







 本文探讨如何解读和获取股票交易明细数据,包括分时成交数据的含义和处理方法。此外,还介绍了Level2行情接口提供的十档行情快照,帮助读者深入理解股票市场的实时交易情况。
本文探讨如何解读和获取股票交易明细数据,包括分时成交数据的含义和处理方法。此外,还介绍了Level2行情接口提供的十档行情快照,帮助读者深入理解股票市场的实时交易情况。
今天的文章我们主要针对于股票日线级别的行情数据,介绍了一些获取和处理的方法,其实最原始的数据是交易明细数据,level2行情软件的各种周期和统计的数据都是通过明细数据跨周期转换而形成的,比如分钟K线、小时K线、当日成交量、成交额、外盘、内盘等各种指标。
本文我们主要介绍如何解读和获取股票交易明细数据,以及处理和转换交易明细数据的方法。
此处我们从普通行情软件中截取了某股某天的成交明细数据,我们看到成交明细中有时间、价格、现量和笔数四列数据,如下图所示:
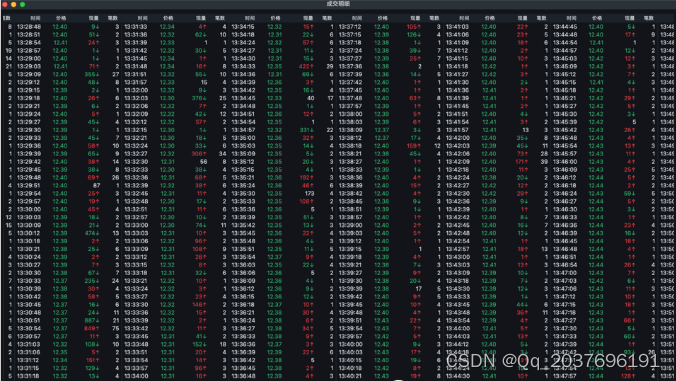
由于是免费行情软件,此处“成交明细”数据是以3-6秒间隔去记录的(不同软件可能有差异),表示在这个时间撮合的多笔单子的总和,因此确切地说是“分时成交”数据,即依据时间段为单位统计的结果,笔数这栏表示的是在这个周期内总共成交了几笔。
那么以上的普通行情软件只会显示买卖各五个价格,而一旦使用十档行情(深市千档),你将看到一般人看不见的买卖十档(深市千档)。为了方便大家理解小编就顺便说一下level2行情接口的十档行情!
- level2行情接口(十档行情快照)
| 字段名 |
类型 |
备注 |
| stock_exchange |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1956
1956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









