




论文作者:Shun Zou,Yi Zou,Juncheng Li,Guangwei Gao,Guojun Qi
作者单位:Soochow University;Xiangtan University;Shanghai University;Nanjing University of Posts and Telecommunications & Soochow University;Westlake University
论文链接:http://arxiv.org/abs/2504.16455v1
项目链接:https://github.com/zs1314/CPRAformer
内容简介:
1)方向:图像去雨
2)应用:图像去雨
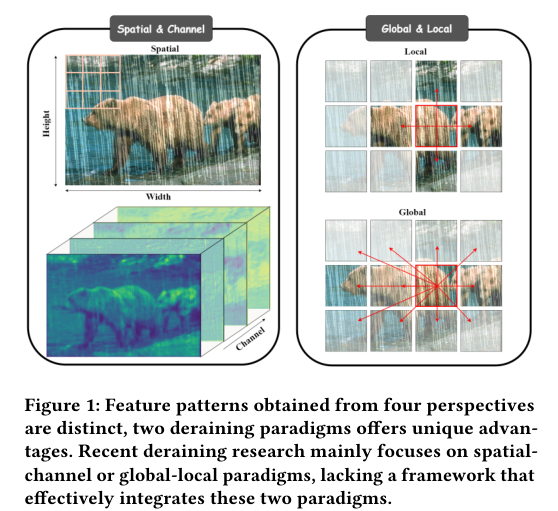
3)背景:尽管基于Transformer的网络在低级视觉任务中(如图像去雨)已取得显著成果,现有方法在面对不规则雨迹和复杂几何重叠时仍然面临挑战。单一范式架构难以有效整合全局-局部和空间-通道信息,因此需要一个统一的框架来克服这些困难。
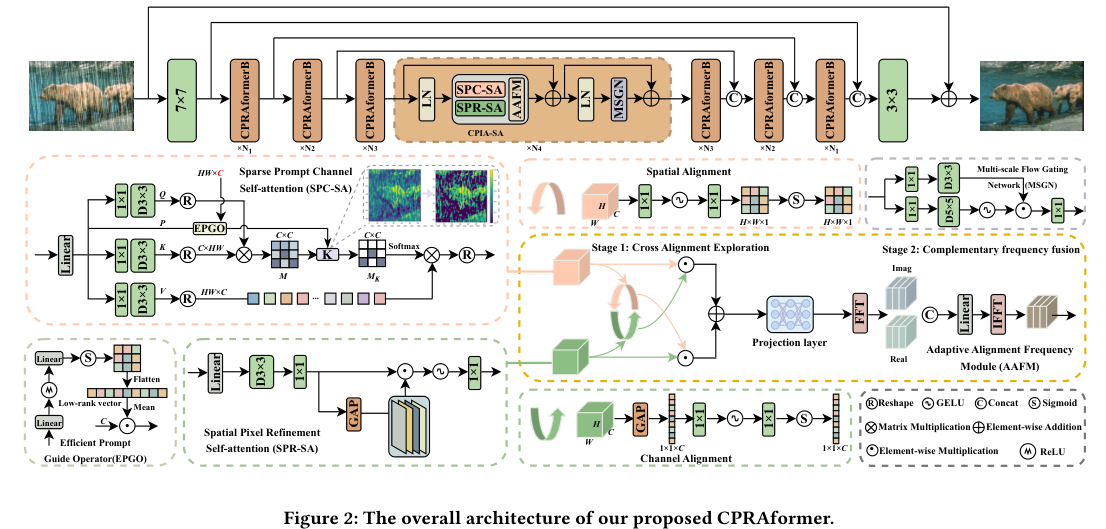
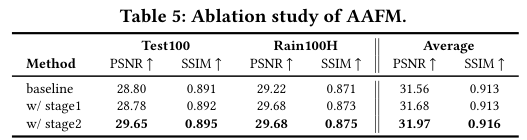
