







读取表格问题
所读取的文档有注释
一般注释前面会用一个符号表示,如“#”,“!”等,read.table中一般默认“#”为注释符号,如果有其他的注释符号需要另外指定comment.char参数
gset = read.table(file = paste(path,'/','GSE_matrix.txt',sep = ''),
sep = '\t', comment.char="!", header = T, row.names= 1)
读取出错
1 read.table()
代码
GPL = read.table(file = 'D:/project/公共数据库/GPL/GPL.txt', sep = '\t', comment.char = '', header = T)
出错
Error in scan(file = file, what = what, sep = sep, quote = quote, dec = dec, :
line 1152 did not have 30 elements
解决:加入参数fill = TRUE
GPL = read.table(file = 'D:/project/公共数据库/GPL/GPL.txt', sep = '\t', comment.char = '', header = T,
fill = TRUE)
没办法读取完整表格
GPL = read.table(file = 'D:/project/公共数据库/GPL/GPL.txt', sep = '\t', comment.char = '', header = T,
fill = TRUE)
错误:行数不符,减少:原本GPL.txt有48109行,但是读取出来就只有20905行,没有找到合适的参数来整合
尝试挣扎:加入参数:nrows = 48109
GPL10558 = read.table(file = 'D:/project/公共数据库/GPL/GPL10558.txt', sep = '\t',
comment.char = '', header = T, nrows = 48107,fill = TRUE)
挣扎失败
解决:改用read_table,成功读取
library(readr)
GPL10558 = read_table(file = 'D:/project/公共数据库/GPL/GPL.txt')
ps:readr为大数据读取包,可能更适合数据量较大的文档。(以后处理数据的时候记得观察数据量的变化)
read_table分隔符是指定为固定空格的
(readr包内)read_table分隔符是指定为固定空格的,而read.table, 可以更改sep 参数改变分隔符
如果数据是用tab键(‘\t’)隔开的话, 一定不要不小心用了read_table,虽然也可以读取,但是会导致错行的现象发上(比如某些值本身是有空格的)如下图
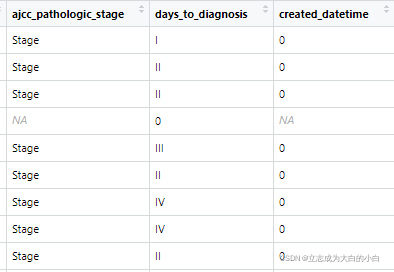
可以改用read_delim(), 通过delim参数设置
read_delim(file, delim = '\t')
画图问题
坐标轴显示特定刻度
比如涉及连续变量,比如时间,然后我们需要根据时间画某个变量的折现图,且我们需要在折线图的折点对应的时间在坐标轴上显示出来,这时候可以用到ggplot中的scale_x_continuous
ggplot(data = data1_1, mapping = aes(x = date, y = w)) +
geom_line() +
scale_x_continuous(breaks=unique(data1_1$date)) +
geom_point() +
theme_bw()
GEO数据库
多个探针对应1个基因
GEO数据库中存在多个探针对应1个基因的情况,这个时候根据需要作出取舍。看了其他大佬的帖子,主要有取最大值,取平均值,取中位数,或者只取对应的第一个探针的值。这里先暂且取最大值。
# 查看是否有重复的基因
table(duplicated(GENEID))
FALSE TRUE
34618 12705
有12705个重复,共有34618个基因
# 根据探针找symbol
GENEID = GPL[(match(rownames(gset), GPL$ID)), 'Symbol']
gset$GENEID = GENEID
gset = gset %>%
group_by(GENEID) %>%
summarise_all(max) %>%
filter(GENEID != '') #顺便把没有基因symbol的行去掉
TCGA 数据库
预后热图
一般的网页工具如GEPIA2所绘制的预后热图一般是根据中位数,或者四分位数划分因子的高低表达之后再作热图。还有一个方法:最小p值法,找最佳Cutoff值。而R包survminer中的surv_cutpoint就是根据最小p值法的原理来划分cutoff值。
library(survival)
library(survminer)
gene = "gene_name" #这是你基因表达的列名
res_cut = surv_cutpoint(data = ex_cli_p,
time = 'months', #生存时间
event = 'vital_status', #生存状态
variables = gene #需要计算的数据列名
)
summary(res_cut)
> summary(res_cut)
cutpoint statistic
GSDME 1.719954 1.412889
res_cat = surv_categorize(res_cut) #直接用这个函数划分为高低表达
> head(res_cat, 5)
months vital_status gene_name
TCGA-RZ-AB0B 4.966667 1 high
TCGA-V3-A9ZX 15.666667 0 high
TCGA-V3-A9ZY 15.300000 0 high
TCGA-V4-A9E5 83.300000 0 low
TCGA-V4-A9E7 13.833333 1 high
要注意这样划分之后,gene_name那一列之后跑预后分析,分级是:high在前,low在后

所以,后面画图什么的也需要注意legend标的时候不要标反了。以及如果想自己算HR,也要注意不要算反了
这里算高表达对于低表达的HR
#计算HR和p值
sdiff = survdiff(Surv(months, vital_status) ~ gene_name, data = res_cat)
p.val = 1 - pchisq(sdiff$chisq, length(sdiff$n) - 1)
HR = (sdiff$obs[1]/sdiff$exp[1])/(sdiff$obs[2]/sdiff$exp[2])
up95 = exp(log(HR) + qnorm(0.975)*sqrt(1/sdiff$exp[1]+1/sdiff$exp[2]))
low95 = exp(log(HR) - qnorm(0.975)*sqrt(1/sdiff$exp[1]+1/sdiff$exp[2]))
这是KM图
fit = survfit(Surv(months, vital_status) ~ gene_name, data = res_cat)#拟合生存分析
ggsurvplot(fit, title = '', legend = c(0.9,0.9),
palette = c('#E81D22', '#02B1e6'), #这里用蓝色代表地表达,红色代表高表达
legend.labs = c("high", "low"),
data = res_cat,
risk.table = TRUE,
pval = T, xlab = "", ylab = "")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









