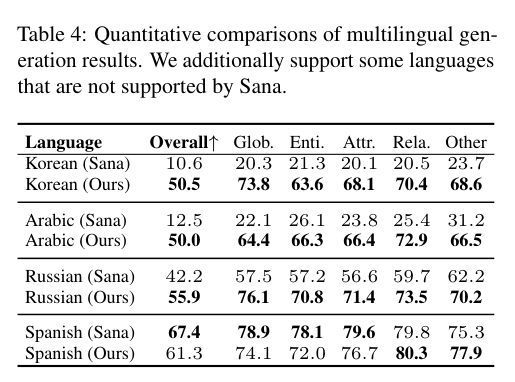
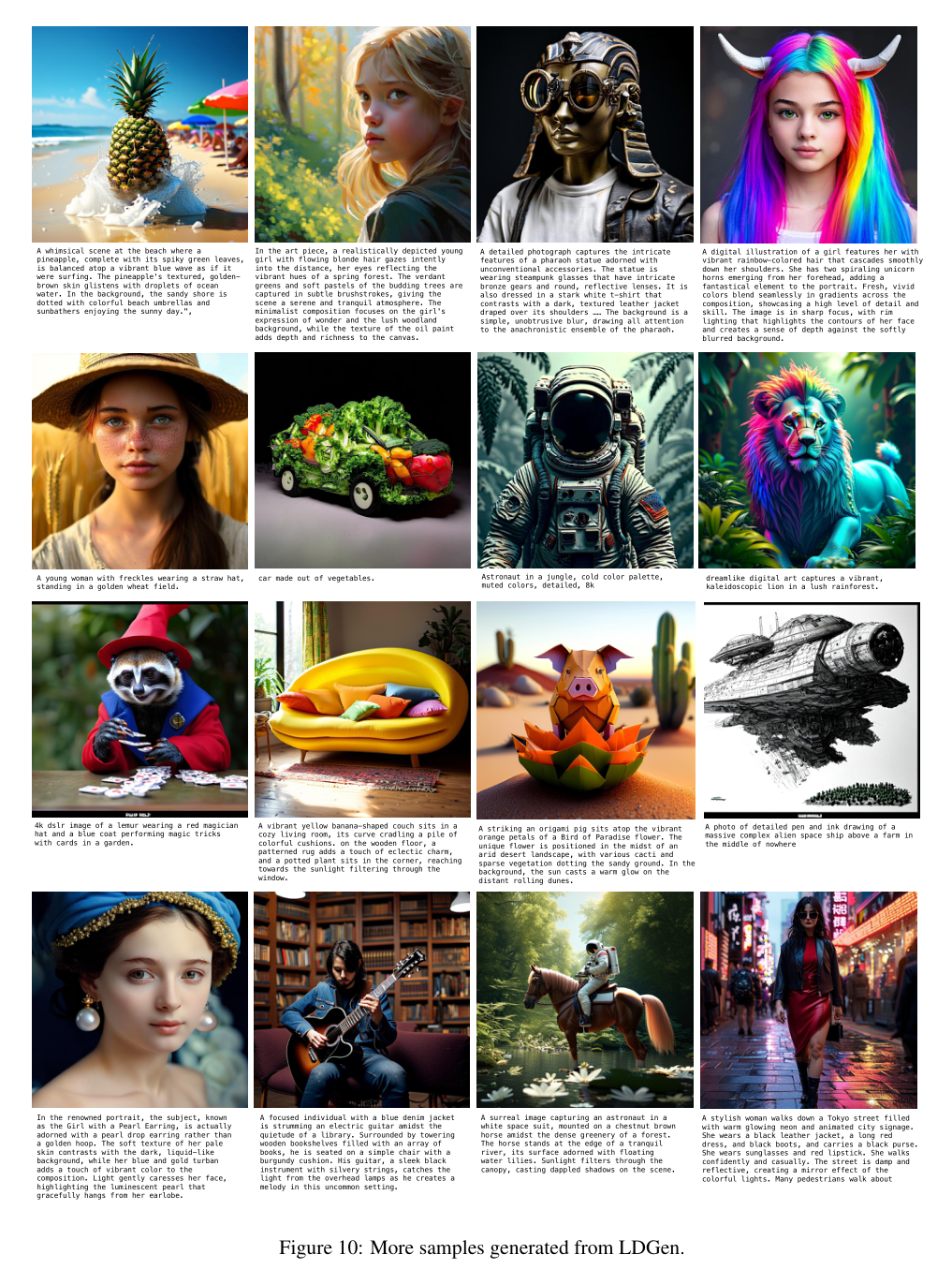
5)结果:实验结果表明,LDGen在遵循提示和图像美学质量方面均超过了基线模型,同时无缝支持多种语言的图像生成。项目:https://zrealli.github.io/LDGen



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