4)方法:为了解决这一问题,本文提出了CPRAformer,其核心思想是通过层次化表示和对齐,结合空间-通道和全局-局部两个范式的优势,促进图像的有效重建。具体方法包括:在Transformer模块中使用两种自注意力机制:稀疏提示通道自注意力(SPC-SA),增强全局通道依赖性,通过动态稀疏化来提升效果;空间像素精细化自注意力(SPR-SA),聚焦于空间雨迹分布和精细纹理恢复;引入自适应对齐频率模块(AAFM),通过两阶段渐进方式对特征进行对齐和交互,解决特征对齐和知识差异问题,实现自适应引导和互补。
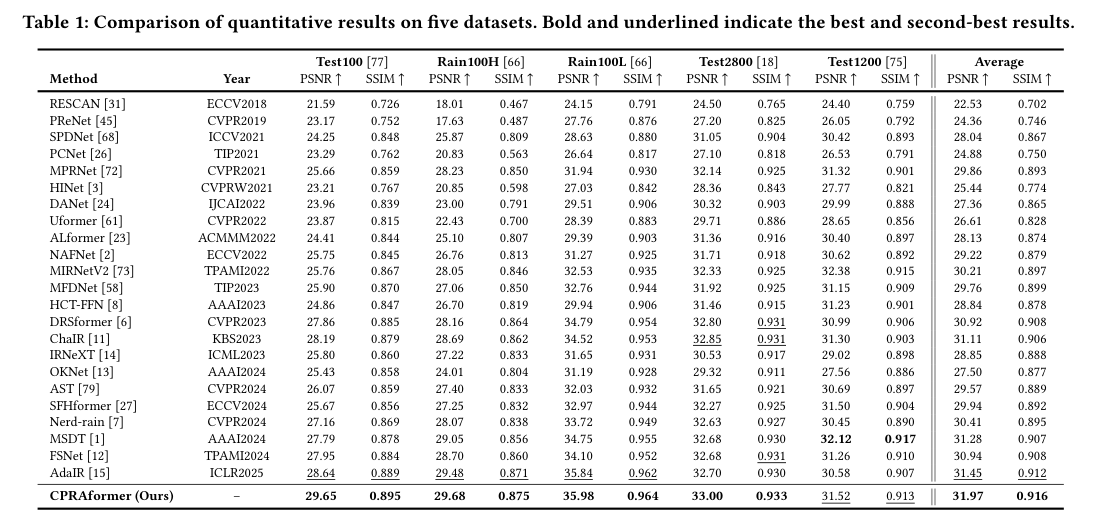
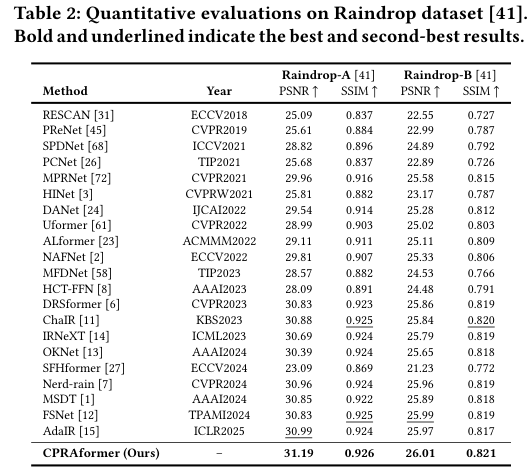
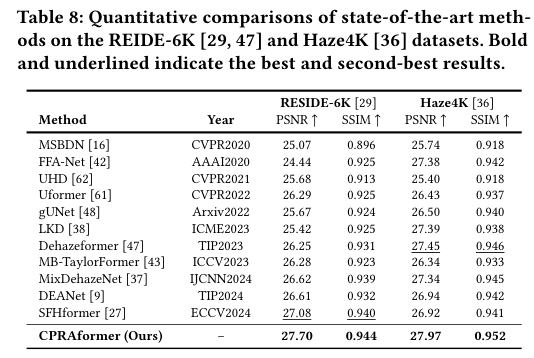
5)结果:大量实验表明,所提出的CPRAformer在八个基准数据集上达到了最先进的性能,并进一步验证了其在其他图像恢复任务及下游应用中的鲁棒性,展示了其在跨范式动态交互框架中的优势。




























 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











